搜索到
14
篇与
的结果
-
 Nacos配置管理、Feign远程调用、Gateway网关 SpringCloud实用篇020.学习目标1.Nacos配置管理Nacos除了可以做注册中心,同样可以做配置管理来使用。1.1.统一配置管理当微服务部署的实例越来越多,达到数十、数百时,逐个修改微服务配置就会让人抓狂,而且很容易出错。我们需要一种统一配置管理方案,可以集中管理所有实例的配置。Nacos一方面可以将配置集中管理,另一方可以在配置变更时,及时通知微服务,实现配置的热更新。1.1.1.在nacos中添加配置文件如何在nacos中管理配置呢?然后在弹出的表单中,填写配置信息:注意:项目的核心配置,需要热更新的配置才有放到nacos管理的必要。基本不会变更的一些配置还是保存在微服务本地比较好。1.1.2.从微服务拉取配置微服务要拉取nacos中管理的配置,并且与本地的application.yml配置合并,才能完成项目启动。但如果尚未读取application.yml,又如何得知nacos地址呢?因此spring引入了一种新的配置文件:bootstrap.yaml文件,会在application.yml之前被读取,流程如下:1)引入nacos-config依赖首先,在user-service服务中,引入nacos-config的客户端依赖:<!--nacos配置管理依赖--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency>2)添加bootstrap.yaml然后,在user-service中添加一个bootstrap.yaml文件,内容如下:spring: application: name: userservice # 服务名称 profiles: active: dev #开发环境,这里是dev cloud: nacos: server-addr: localhost:8848 # Nacos地址 config: file-extension: yaml # 文件后缀名这里会根据spring.cloud.nacos.server-addr获取nacos地址,再根据${spring.application.name}-${spring.profiles.active}.${spring.cloud.nacos.config.file-extension}作为文件id,来读取配置。本例中,就是去读取userservice-dev.yaml:3)读取nacos配置在user-service中的UserController中添加业务逻辑,读取pattern.dateformat配置:完整代码:package cn.itcast.user.web; import cn.itcast.user.pojo.User; import cn.itcast.user.service.UserService; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.beans.factory.annotation.Value; import org.springframework.web.bind.annotation.*; import java.time.LocalDateTime; import java.time.format.DateTimeFormatter; @Slf4j @RestController @RequestMapping("/user") public class UserController { @Autowired private UserService userService; @Value("${pattern.dateformat}") private String dateformat; @GetMapping("now") public String now(){ return LocalDateTime.now().format(DateTimeFormatter.ofPattern(dateformat)); } // ...略 }在页面访问,可以看到效果:1.2.配置热更新我们最终的目的,是修改nacos中的配置后,微服务中无需重启即可让配置生效,也就是配置热更新。要实现配置热更新,可以使用两种方式:1.2.1.方式一在@Value注入的变量所在类上添加注解@RefreshScope:1.2.2.方式二使用@ConfigurationProperties注解代替@Value注解。在user-service服务中,添加一个类,读取patterrn.dateformat属性:package cn.itcast.user.config; import lombok.Data; import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.stereotype.Component; @Component @Data @ConfigurationProperties(prefix = "pattern") public class PatternProperties { private String dateformat; }在UserController中使用这个类代替@Value:完整代码:package cn.itcast.user.web; import cn.itcast.user.config.PatternProperties; import cn.itcast.user.pojo.User; import cn.itcast.user.service.UserService; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.PathVariable; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import java.time.LocalDateTime; import java.time.format.DateTimeFormatter; @Slf4j @RestController @RequestMapping("/user") public class UserController { @Autowired private UserService userService; @Autowired private PatternProperties patternProperties; @GetMapping("now") public String now(){ return LocalDateTime.now().format(DateTimeFormatter.ofPattern(patternProperties.getDateformat())); } // 略 }1.3.配置共享其实微服务启动时,会去nacos读取多个配置文件,例如:[spring.application.name]-[spring.profiles.active].yaml,例如:userservice-dev.yaml[spring.application.name].yaml,例如:userservice.yaml而[spring.application.name].yaml不包含环境,因此可以被多个环境共享。下面我们通过案例来测试配置共享1)添加一个环境共享配置我们在nacos中添加一个userservice.yaml文件:2)在user-service中读取共享配置在user-service服务中,修改PatternProperties类,读取新添加的属性:在user-service服务中,修改UserController,添加一个方法:3)运行两个UserApplication,使用不同的profile修改UserApplication2这个启动项,改变其profile值:这样,UserApplication(8081)使用的profile是dev,UserApplication2(8082)使用的profile是test。启动UserApplication和UserApplication2访问http://localhost:8081/user/prop,结果:访问http://localhost:8082/user/prop,结果:可以看出来,不管是dev,还是test环境,都读取到了envSharedValue这个属性的值。4)配置共享的优先级当nacos、服务本地同时出现相同属性时,优先级有高低之分:1.4.搭建Nacos集群Nacos生产环境下一定要部署为集群状态,部署方式参考课前资料中的文档:2.Feign远程调用先来看我们以前利用RestTemplate发起远程调用的代码:存在下面的问题:•代码可读性差,编程体验不统一•参数复杂URL难以维护Feign是一个声明式的http客户端,官方地址:https://github.com/OpenFeign/feign其作用就是帮助我们优雅的实现http请求的发送,解决上面提到的问题。2.1.Feign替代RestTemplateFegin的使用步骤如下:1)引入依赖我们在order-service服务的pom文件中引入feign的依赖:<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency>2)添加注解在order-service的启动类添加注解开启Feign的功能:3)编写Feign的客户端在order-service中新建一个接口,内容如下:package cn.itcast.order.client; import cn.itcast.order.pojo.User; import org.springframework.cloud.openfeign.FeignClient; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.PathVariable; @FeignClient("userservice") public interface UserClient { @GetMapping("/user/{id}") User findById(@PathVariable("id") Long id); }这个客户端主要是基于SpringMVC的注解来声明远程调用的信息,比如:服务名称:userservice请求方式:GET请求路径:/user/{id}请求参数:Long id返回值类型:User这样,Feign就可以帮助我们发送http请求,无需自己使用RestTemplate来发送了。4)测试修改order-service中的OrderService类中的queryOrderById方法,使用Feign客户端代替RestTemplate:是不是看起来优雅多了。5)总结使用Feign的步骤:① 引入依赖② 添加@EnableFeignClients注解③ 编写FeignClient接口④ 使用FeignClient中定义的方法代替RestTemplate2.2.自定义配置Feign可以支持很多的自定义配置,如下表所示:类型作用说明feign.Logger.Level修改日志级别包含四种不同的级别:NONE、BASIC、HEADERS、FULLfeign.codec.Decoder响应结果的解析器http远程调用的结果做解析,例如解析json字符串为java对象feign.codec.Encoder请求参数编码将请求参数编码,便于通过http请求发送feign. Contract支持的注解格式默认是SpringMVC的注解feign. Retryer失败重试机制请求失败的重试机制,默认是没有,不过会使用Ribbon的重试一般情况下,默认值就能满足我们使用,如果要自定义时,只需要创建自定义的@Bean覆盖默认Bean即可。下面以日志为例来演示如何自定义配置。2.2.1.配置文件方式基于配置文件修改feign的日志级别可以针对单个服务:feign: client: config: userservice: # 针对某个微服务的配置 loggerLevel: FULL # 日志级别 也可以针对所有服务:feign: client: config: default: # 这里用default就是全局配置,如果是写服务名称,则是针对某个微服务的配置 loggerLevel: FULL # 日志级别 而日志的级别分为四种:NONE:不记录任何日志信息,这是默认值。BASIC:仅记录请求的方法,URL以及响应状态码和执行时间HEADERS:在BASIC的基础上,额外记录了请求和响应的头信息FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据。2.2.2.Java代码方式也可以基于Java代码来修改日志级别,先声明一个类,然后声明一个Logger.Level的对象:public class DefaultFeignConfiguration { @Bean public Logger.Level feignLogLevel(){ return Logger.Level.BASIC; // 日志级别为BASIC } }如果要全局生效,将其放到启动类的@EnableFeignClients这个注解中:@EnableFeignClients(defaultConfiguration = DefaultFeignConfiguration .class) 如果是局部生效,则把它放到对应的@FeignClient这个注解中:@FeignClient(value = "userservice", configuration = DefaultFeignConfiguration .class) 2.3.Feign使用优化Feign底层发起http请求,依赖于其它的框架。其底层客户端实现包括:•URLConnection:默认实现,不支持连接池•Apache HttpClient :支持连接池•OKHttp:支持连接池因此提高Feign的性能主要手段就是使用连接池代替默认的URLConnection。这里我们用Apache的HttpClient来演示。1)引入依赖在order-service的pom文件中引入Apache的HttpClient依赖:<!