搜索到
10
篇与
的结果
-
 RabbitMQ基本使用 RabbitMQ1.初识MQ1.1.同步和异步通讯微服务间通讯有同步和异步两种方式:同步通讯:就像打电话,需要实时响应。异步通讯:就像发邮件,不需要马上回复。两种方式各有优劣,打电话可以立即得到响应,但是你却不能跟多个人同时通话。发送邮件可以同时与多个人收发邮件,但是往往响应会有延迟。1.1.1.同步通讯我们之前学习的Feign调用就属于同步方式,虽然调用可以实时得到结果,但存在下面的问题:总结:同步调用的优点:时效性较强,可以立即得到结果同步调用的问题:耦合度高性能和吞吐能力下降有额外的资源消耗有级联失败问题1.1.2.异步通讯异步调用则可以避免上述问题:我们以购买商品为例,用户支付后需要调用订单服务完成订单状态修改,调用物流服务,从仓库分配响应的库存并准备发货。在事件模式中,支付服务是事件发布者(publisher),在支付完成后只需要发布一个支付成功的事件(event),事件中带上订单id。订单服务和物流服务是事件订阅者(Consumer),订阅支付成功的事件,监听到事件后完成自己业务即可。为了解除事件发布者与订阅者之间的耦合,两者并不是直接通信,而是有一个中间人(Broker)。发布者发布事件到Broker,不关心谁来订阅事件。订阅者从Broker订阅事件,不关心谁发来的消息。Broker 是一个像数据总线一样的东西,所有的服务要接收数据和发送数据都发到这个总线上,这个总线就像协议一样,让服务间的通讯变得标准和可控。好处:吞吐量提升:无需等待订阅者处理完成,响应更快速故障隔离:服务没有直接调用,不存在级联失败问题调用间没有阻塞,不会造成无效的资源占用耦合度极低,每个服务都可以灵活插拔,可替换流量削峰:不管发布事件的流量波动多大,都由Broker接收,订阅者可以按照自己的速度去处理事件缺点:架构复杂了,业务没有明显的流程线,不好管理需要依赖于Broker的可靠、安全、性能好在现在开源软件或云平台上 Broker 的软件是非常成熟的,比较常见的一种就是我们今天要学习的MQ技术。1.2.技术对比:MQ,中文是消息队列(MessageQueue),字面来看就是存放消息的队列。也就是事件驱动架构中的Broker。比较常见的MQ实现:ActiveMQRabbitMQRocketMQKafka几种常见MQ的对比: RabbitMQActiveMQRocketMQKafka公司/社区RabbitApache阿里Apache开发语言ErlangJavaJavaScala&Java协议支持AMQP,XMPP,SMTP,STOMPOpenWire,STOMP,REST,XMPP,AMQP自定义协议自定义协议可用性高一般高高单机吞吐量一般差高非常高消息延迟微秒级毫秒级毫秒级毫秒以内消息可靠性高一般高一般追求可用性:Kafka、 RocketMQ 、RabbitMQ追求可靠性:RabbitMQ、RocketMQ追求吞吐能力:RocketMQ、Kafka追求消息低延迟:RabbitMQ、Kafka2.