--httpClient的依赖 --> <dependency> <groupId>io.github.openfeign</groupId> <artifactId>feign-httpclient</artifactId> </dependency>2)配置连接池在order-service的application.yml中添加配置:feign: client: config: default: # default全局的配置 loggerLevel: BASIC # 日志级别,BASIC就是基本的请求和响应信息 httpclient: enabled: true # 开启feign对HttpClient的支持 max-connections: 200 # 最大的连接数 max-connections-per-route: 50 # 每个路径的最大连接数接下来,在FeignClientFactoryBean中的loadBalance方法中打断点:Debug方式启动order-service服务,可以看到这里的client,底层就是Apache HttpClient:总结,Feign的优化:1.日志级别尽量用basic2.使用HttpClient或OKHttp代替URLConnection① 引入feign-httpClient依赖② 配置文件开启httpClient功能,设置连接池参数2.4.最佳实践所谓最近实践,就是使用过程中总结的经验,最好的一种使用方式。自习观察可以发现,Feign的客户端与服务提供者的controller代码非常相似:feign客户端:UserController:有没有一种办法简化这种重复的代码编写呢?2.4.1.继承方式一样的代码可以通过继承来共享:1)定义一个API接口,利用定义方法,并基于SpringMVC注解做声明。2)Feign客户端和Controller都集成改接口优点:简单实现了代码共享缺点:服务提供方、服务消费方紧耦合参数列表中的注解映射并不会继承,因此Controller中必须再次声明方法、参数列表、注解2.4.2.抽取方式将Feign的Client抽取为独立模块,并且把接口有关的POJO、默认的Feign配置都放到这个模块中,提供给所有消费者使用。例如,将UserClient、User、Feign的默认配置都抽取到一个feign-api包中,所有微服务引用该依赖包,即可直接使用。2.4.3.实现基于抽取的最佳实践1)抽取首先创建一个module,命名为feign-api:项目结构:在feign-api中然后引入feign的starter依赖<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency>然后,order-service中编写的UserClient、User、DefaultFeignConfiguration都复制到feign-api项目中2)在order-service中使用feign-api首先,删除order-service中的UserClient、User、DefaultFeignConfiguration等类或接口。在order-service的pom文件中中引入feign-api的依赖:<dependency> <groupId>cn.itcast.demo</groupId> <artifactId>feign-api</artifactId> <version>1.0</version> </dependency>修改order-service中的所有与上述三个组件有关的导包部分,改成导入feign-api中的包3)重启测试重启后,发现服务报错了:这是因为UserClient现在在cn.itcast.feign.clients包下,而order-service的@EnableFeignClients注解是在cn.itcast.order包下,不在同一个包,无法扫描到UserClient。4)解决扫描包问题方式一:指定Feign应该扫描的包:@EnableFeignClients(basePackages = "cn.itcast.feign.clients")方式二:指定需要加载的Client接口:@EnableFeignClients(clients = {UserClient.class})3.Gateway服务网关Spring Cloud Gateway 是 Spring Cloud 的一个全新项目,该项目是基于 Spring 5.0,Spring Boot 2.0 和 Project Reactor 等响应式编程和事件流技术开发的网关,它旨在为微服务架构提供一种简单有效的统一的 API 路由管理方式。3.1.为什么需要网关Gateway网关是我们服务的守门神,所有微服务的统一入口。网关的核心功能特性:请求路由权限控制限流架构图:权限控制:网关作为微服务入口,需要校验用户是是否有请求资格,如果没有则进行拦截。路由和负载均衡:一切请求都必须先经过gateway,但网关不处理业务,而是根据某种规则,把请求转发到某个微服务,这个过程叫做路由。当然路由的目标服务有多个时,还需要做负载均衡。限流:当请求流量过高时,在网关中按照下流的微服务能够接受的速度来放行请求,避免服务压力过大。在SpringCloud中网关的实现包括两种:gatewayzuulZuul是基于Servlet的实现,属于阻塞式编程。而SpringCloudGateway则是基于Spring5中提供的WebFlux,属于响应式编程的实现,具备更好的性能。3.2.gateway快速入门下面,我们就演示下网关的基本路由功能。基本步骤如下:创建SpringBoot工程gateway,引入网关依赖编写启动类编写基础配置和路由规则启动网关服务进行测试1)创建gateway服务,引入依赖创建服务:引入依赖:<!--网关--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> </dependency> <!--nacos服务发现依赖--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency>2)编写启动类package cn.itcast.gateway; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class GatewayApplication { public static void main(String[] args) { SpringApplication.run(GatewayApplication.class, args); } }3)编写基础配置和路由规则创建application.yml文件,内容如下:server: port: 10010 # 网关端口 spring: application: name: gateway # 服务名称 cloud: nacos: server-addr: localhost:8848 # nacos地址 gateway: routes: # 网关路由配置 - id: user-service # 路由id,自定义,只要唯一即可 # uri: http://127.0.0.1:8081 # 路由的目标地址 http就是固定地址 uri: lb://userservice # 路由的目标地址 lb就是负载均衡,后面跟服务名称 predicates: # 路由断言,也就是判断请求是否符合路由规则的条件 - Path=/user/** # 这个是按照路径匹配,只要以/user/开头就符合要求我们将符合Path 规则的一切请求,都代理到 uri参数指定的地址。本例中,我们将 /user/**开头的请求,代理到lb://userservice,lb是负载均衡,根据服务名拉取服务列表,实现负载均衡。4)重启测试重启网关,访问http://localhost:10010/user/1时,符合/user/**规则,请求转发到uri:http://userservice/user/1,得到了结果:5)网关路由的流程图整个访问的流程如下:总结:网关搭建步骤:创建项目,引入nacos服务发现和gateway依赖配置application.yml,包括服务基本信息、nacos地址、路由路由配置包括:路由id:路由的唯一标示路由目标(uri):路由的目标地址,http代表固定地址,lb代表根据服务名负载均衡路由断言(predicates):判断路由的规则,路由过滤器(filters):对请求或响应做处理接下来,就重点来学习路由断言和路由过滤器的详细知识3.3.断言工厂我们在配置文件中写的断言规则只是字符串,这些字符串会被Predicate Factory读取并处理,转变为路由判断的条件例如Path=/user/**是按照路径匹配,这个规则是由org.springframework.cloud.gateway.handler.predicate.PathRoutePredicateFactory类来处理的,像这样的断言工厂在SpringCloudGateway还有十几个:名称说明示例After是某个时间点后的请求- After=2037-01-20T17:42:47.789-07:00[America/Denver]Before是某个时间点之前的请求- Before=2031-04-13T15:14:47.433+08:00[Asia/Shanghai]Between是某两个时间点之前的请求- Between=2037-01-20T17:42:47.789-07:00[America/Denver], 2037-01-21T17:42:47.789-07:00[America/Denver]Cookie请求必须包含某些cookie- Cookie=chocolate, ch.pHeader请求必须包含某些header- Header=X-Request-Id, \d+Host请求必须是访问某个host(域名)- Host=.somehost.org,.anotherhost.orgMethod请求方式必须是指定方式- Method=GET,POSTPath请求路径必须符合指定规则- Path=/red/{segment},/blue/**Query请求参数必须包含指定参数- Query=name, Jack或者- Query=nameRemoteAddr请求者的ip必须是指定范围- RemoteAddr=192.168.1.1/24Weight权重处理 我们只需要掌握Path这种路由工程就可以了。3.4.过滤器工厂GatewayFilter是网关中提供的一种过滤器,可以对进入网关的请求和微服务返回的响应做处理:3.4.1.路由过滤器的种类Spring提供了31种不同的路由过滤器工厂。例如:名称说明AddRequestHeader给当前请求添加一个请求头RemoveRequestHeader移除请求中的一个请求头AddResponseHeader给响应结果中添加一个响应头RemoveResponseHeader从响应结果中移除有一个响应头RequestRateLimiter限制请求的流量3.4.2.请求头过滤器下面我们以AddRequestHeader 为例来讲解。需求:给所有进入userservice的请求添加一个请求头:Truth=itcast is freaking awesome!只需要修改gateway服务的application.yml文件,添加路由过滤即可:spring: cloud: gateway: routes: - id: user-service uri: lb://userservice predicates: - Path=/user/** filters: # 过滤器 - AddRequestHeader=Truth, Itcast is freaking awesome! # 添加请求头当前过滤器写在userservice路由下,因此仅仅对访问userservice的请求有效。3.4.3.默认过滤器如果要对所有的路由都生效,则可以将过滤器工厂写到default下。格式如下:spring: cloud: gateway: routes: - id: user-service uri: lb://userservice predicates: - Path=/user/** default-filters: # 默认过滤项 - AddRequestHeader=Truth, Itcast is freaking awesome! 3.4.4.总结过滤器的作用是什么?① 对路由的请求或响应做加工处理,比如添加请求头② 配置在路由下的过滤器只对当前路由的请求生效defaultFilters的作用是什么?① 对所有路由都生效的过滤器3.5.全局过滤器上一节学习的过滤器,网关提供了31种,但每一种过滤器的作用都是固定的。如果我们希望拦截请求,做自己的业务逻辑则没办法实现。3.5.1.全局过滤器作用全局过滤器的作用也是处理一切进入网关的请求和微服务响应,与GatewayFilter的作用一样。区别在于GatewayFilter通过配置定义,处理逻辑是固定的;而GlobalFilter的逻辑需要自己写代码实现。定义方式是实现GlobalFilter接口。public interface GlobalFilter { /** * 处理当前请求,有必要的话通过{@link GatewayFilterChain}将请求交给下一个过滤器处理 * * @param exchange 请求上下文,里面可以获取Request、Response等信息 * @param chain 用来把请求委托给下一个过滤器 * @return {@code Mono<Void>} 返回标示当前过滤器业务结束 */ Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain); }在filter中编写自定义逻辑,可以实现下列功能:登录状态判断权限校验请求限流等3.5.2.自定义全局过滤器需求:定义全局过滤器,拦截请求,判断请求的参数是否满足下面条件:参数中是否有authorization,authorization参数值是否为admin如果同时满足则放行,否则拦截实现:在gateway中定义一个过滤器:package cn.itcast.gateway.filters; import org.springframework.cloud.gateway.filter.GatewayFilterChain; import org.springframework.cloud.gateway.filter.GlobalFilter; import org.springframework.core.annotation.Order; import org.springframework.http.HttpStatus; import org.springframework.stereotype.Component; import org.springframework.web.server.ServerWebExchange; import reactor.core.publisher.Mono; @Order(-1) @Component public class AuthorizeFilter implements GlobalFilter { @Override public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { // 1.获取请求参数 MultiValueMap<String, String> params = exchange.getRequest().getQueryParams(); // 2.获取authorization参数 String auth = params.getFirst("authorization"); // 3.校验 if ("admin".equals(auth)) { // 放行 return chain.filter(exchange); } // 4.拦截 // 4.1.禁止访问,设置状态码 exchange.getResponse().setStatusCode(HttpStatus.FORBIDDEN); // 4.2.结束处理 return exchange.getResponse().setComplete(); } }3.5.3.过滤器执行顺序请求进入网关会碰到三类过滤器:当前路由的过滤器、DefaultFilter、GlobalFilter请求路由后,会将当前路由过滤器和DefaultFilter、GlobalFilter,合并到一个过滤器链(集合)中,排序后依次执行每个过滤器:排序的规则是什么呢?每一个过滤器都必须指定一个int类型的order值,order值越小,优先级越高,执行顺序越靠前。GlobalFilter通过实现Ordered接口,或者添加@Order注解来指定order值,由我们自己指定路由过滤器和defaultFilter的order由Spring指定,默认是按照声明顺序从1递增。当过滤器的order值一样时,会按照 defaultFilter > 路由过滤器 > GlobalFilter的顺序执行。详细内容,可以查看源码:org.springframework.cloud.gateway.route.RouteDefinitionRouteLocator#getFilters()方法是先加载defaultFilters,然后再加载某个route的filters,然后合并。org.springframework.cloud.gateway.handler.FilteringWebHandler#handle()方法会加载全局过滤器,与前面的过滤器合并后根据order排序,组织过滤器链3.6.跨域问题3.6.1.什么是跨域问题跨域:域名不一致就是跨域,主要包括:域名不同: www.taobao.com 和 www.taobao.org 和 www.jd.com 和 miaosha.jd.com域名相同,端口不同:localhost:8080和localhost8081跨域问题:浏览器禁止请求的发起者与服务端发生跨域ajax请求,请求被浏览器拦截的问题解决方案:CORS,这个以前应该学习过,这里不再赘述了。不知道的小伙伴可以查看https://www.ruanyifeng.com/blog/2016/04/cors.html3.6.2.模拟跨域问题找到课前资料的页面文件:放入tomcat或者nginx这样的web服务器中,启动并访问。可以在浏览器控制台看到下面的错误:从localhost:8090访问localhost:10010,端口不同,显然是跨域的请求。3.6.3.解决跨域问题在gateway服务的application.yml文件中,添加下面的配置:spring: cloud: gateway: # 。。。 globalcors: # 全局的跨域处理 add-to-simple-url-handler-mapping: true # 解决options请求被拦截问题 corsConfigurations: '[/**]': allowedOrigins: # 允许哪些网站的跨域请求 - "http://localhost:8090" allowedMethods: # 允许的跨域ajax的请求方式 - "GET" - "POST" - "DELETE" - "PUT" - "OPTIONS" allowedHeaders: "*" # 允许在请求中携带的头信息 allowCredentials: true # 是否允许携带cookie maxAge: 360000 # 这次跨域检测的有效期
Nacos配置管理、Feign远程调用、Gateway网关 SpringCloud实用篇020.学习目标1.Nacos配置管理Nacos除了可以做注册中心,同样可以做配置管理来使用。1.1.统一配置管理当微服务部署的实例越来越多,达到数十、数百时,逐个修改微服务配置就会让人抓狂,而且很容易出错。我们需要一种统一配置管理方案,可以集中管理所有实例的配置。Nacos一方面可以将配置集中管理,另一方可以在配置变更时,及时通知微服务,实现配置的热更新。1.1.1.在nacos中添加配置文件如何在nacos中管理配置呢?然后在弹出的表单中,填写配置信息:注意:项目的核心配置,需要热更新的配置才有放到nacos管理的必要。基本不会变更的一些配置还是保存在微服务本地比较好。1.1.2.从微服务拉取配置微服务要拉取nacos中管理的配置,并且与本地的application.yml配置合并,才能完成项目启动。但如果尚未读取application.yml,又如何得知nacos地址呢?因此spring引入了一种新的配置文件:bootstrap.yaml文件,会在application.yml之前被读取,流程如下:1)引入nacos-config依赖首先,在user-service服务中,引入nacos-config的客户端依赖:<!--nacos配置管理依赖--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency>2)添加bootstrap.yaml然后,在user-service中添加一个bootstrap.yaml文件,内容如下:spring: application: name: userservice # 服务名称 profiles: active: dev #开发环境,这里是dev cloud: nacos: server-addr: localhost:8848 # Nacos地址 config: file-extension: yaml # 文件后缀名这里会根据spring.cloud.nacos.server-addr获取nacos地址,再根据${spring.application.name}-${spring.profiles.active}.${spring.cloud.nacos.config.file-extension}作为文件id,来读取配置。本例中,就是去读取userservice-dev.yaml:3)读取nacos配置在user-service中的UserController中添加业务逻辑,读取pattern.dateformat配置:完整代码:package cn.itcast.user.web; import cn.itcast.user.pojo.User; import cn.itcast.user.service.UserService; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.beans.factory.annotation.Value; import org.springframework.web.bind.annotation.*; import java.time.LocalDateTime; import java.time.format.DateTimeFormatter; @Slf4j @RestController @RequestMapping("/user") public class UserController { @Autowired private UserService userService; @Value("${pattern.dateformat}") private String dateformat; @GetMapping("now") public String now(){ return LocalDateTime.now().format(DateTimeFormatter.ofPattern(dateformat)); } // ...略 }在页面访问,可以看到效果:1.2.配置热更新我们最终的目的,是修改nacos中的配置后,微服务中无需重启即可让配置生效,也就是配置热更新。要实现配置热更新,可以使用两种方式:1.2.1.方式一在@Value注入的变量所在类上添加注解@RefreshScope:1.2.2.方式二使用@ConfigurationProperties注解代替@Value注解。在user-service服务中,添加一个类,读取patterrn.dateformat属性:package cn.itcast.user.config; import lombok.Data; import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.stereotype.Component; @Component @Data @ConfigurationProperties(prefix = "pattern") public class PatternProperties { private String dateformat; }在UserController中使用这个类代替@Value:完整代码:package cn.itcast.user.web; import cn.itcast.user.config.PatternProperties; import cn.itcast.user.pojo.User; import cn.itcast.user.service.UserService; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.PathVariable; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import java.time.LocalDateTime; import java.time.format.DateTimeFormatter; @Slf4j @RestController @RequestMapping("/user") public class UserController { @Autowired private UserService userService; @Autowired private PatternProperties patternProperties; @GetMapping("now") public String now(){ return LocalDateTime.now().format(DateTimeFormatter.ofPattern(patternProperties.getDateformat())); } // 略 }1.3.配置共享其实微服务启动时,会去nacos读取多个配置文件,例如:[spring.application.name]-[spring.profiles.active].yaml,例如:userservice-dev.yaml[spring.application.name].yaml,例如:userservice.yaml而[spring.application.name].yaml不包含环境,因此可以被多个环境共享。下面我们通过案例来测试配置共享1)添加一个环境共享配置我们在nacos中添加一个userservice.yaml文件:2)在user-service中读取共享配置在user-service服务中,修改PatternProperties类,读取新添加的属性:在user-service服务中,修改UserController,添加一个方法:3)运行两个UserApplication,使用不同的profile修改UserApplication2这个启动项,改变其profile值:这样,UserApplication(8081)使用的profile是dev,UserApplication2(8082)使用的profile是test。启动UserApplication和UserApplication2访问http://localhost:8081/user/prop,结果:访问http://localhost:8082/user/prop,结果:可以看出来,不管是dev,还是test环境,都读取到了envSharedValue这个属性的值。4)配置共享的优先级当nacos、服务本地同时出现相同属性时,优先级有高低之分:1.4.搭建Nacos集群Nacos生产环境下一定要部署为集群状态,部署方式参考课前资料中的文档:2.Feign远程调用先来看我们以前利用RestTemplate发起远程调用的代码:存在下面的问题:•代码可读性差,编程体验不统一•参数复杂URL难以维护Feign是一个声明式的http客户端,官方地址:https://github.com/OpenFeign/feign其作用就是帮助我们优雅的实现http请求的发送,解决上面提到的问题。2.1.Feign替代RestTemplateFegin的使用步骤如下:1)引入依赖我们在order-service服务的pom文件中引入feign的依赖:<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency>2)添加注解在order-service的启动类添加注解开启Feign的功能:3)编写Feign的客户端在order-service中新建一个接口,内容如下:package cn.itcast.order.client; import cn.itcast.order.pojo.User; import org.springframework.cloud.openfeign.FeignClient; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.PathVariable; @FeignClient("userservice") public interface UserClient { @GetMapping("/user/{id}") User findById(@PathVariable("id") Long id); }这个客户端主要是基于SpringMVC的注解来声明远程调用的信息,比如:服务名称:userservice请求方式:GET请求路径:/user/{id}请求参数:Long id返回值类型:User这样,Feign就可以帮助我们发送http请求,无需自己使用RestTemplate来发送了。4)测试修改order-service中的OrderService类中的queryOrderById方法,使用Feign客户端代替RestTemplate:是不是看起来优雅多了。5)总结使用Feign的步骤:① 引入依赖② 添加@EnableFeignClients注解③ 编写FeignClient接口④ 使用FeignClient中定义的方法代替RestTemplate2.2.自定义配置Feign可以支持很多的自定义配置,如下表所示:类型作用说明feign.Logger.Level修改日志级别包含四种不同的级别:NONE、BASIC、HEADERS、FULLfeign.codec.Decoder响应结果的解析器http远程调用的结果做解析,例如解析json字符串为java对象feign.codec.Encoder请求参数编码将请求参数编码,便于通过http请求发送feign. Contract支持的注解格式默认是SpringMVC的注解feign. Retryer失败重试机制请求失败的重试机制,默认是没有,不过会使用Ribbon的重试一般情况下,默认值就能满足我们使用,如果要自定义时,只需要创建自定义的@Bean覆盖默认Bean即可。下面以日志为例来演示如何自定义配置。2.2.1.配置文件方式基于配置文件修改feign的日志级别可以针对单个服务:feign: client: config: userservice: # 针对某个微服务的配置 loggerLevel: FULL # 日志级别 也可以针对所有服务:feign: client: config: default: # 这里用default就是全局配置,如果是写服务名称,则是针对某个微服务的配置 loggerLevel: FULL # 日志级别 而日志的级别分为四种:NONE:不记录任何日志信息,这是默认值。BASIC:仅记录请求的方法,URL以及响应状态码和执行时间HEADERS:在BASIC的基础上,额外记录了请求和响应的头信息FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据。2.2.2.Java代码方式也可以基于Java代码来修改日志级别,先声明一个类,然后声明一个Logger.Level的对象:public class DefaultFeignConfiguration { @Bean public Logger.Level feignLogLevel(){ return Logger.Level.BASIC; // 日志级别为BASIC } }如果要全局生效,将其放到启动类的@EnableFeignClients这个注解中:@EnableFeignClients(defaultConfiguration = DefaultFeignConfiguration .class) 如果是局部生效,则把它放到对应的@FeignClient这个注解中:@FeignClient(value = "userservice", configuration = DefaultFeignConfiguration .class) 2.3.Feign使用优化Feign底层发起http请求,依赖于其它的框架。其底层客户端实现包括:•URLConnection:默认实现,不支持连接池•Apache HttpClient :支持连接池•OKHttp:支持连接池因此提高Feign的性能主要手段就是使用连接池代替默认的URLConnection。这里我们用Apache的HttpClient来演示。1)引入依赖在order-service的pom文件中引入Apache的HttpClient依赖:<!--httpClient的依赖 --> <dependency> <groupId>io.github.openfeign</groupId> <artifactId>feign-httpclient</artifactId> </dependency>2)配置连接池在order-service的application.yml中添加配置:feign: client: config: default: # default全局的配置 loggerLevel: BASIC # 日志级别,BASIC就是基本的请求和响应信息 httpclient: enabled: true # 开启feign对HttpClient的支持 max-connections: 200 # 最大的连接数 max-connections-per-route: 50 # 每个路径的最大连接数接下来,在FeignClientFactoryBean中的loadBalance方法中打断点:Debug方式启动order-service服务,可以看到这里的client,底层就是Apache HttpClient:总结,Feign的优化:1.日志级别尽量用basic2.使用HttpClient或OKHttp代替URLConnection① 引入feign-httpClient依赖② 配置文件开启httpClient功能,设置连接池参数2.4.最佳实践所谓最近实践,就是使用过程中总结的经验,最好的一种使用方式。自习观察可以发现,Feign的客户端与服务提供者的controller代码非常相似:feign客户端:UserController:有没有一种办法简化这种重复的代码编写呢?2.4.1.继承方式一样的代码可以通过继承来共享:1)定义一个API接口,利用定义方法,并基于SpringMVC注解做声明。2)Feign客户端和Controller都集成改接口优点:简单实现了代码共享缺点:服务提供方、服务消费方紧耦合参数列表中的注解映射并不会继承,因此Controller中必须再次声明方法、参数列表、注解2.4.2.抽取方式将Feign的Client抽取为独立模块,并且把接口有关的POJO、默认的Feign配置都放到这个模块中,提供给所有消费者使用。例如,将UserClient、User、Feign的默认配置都抽取到一个feign-api包中,所有微服务引用该依赖包,即可直接使用。2.4.3.实现基于抽取的最佳实践1)抽取首先创建一个module,命名为feign-api:项目结构:在feign-api中然后引入feign的starter依赖<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency>然后,order-service中编写的UserClient、User、DefaultFeignConfiguration都复制到feign-api项目中2)在order-service中使用feign-api首先,删除order-service中的UserClient、User、DefaultFeignConfiguration等类或接口。在order-service的pom文件中中引入feign-api的依赖:<dependency> <groupId>cn.itcast.demo</groupId> <artifactId>feign-api</artifactId> <version>1.0</version> </dependency>修改order-service中的所有与上述三个组件有关的导包部分,改成导入feign-api中的包3)重启测试重启后,发现服务报错了:这是因为UserClient现在在cn.itcast.feign.clients包下,而order-service的@EnableFeignClients注解是在cn.itcast.order包下,不在同一个包,无法扫描到UserClient。4)解决扫描包问题方式一:指定Feign应该扫描的包:@EnableFeignClients(basePackages = "cn.itcast.feign.clients")方式二:指定需要加载的Client接口:@EnableFeignClients(clients = {UserClient.class})3.Gateway服务网关Spring Cloud Gateway 是 Spring Cloud 的一个全新项目,该项目是基于 Spring 5.0,Spring Boot 2.0 和 Project Reactor 等响应式编程和事件流技术开发的网关,它旨在为微服务架构提供一种简单有效的统一的 API 路由管理方式。3.1.为什么需要网关Gateway网关是我们服务的守门神,所有微服务的统一入口。网关的核心功能特性:请求路由权限控制限流架构图:权限控制:网关作为微服务入口,需要校验用户是是否有请求资格,如果没有则进行拦截。路由和负载均衡:一切请求都必须先经过gateway,但网关不处理业务,而是根据某种规则,把请求转发到某个微服务,这个过程叫做路由。当然路由的目标服务有多个时,还需要做负载均衡。限流:当请求流量过高时,在网关中按照下流的微服务能够接受的速度来放行请求,避免服务压力过大。在SpringCloud中网关的实现包括两种:gatewayzuulZuul是基于Servlet的实现,属于阻塞式编程。而SpringCloudGateway则是基于Spring5中提供的WebFlux,属于响应式编程的实现,具备更好的性能。3.2.gateway快速入门下面,我们就演示下网关的基本路由功能。基本步骤如下:创建SpringBoot工程gateway,引入网关依赖编写启动类编写基础配置和路由规则启动网关服务进行测试1)创建gateway服务,引入依赖创建服务:引入依赖:<!--网关--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> </dependency> <!--nacos服务发现依赖--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency>2)编写启动类package cn.itcast.gateway; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class GatewayApplication { public static void main(String[] args) { SpringApplication.run(GatewayApplication.class, args); } }3)编写基础配置和路由规则创建application.yml文件,内容如下:server: port: 10010 # 网关端口 spring: application: name: gateway # 服务名称 cloud: nacos: server-addr: localhost:8848 # nacos地址 gateway: routes: # 网关路由配置 - id: user-service # 路由id,自定义,只要唯一即可 # uri: http://127.0.0.1:8081 # 路由的目标地址 http就是固定地址 uri: lb://userservice # 路由的目标地址 lb就是负载均衡,后面跟服务名称 predicates: # 路由断言,也就是判断请求是否符合路由规则的条件 - Path=/user/** # 这个是按照路径匹配,只要以/user/开头就符合要求我们将符合Path 规则的一切请求,都代理到 uri参数指定的地址。本例中,我们将 /user/**开头的请求,代理到lb://userservice,lb是负载均衡,根据服务名拉取服务列表,实现负载均衡。4)重启测试重启网关,访问http://localhost:10010/user/1时,符合/user/**规则,请求转发到uri:http://userservice/user/1,得到了结果:5)网关路由的流程图整个访问的流程如下:总结:网关搭建步骤:创建项目,引入nacos服务发现和gateway依赖配置application.yml,包括服务基本信息、nacos地址、路由路由配置包括:路由id:路由的唯一标示路由目标(uri):路由的目标地址,http代表固定地址,lb代表根据服务名负载均衡路由断言(predicates):判断路由的规则,路由过滤器(filters):对请求或响应做处理接下来,就重点来学习路由断言和路由过滤器的详细知识3.3.断言工厂我们在配置文件中写的断言规则只是字符串,这些字符串会被Predicate Factory读取并处理,转变为路由判断的条件例如Path=/user/**是按照路径匹配,这个规则是由org.springframework.cloud.gateway.handler.predicate.PathRoutePredicateFactory类来处理的,像这样的断言工厂在SpringCloudGateway还有十几个:名称说明示例After是某个时间点后的请求- After=2037-01-20T17:42:47.789-07:00[America/Denver]Before是某个时间点之前的请求- Before=2031-04-13T15:14:47.433+08:00[Asia/Shanghai]Between是某两个时间点之前的请求- Between=2037-01-20T17:42:47.789-07:00[America/Denver], 2037-01-21T17:42:47.789-07:00[America/Denver]Cookie请求必须包含某些cookie- Cookie=chocolate, ch.pHeader请求必须包含某些header- Header=X-Request-Id, \d+Host请求必须是访问某个host(域名)- Host=.somehost.org,.anotherhost.orgMethod请求方式必须是指定方式- Method=GET,POSTPath请求路径必须符合指定规则- Path=/red/{segment},/blue/**Query请求参数必须包含指定参数- Query=name, Jack或者- Query=nameRemoteAddr请求者的ip必须是指定范围- RemoteAddr=192.168.1.1/24Weight权重处理 我们只需要掌握Path这种路由工程就可以了。3.4.过滤器工厂GatewayFilter是网关中提供的一种过滤器,可以对进入网关的请求和微服务返回的响应做处理:3.4.1.路由过滤器的种类Spring提供了31种不同的路由过滤器工厂。例如:名称说明AddRequestHeader给当前请求添加一个请求头RemoveRequestHeader移除请求中的一个请求头AddResponseHeader给响应结果中添加一个响应头RemoveResponseHeader从响应结果中移除有一个响应头RequestRateLimiter限制请求的流量3.4.2.请求头过滤器下面我们以AddRequestHeader 为例来讲解。需求:给所有进入userservice的请求添加一个请求头:Truth=itcast is freaking awesome!只需要修改gateway服务的application.yml文件,添加路由过滤即可:spring: cloud: gateway: routes: - id: user-service uri: lb://userservice predicates: - Path=/user/** filters: # 过滤器 - AddRequestHeader=Truth, Itcast is freaking awesome! # 添加请求头当前过滤器写在userservice路由下,因此仅仅对访问userservice的请求有效。3.4.3.默认过滤器如果要对所有的路由都生效,则可以将过滤器工厂写到default下。格式如下:spring: cloud: gateway: routes: - id: user-service uri: lb://userservice predicates: - Path=/user/** default-filters: # 默认过滤项 - AddRequestHeader=Truth, Itcast is freaking awesome! 3.4.4.总结过滤器的作用是什么?① 对路由的请求或响应做加工处理,比如添加请求头② 配置在路由下的过滤器只对当前路由的请求生效defaultFilters的作用是什么?① 对所有路由都生效的过滤器3.5.全局过滤器上一节学习的过滤器,网关提供了31种,但每一种过滤器的作用都是固定的。如果我们希望拦截请求,做自己的业务逻辑则没办法实现。3.5.1.全局过滤器作用全局过滤器的作用也是处理一切进入网关的请求和微服务响应,与GatewayFilter的作用一样。区别在于GatewayFilter通过配置定义,处理逻辑是固定的;而GlobalFilter的逻辑需要自己写代码实现。定义方式是实现GlobalFilter接口。public interface GlobalFilter { /** * 处理当前请求,有必要的话通过{@link GatewayFilterChain}将请求交给下一个过滤器处理 * * @param exchange 请求上下文,里面可以获取Request、Response等信息 * @param chain 用来把请求委托给下一个过滤器 * @return {@code Mono<Void>} 返回标示当前过滤器业务结束 */ Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain); }在filter中编写自定义逻辑,可以实现下列功能:登录状态判断权限校验请求限流等3.5.2.自定义全局过滤器需求:定义全局过滤器,拦截请求,判断请求的参数是否满足下面条件:参数中是否有authorization,authorization参数值是否为admin如果同时满足则放行,否则拦截实现:在gateway中定义一个过滤器:package cn.itcast.gateway.filters; import org.springframework.cloud.gateway.filter.GatewayFilterChain; import org.springframework.cloud.gateway.filter.GlobalFilter; import org.springframework.core.annotation.Order; import org.springframework.http.HttpStatus; import org.springframework.stereotype.Component; import org.springframework.web.server.ServerWebExchange; import reactor.core.publisher.Mono; @Order(-1) @Component public class AuthorizeFilter implements GlobalFilter { @Override public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { // 1.获取请求参数 MultiValueMap<String, String> params = exchange.getRequest().getQueryParams(); // 2.获取authorization参数 String auth = params.getFirst("authorization"); // 3.校验 if ("admin".equals(auth)) { // 放行 return chain.filter(exchange); } // 4.拦截 // 4.1.禁止访问,设置状态码 exchange.getResponse().setStatusCode(HttpStatus.FORBIDDEN); // 4.2.结束处理 return exchange.getResponse().setComplete(); } }3.5.3.过滤器执行顺序请求进入网关会碰到三类过滤器:当前路由的过滤器、DefaultFilter、GlobalFilter请求路由后,会将当前路由过滤器和DefaultFilter、GlobalFilter,合并到一个过滤器链(集合)中,排序后依次执行每个过滤器:排序的规则是什么呢?每一个过滤器都必须指定一个int类型的order值,order值越小,优先级越高,执行顺序越靠前。GlobalFilter通过实现Ordered接口,或者添加@Order注解来指定order值,由我们自己指定路由过滤器和defaultFilter的order由Spring指定,默认是按照声明顺序从1递增。当过滤器的order值一样时,会按照 defaultFilter > 路由过滤器 > GlobalFilter的顺序执行。详细内容,可以查看源码:org.springframework.cloud.gateway.route.RouteDefinitionRouteLocator#getFilters()方法是先加载defaultFilters,然后再加载某个route的filters,然后合并。org.springframework.cloud.gateway.handler.FilteringWebHandler#handle()方法会加载全局过滤器,与前面的过滤器合并后根据order排序,组织过滤器链3.6.跨域问题3.6.1.什么是跨域问题跨域:域名不一致就是跨域,主要包括:域名不同: www.taobao.com 和 www.taobao.org 和 www.jd.com 和 miaosha.jd.com域名相同,端口不同:localhost:8080和localhost8081跨域问题:浏览器禁止请求的发起者与服务端发生跨域ajax请求,请求被浏览器拦截的问题解决方案:CORS,这个以前应该学习过,这里不再赘述了。不知道的小伙伴可以查看https://www.ruanyifeng.com/blog/2016/04/cors.html3.6.2.模拟跨域问题找到课前资料的页面文件:放入tomcat或者nginx这样的web服务器中,启动并访问。可以在浏览器控制台看到下面的错误:从localhost:8090访问localhost:10010,端口不同,显然是跨域的请求。3.6.3.解决跨域问题在gateway服务的application.yml文件中,添加下面的配置:spring: cloud: gateway: # 。。。 globalcors: # 全局的跨域处理 add-to-simple-url-handler-mapping: true # 解决options请求被拦截问题 corsConfigurations: '[/**]': allowedOrigins: # 允许哪些网站的跨域请求 - "http://localhost:8090" allowedMethods: # 允许的跨域ajax的请求方式 - "GET" - "POST" - "DELETE" - "PUT" - "OPTIONS" allowedHeaders: "*" # 允许在请求中携带的头信息 allowCredentials: true # 是否允许携带cookie maxAge: 360000 # 这次跨域检测的有效期 -
RestTemplate使用 RestTemplate使用一、依赖注入 @Bean // 开启负载均衡 @LoadBalanced RestTemplate restTemplate() { return new RestTemplate(); }二、调用服务String url ="http://provider/getHi"; String respStr = restTemplate.getForObject(url, String.class);三、get 请求1、getForEntitygetForEntity方法的返回值是一个ResponseEntity,ResponseEntity是Spring对HTTP请求响应的封装,包括了几个重要的元素,如响应码、contentType、contentLength、响应消息体等。<200,Hi,[Content-Type:"text/plain;charset=UTF-8", Content-Length:"8", Date:"Fri, 10 Apr 2020 09:58:44 GMT", Keep-Alive:"timeout=60", Connection:"keep-alive"]>2、返回Map调用方 String url ="http://provider/getMap"; ResponseEntity<Map> entity = restTemplate.getForEntity(url, Map.class); System.out.println("respStr: " + entity.getBody() );生产方 @GetMapping("/getMap") public Map<String, String> getMap() { HashMap<String, String> map = new HashMap<>(); map.put("name", "500"); return map; }3、返回对象(getForEntity)调用方 ResponseEntity<Person> entity = restTemplate.getForEntity(url, Person.class); System.out.println("respStr: " + ToStringBuilder.reflectionToString(entity.getBody() ));生产方 @GetMapping("/getObj") public Person getObj() { Person person = new Person(); person.setId(100); person.setName("xiaoming"); return person; }Person类 private int id; private String name;4、传参调用4.1、使用占位符 String url ="http://provider/getObjParam?name={1}"; ResponseEntity<Person> entity = restTemplate.getForEntity(url, Person.class,"hehehe...");4.2、使用map String url ="http://provider/getObjParam?name={name}"; Map<String, String> map = Collections.singletonMap("name", " memeda"); ResponseEntity<Person> entity = restTemplate.getForEntity(url, Person.class,map);5、返回对象(getForObject)Person person = restTemplate.getForObject(url, Person.class,map);四、post 请求1、postForEntity调用方 String url ="http://provider/postParam"; Map<String, String> map = Collections.singletonMap("name", " memeda"); ResponseEntity<Person> entity = restTemplate.postForEntity(url, map, Person.class);生产方 @PostMapping("/postParam") public Person postParam(@RequestBody String name) { System.out.println("name:" + name); Person person = new Person(); person.setId(100); person.setName("xiaoming" + name); return person; }2、postForLocation调用方 String url ="http://provider/postParam"; Map<String, String> map = Collections.singletonMap("name", " memeda"); URI location = restTemplate.postForLocation(url, map, Person.class); System.out.println(location);生产方需要设置头信息,不然返回的是null public URI postParam(@RequestBody Person person,HttpServletResponse response) throws Exception { URI uri = new URI("https://www.baidu.com/s?wd="+person.getName()); response.addHeader("Location", uri.toString());五、exchange可以自定义http请求的头信息,同时保护get和post方法第一步:自定义拦截器需要实现ClientHttpRequestInterceptor接口public class LoggingClientHttpRequestInterceptor implements ClientHttpRequestInterceptor { @Override public ClientHttpResponse intercept(HttpRequest request, byte[] body, ClientHttpRequestExecution execution) throws IOException { System.out.println("拦截啦!!!"); System.out.println(request.getURI()); ClientHttpResponse response = execution.execute(request, body); System.out.println(response.getHeaders()); return response; }第二步:添加到RestTemplate中 @Bean @LoadBalanced RestTemplate restTemplate() { RestTemplate restTemplate = new RestTemplate(); restTemplate.getInterceptors().add(new LoggingClientHttpRequestInterceptor()); return restTemplate; }
-
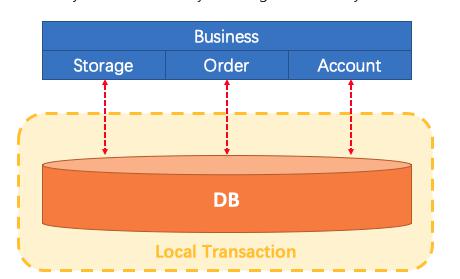
本地事务与分布式事务 本地事务一、事务的基本性质数据库事务的几个特性:原子性(Atomicity )、一致性( Consistency )、隔离性或独立性( Isolation)和持久性(Durabilily),简称就是ACID;原子性:一系列的操作整体不可拆分,要么同时成功,要么同时失败一致性:数据在事务的前后,业务整体一致。(A向B转账,转账前后AB总金额一致)隔离性:事务之间互相隔离。持久性:一旦事务成功,数据一定会落盘在数据库。单体应用中,我们多个业务操作使用同一条连接操作不同的数据表,一旦有异常,我们可以很容易的整体回滚;Business:我们具体的业务代码Storage:库存业务代码;扣库存Order:订单业务代码;保存订单Account:账号业务代码;减账户余额比如买东西业务,扣库存,下订单,账户扣款,是一个整体;必须同时成功或者失败一个事务开始,代表以下的所有操作都在同一个连接里面;二、事务的隔离级别READ UNCOMMITTED(读未提交)该隔离级别的事务会读到其它未提交事务的数据,此现象也称之为脏读。READ COMMITTED(读提交)一个事务可以读取另一个已提交的事务,多次读取会造成不一样的结果,此现象称为不可重复读问题,Oracle 和SQL Server 的默认隔离级别。REPEATABLE READ(可重复读)该隔离级别是MySQL 默认的隔离级别,在同一个事务里,select 的结果是事务开始时时间点的状态,因此,同样的select 操作读到的结果会是一致的,但是,会有幻读现象。MySQL的InnoDB 引擎可以通过next-key locks 机制(行锁的算法)来避免幻读。SERIALIZABLE(序列化)在该隔离级别下事务都是串行顺序执行的,MySQL 数据库的InnoDB 引擎会给读操作隐式加一把读共享锁,从而避免了脏读、不可重读复读和幻读问题。三、事务的传播行为PROPAGATION_REQUIRED如果当前没有事务,就创建一个新事务,如果当前存在事务,就加入该事务,该设置是最常用的设置。PROPAGATION_SUPPORTS支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行。PROPAGATION_MANDATORY支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常。PROPAGATION_REQUIRES_NEW创建新事务,无论当前存不存在事务,都创建新事务。PROPAGATION_NOT_SUPPORTED以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。PROPAGATION_NEVER以非事务方式执行,如果当前存在事务,则抛出异常。PROPAGATION_NESTED如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与PROPAGATION_REQUIRED 类似的操作。四、SpringBoot 事务关键点事务的自动配置TransactionAutoConfiguration事务的坑在同一个类里面,编写两个方法,内部调用的时候,会导致事务设置失效。原因是没有用到代理对象的缘故。解决0)、导入spring-boot-starter-aop1)、@EnableTransactionManagement(proxyTargetClass = true)2)、@EnableAspectJAutoProxy(exposeProxy=true)3)、AopContext.currentProxy() 调用方法分布式事务一、为什么有分布式事务分布式系统经常出现的异常机器宕机、网络异常、消息丢失、消息乱序、数据错误、不可靠的TCP、存储数据丢失...二、CAP 定理与BASE 理论1、CAP 定理CAP 原则又称CAP 定理,指的是在一个分布式系统中一致性(Consistency)在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)可用性(Availability)在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)分区容错性(Partition tolerance)大多数分布式系统都分布在多个子网络。每个子网络就叫做一个区(partition)。分区容错的意思是,区间通信可能失败。比如,一台服务器放在中国,另一台服务器放在美国,这就是两个区,它们之间可能无法通信。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。一般来说,分区容错无法避免,因此可以认为CAP 的P 总是成立。CAP 定理告诉我们,剩下的C 和A 无法同时做到。分布式系统中实现一致性的raft 算法、paxos http://thesecretlivesofdata.com/raft/面临的问题对于多数大型互联网应用的场景,主机众多、部署分散,而且现在的集群规模越来越大,所以节点故障、网络故障是常态,而且要保证服务可用性达到99.99999%(N 个9),即保证P 和A,舍弃C。2、BASE 理论是对CAP 理论的延伸,思想是即使无法做到强一致性(CAP 的一致性就是强一致性),但可以采用适当的采取弱一致性,即最终一致性。什么是BASE :基本可用(Basically Available)基本可用是指分布式系统在出现故障的时候,允许损失部分可用性(例如响应时间、功能上的可用性),允许损失部分可用性。需要注意的是,基本可用绝不等价于系统不可用。响应时间上的损失:正常情况下搜索引擎需要在0.5 秒之内返回给用户相应的查询结果,但由于出现故障(比如系统部分机房发生断电或断网故障),查询结果的响应时间增加到了1~2 秒。功能上的损失:购物网站在购物高峰(如双十一)时,为了保护系统的稳定性,部分消费者可能会被引导到一个降级页面。软状态( Soft State)软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据会有多个副本,允许不同副本同步的延时就是软状态的体现。mysql replication 的异步复制也是一种体现。最终一致性( Eventual Consistency)最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。强一致性、弱一致性、最终一致性从客户端角度,多进程并发访问时,更新过的数据在不同进程如何获取的不同策略,决定了不同的一致性。对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。如果能容忍后续的部分或者全部访问不到,则是弱一致性。如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。3、分布式事务几种方案2PC 模式数据库支持的2PC【2 phase commit 二阶提交】,又叫做XA Transactions。MySQL 从5.5 版本开始支持,SQL Server 2005 开始支持,Oracle 7 开始支持。其中,XA 是一个两阶段提交协议,该协议分为以下两个阶段:第一阶段:事务协调器要求每个涉及到事务的数据库预提交(precommit)此操作,并反映是否可以提交。第二阶段:事务协调器要求每个数据库提交数据。其中,如果有任何一个数据库否决此次提交,那么所有数据库都会被要求回滚它们在此事务中的那部分信息。XA 协议比较简单,而且一旦商业数据库实现了XA 协议,使用分布式事务的成本也比较低。XA 性能不理想,特别是在交易下单链路,往往并发量很高,XA 无法满足高并发场景XA 目前在商业数据库支持的比较理想,在mysql 数据库中支持的不太理想,mysql 的XA 实现,没有记录prepare 阶段日志,主备切换回导致主库与备库数据不一致。许多nosql 也没有支持XA,这让XA 的应用场景变得非常狭隘。也有3PC,引入了超时机制(无论协调者还是参与者,在向对方发送请求后,若长时间未收到回应则做出相应处理)。柔性事务-TCC 事务补偿型方案刚性事务:遵循ACID 原则,强一致性。柔性事务:遵循BASE 理论,最终一致性;与刚性事务不同,柔性事务允许一定时间内,不同节点的数据不一致,但要求最终一致。一阶段prepare 行为:调用自定义的prepare 逻辑。二阶段commit 行为:调用自定义的commit 逻辑。二阶段rollback 行为:调用自定义的rollback 逻辑。所谓TCC 模式,是指支持把自定义的分支事务纳入到全局事务的管理中。柔性事务-最大努力通知型方案按规律进行通知,不保证数据一定能通知成功,但会提供可查询操作接口进行核对。这种方案主要用在与第三方系统通讯时,比如:调用微信或支付宝支付后的支付结果通知。这种方案也是结合MQ 进行实现,例如:通过MQ 发送http 请求,设置最大通知次数。达到通知次数后即不再通知。案例:银行通知、商户通知等(各大交易业务平台间的商户通知:多次通知、查询校对、对账文件),支付宝的支付成功异步回调。柔性事务-可靠消息+最终一致性方案(异步确保型)实现:业务处理服务在业务事务提交之前,向实时消息服务请求发送消息,实时消息服务只记录消息数据,而不是真正的发送。业务处理服务在业务事务提交之后,向实时消息服务确认发送。只有在得到确认发送指令后,实时消息服务才会真正发送。防止消息丢失:/** * 1、做好消息确认机制(pulisher,consumer【手动ack】) * 2、每一个发送的消息都在数据库做好记录。定期将失败的消息再次发送一 遍 */CREATE TABLE `mq_message` ( `message_id` char(32) NOT NULL, `content` text, `to_exchane` varchar(255) DEFAULT NULL, `routing_key` varchar(255) DEFAULT NULL, `class_type` varchar(255) DEFAULT NULL, `message_status` int(1) DEFAULT '0' COMMENT '0-新建1-已发送2-错误抵达3-已抵达', `create_time` datetime DEFAULT NULL, `update_time` datetime DEFAULT NULL, PRIMARY KEY (`message_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
-
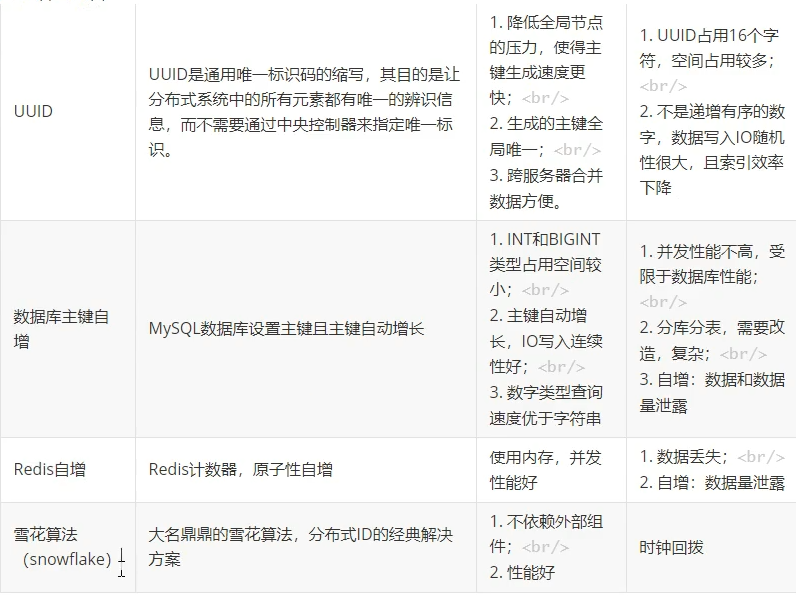
接口幂等性 接口幂等性1、什么是幂等性接口幂等性就是用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用;比如说支付场景,用户购买了商品支付扣款成功,但是返回结果的时候网络异常,此时钱已经扣了,用户再次点击按钮,此时会进行第二次扣款,返回结果成功,用户查询余额返发现多扣钱了,流水记录也变成了两条...,这就没有保证接口的幂等性。2、哪些情况需要防止用户多次点击按钮用户页面回退再次提交微服务互相调用,由于网络问题,导致请求失败。feign触发重试机制其他业务情况3、什么情况下需要幂等天然幂等的:以SQL为例,有些操作是。SELECT*FROM table WHERid=?无论执行多少次都不会改变状态,是天然的幂等。UPDATE tab1 SET col1=1WHERE col2=2 无论执行成功多少次状态都是一致的,也是幂等操作。delete from user where userid=1多次操作,结果一样,具备幂等性insert into user(userid,name)values(1,a)如userid为唯一主键,即重复操作上面的业务,只会插入一条用户数据,具备幂等性。不是幂等的UPDATE tab1 SET col1=col1+1WHERE col2=2每次执行的结果都会发生变化,不是幂等的。insert into user(userid,name)values(1,a)如userid不是主键,可以重复,那上面业务多次操作,数据都会新增多条,不具备幂等性。4、幂等解决方案一、token机制1、服务端提供了发送token的接口。我们在分析业务的时候,哪些业务是存在幂等问题的,就必须在执行业务前,先去获取token,服务器会把token保存到redis中。2、然后调用业务接口请求时,把token携带过去,一般放在请求头部。3、服务器判断token是否存在redis中,存在表示第一次请求,然后删除token,继续执行业务。4、如果判断token不存在redis中,就表示是重复操作,直接返回重复标记给client,这样就保证了业务代码,不被重复执行。危险性:1、先删除token 还是后删除token;(1)先删除可能导致,业务确实没有执行,重试还带上之前token,由于防重设计导致,请求还是不能执行。(2)后删除可能导致,业务处理成功,但是服务闪断,出现超时,没有删除 token,别人继续重试,导致业务被执行两边(3)我们最好设计为先删除token,如果业务调用失败,就重新获取token 再次请求。2、Token获取、比较和删除必须是原子性(1)redis.get(token)、token.equals、redis.delltoken)如果这两个操作不是原子,可能导致,高并发下,都get 到同样的数据,判断都成功,继续业务并发执行(2)可以在redis 使用lua脚本完成这个操作if redis. call("get', KEYS[1])==ARGV[1] then return redis. call(' del", KEYS[1]) else return 0 end二、各种锁机制1、数据库悲观锁select*from xxxx where id=1 for update;悲观锁使用时一般伴随事务一起使用,数据锁定时间可能会很长,需要根据实际情况选用。另外要注意的是,id字段一定是主键或者唯一索引,不然可能造成锁表的结果,处理起来会非常麻烦。2、数据库乐观锁这种方法适合在更新的场景中update t_goods set count=count-1,version =version+1 where good_id=2 and version=1根据 version版本,也就是在操作库存前先获取当前商品的 version 版本号,然后操作的时候带上此version号。我们梳理下,我们第一次操作库存时,得到version为1,调用库存服务version变成了2;但返回给订单服务出现了问题,订单服务又一次发起调用库存服务,当订单服务传如的version还是1,再执行上面的sql语句时,就不会执行;因为version已经变为2了,where条件就不成立。这样就保证了不管调用几次,只会真正的处理一次。乐观锁主要使用于处理读多写少的问题。3、业务层分怖式锁如果多个机器可能在同一时间同时处理相同的数据,比如多台机器定时任务都拿到了相同数据处理,我们就可以加分布式锁,锁定此数据,处理完成后释放锁。获取到锁的必须先判断这个数据是否被处理过。3、各种唯一约束1、数据库唯一约束插入数据,应该按照唯一索引进行插入,比如订单号,相同的订单就不可能有两条记录插入。我们在数据库层面防止重复。这个机制是利用了数据库的主键唯一约束的特性,解决了在insert场景时幂等问题。但主键的要求不是自增的主键,这样就需要业务生成全局唯一的主键。如果是分库分表场景下,路由规则要保证相同请求下,落地在同一个数据库和同一表中,要不然数据库主键约束就不起效果了,因为是不同的数据库和表主键不相关。2、redis set防重很多数据需要处理,只能被处理一次,比如我们可以计算数据的MD5将其放入redis的set,每次处理数据,先看这个MD5是否已经存在,存在就不处理。4、防重表使用订单号orderNo做为去重表的唯一索引,把唯一索引插入去重表,再进行业务操作,且他们在同一个事务中。这个保证了重复请求时,因为去重表有唯一约束,导致请求失败,避免了幂等问题。这里要注意的是,去重表和业务表应该在同一库中,这样就保证了在同一个事务,即使业务操作失败了,也会把去重表的数据回滚。这个很好的保证了数据一致性。redis防重也算。5、全局请求唯一id调用接口时,生成一个唯一id,redis 将数据保存到集合中(去重),存在即处理过。可以使用nginx设置每一个请求的唯一id;proxy_set_header X-Request-ld Srequest_id;
-
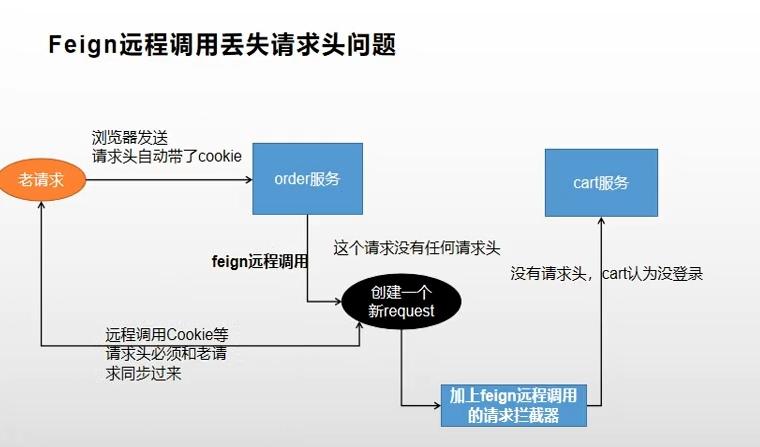
Feign远程调用丢失请求头问题 openFeign远程调用丢失请求头feign在远程调用之前要构造请求,调用会经过很多拦截器。丢失请求头原因,是远程调用重新构建了request请求,新的request没有请求头headr。解决方案:定义一个feign的拦截器先来看一下feign远程调用类SynchronousMethodHandler// // Source code recreated from a .class file by IntelliJ IDEA // (powered by FernFlower decompiler) // package feign; import feign.InvocationHandlerFactory.MethodHandler; import feign.Logger.Level; import feign.Request.Options; import feign.codec.Decoder; import feign.codec.ErrorDecoder; import java.io.IOException; import java.util.Iterator; import java.util.List; import java.util.concurrent.CompletableFuture; import java.util.concurrent.CompletionException; import java.util.concurrent.TimeUnit; import java.util.stream.Stream; final class SynchronousMethodHandler implements MethodHandler { private static final long MAX_RESPONSE_BUFFER_SIZE = 8192L; private final MethodMetadata metadata; private final Target<?> target; private final Client client; private final Retryer retryer; private final List<RequestInterceptor> requestInterceptors; private final Logger logger; private final Level logLevel; private final feign.RequestTemplate.Factory buildTemplateFromArgs; private final Options options; private final ExceptionPropagationPolicy propagationPolicy; private final Decoder decoder; private final AsyncResponseHandler asyncResponseHandler; private SynchronousMethodHandler(Target<?> target, Client client, Retryer retryer, List<RequestInterceptor> requestInterceptors, Logger logger, Level logLevel, MethodMetadata metadata, feign.RequestTemplate.Factory buildTemplateFromArgs, Options options, Decoder decoder, ErrorDecoder errorDecoder, boolean decode404, boolean closeAfterDecode, ExceptionPropagationPolicy propagationPolicy, boolean forceDecoding) { this.target = (Target)Util.checkNotNull(target, "target", new Object[0]); this.client = (Client)Util.checkNotNull(client, "client for %s", new Object[]{target}); this.retryer = (Retryer)Util.checkNotNull(retryer, "retryer for %s", new Object[]{target}); this.requestInterceptors = (List)Util.checkNotNull(requestInterceptors, "requestInterceptors for %s", new Object[]{target}); this.logger = (Logger)Util.checkNotNull(logger, "logger for %s", new Object[]{target}); this.logLevel = (Level)Util.checkNotNull(logLevel, "logLevel for %s", new Object[]{target}); this.metadata = (MethodMetadata)Util.checkNotNull(metadata, "metadata for %s", new Object[]{target}); this.buildTemplateFromArgs = (feign.RequestTemplate.Factory)Util.checkNotNull(buildTemplateFromArgs, "metadata for %s", new Object[]{target}); this.options = (Options)Util.checkNotNull(options, "options for %s", new Object[]{target}); this.propagationPolicy = propagationPolicy; if (forceDecoding) { this.decoder = decoder; this.asyncResponseHandler = null; } else { this.decoder = null; this.asyncResponseHandler = new AsyncResponseHandler(logLevel, logger, decoder, errorDecoder, decode404, closeAfterDecode); } } public Object invoke(Object[] argv) throws Throwable { RequestTemplate template = this.buildTemplateFromArgs.create(argv); Options options = this.findOptions(argv); Retryer retryer = this.retryer.clone(); while(true) { try { return this.executeAndDecode(template, options); } catch (RetryableException var9) { RetryableException e = var9; try { retryer.continueOrPropagate(e); } catch (RetryableException var8) { Throwable cause = var8.getCause(); if (this.propagationPolicy == ExceptionPropagationPolicy.UNWRAP && cause != null) { throw cause; } throw var8; } if (this.logLevel != Level.NONE) { this.logger.logRetry(this.metadata.configKey(), this.logLevel); } } } } Object executeAndDecode(RequestTemplate template, Options options) throws Throwable { Request request = this.targetRequest(template); if (this.logLevel != Level.NONE) { this.logger.logRequest(this.metadata.configKey(), this.logLevel, request); } long start = System.nanoTime(); Response response; try { response = this.client.execute(request, options); response = response.toBuilder().request(request).requestTemplate(template).build(); } catch (IOException var12) { if (this.logLevel != Level.NONE) { this.logger.logIOException(this.metadata.configKey(), this.logLevel, var12, this.elapsedTime(start)); } throw FeignException.errorExecuting(request, var12); } long elapsedTime = TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - start); if (this.decoder != null) { return this.decoder.decode(response, this.metadata.returnType()); } else { CompletableFuture<Object> resultFuture = new CompletableFuture(); this.asyncResponseHandler.handleResponse(resultFuture, this.metadata.configKey(), response, this.metadata.returnType(), elapsedTime); try { if (!resultFuture.isDone()) { throw new IllegalStateException("Response handling not done"); } else { return resultFuture.join(); } } catch (CompletionException var13) { Throwable cause = var13.getCause(); if (cause != null) { throw cause; } else { throw var13; } } } } long elapsedTime(long start) { return TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - start); } Request targetRequest(RequestTemplate template) { Iterator var2 = this.requestInterceptors.iterator(); while(var2.hasNext()) { RequestInterceptor interceptor = (RequestInterceptor)var2.next(); interceptor.apply(template); } return this.target.apply(template); } Options findOptions(Object[] argv) { if (argv != null && argv.length != 0) { Stream var10000 = Stream.of(argv); Options.class.getClass(); var10000 = var10000.filter(Options.class::isInstance); Options.class.getClass(); return (Options)var10000.map(Options.class::cast).findFirst().orElse(this.options); } else { return this.options; } } static class Factory { private final Client client; private final Retryer retryer; private final List<RequestInterceptor> requestInterceptors; private final Logger logger; private final Level logLevel; private final boolean decode404; private final boolean closeAfterDecode; private final ExceptionPropagationPolicy propagationPolicy; private final boolean forceDecoding; Factory(Client client, Retryer retryer, List<RequestInterceptor> requestInterceptors, Logger logger, Level logLevel, boolean decode404, boolean closeAfterDecode, ExceptionPropagationPolicy propagationPolicy, boolean forceDecoding) { this.client = (Client)Util.checkNotNull(client, "client", new Object[0]); this.retryer = (Retryer)Util.checkNotNull(retryer, "retryer", new Object[0]); this.requestInterceptors = (List)Util.checkNotNull(requestInterceptors, "requestInterceptors", new Object[0]); this.logger = (Logger)Util.checkNotNull(logger, "logger", new Object[0]); this.logLevel = (Level)Util.checkNotNull(logLevel, "logLevel", new Object[0]); this.decode404 = decode404; this.closeAfterDecode = closeAfterDecode; this.propagationPolicy = propagationPolicy; this.forceDecoding = forceDecoding; } public MethodHandler create(Target<?> target, MethodMetadata md, feign.RequestTemplate.Factory buildTemplateFromArgs, Options options, Decoder decoder, ErrorDecoder errorDecoder) { return new SynchronousMethodHandler(target, this.client, this.retryer, this.requestInterceptors, this.logger, this.logLevel, md, buildTemplateFromArgs, options, decoder, errorDecoder, this.decode404, this.closeAfterDecode, this.propagationPolicy, this.forceDecoding); } } } 远程调用时,构建了RequestInterceptor。自定义feign拦截器import feign.RequestInterceptor; import feign.RequestTemplate; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.web.context.request.RequestContextHolder; import org.springframework.web.context.request.ServletRequestAttributes; import javax.servlet.http.HttpServletRequest; /** * @description: TODO * @author: <a href="mailto:batis@foxmail.com">清风</a> * @date: 2022/3/10 23:03 * @version: 1.0 */ @Configuration public class FamilyFegin { @Bean(name ="requestInterceptor") public RequestInterceptor requestInterceptor(){ return new RequestInterceptor() { @Override public void apply(RequestTemplate requestTemplate) { //RequestContextHolder拿到刚请求来的数据 ServletRequestAttributes requestAttributes = (ServletRequestAttributes)RequestContextHolder.getRequestAttributes(); HttpServletRequest request = requestAttributes.getRequest(); System.out.println("调用feign之前"); //同步请求头数据 String cookie = request.getHeader("Cookie");//老数据 //给新请求同步老请求的cookie requestTemplate.header("Cookie", cookie); } }; } }拦截器说明RequestContextHolder.getRequestAttributes()获取到RequestAttributes类,RequestAttributes源码:// // Source code recreated from a .class file by IntelliJ IDEA // (powered by FernFlower decompiler) // package org.springframework.web.context.request; import org.springframework.lang.Nullable; public interface RequestAttributes { int SCOPE_REQUEST = 0; int SCOPE_SESSION = 1; String REFERENCE_REQUEST = "request"; String REFERENCE_SESSION = "session"; @Nullable Object getAttribute(String var1, int var2); void setAttribute(String var1, Object var2, int var3); void removeAttribute(String var1, int var2); String[] getAttributeNames(int var1); void registerDestructionCallback(String var1, Runnable var2, int var3); @Nullable Object resolveReference(String var1); String getSessionId(); Object getSessionMutex(); } ServletRequestAttributes继承了AbstractRequestAttributes,AbstractRequestAttributes实现了RequestAttributes,因此可以强转。 public abstract class AbstractRequestAttributes implements RequestAttributes { protected final Map<String, Runnable> requestDestructionCallbacks = new LinkedHashMap(8); private volatile boolean requestActive = true; public AbstractRequestAttributes() { } public void requestCompleted() {注意:该处理是在同步一个线程种处理的,才能获取之前的heard中的cookie信息。异步多线程该处理方式不同。
-
-
-
-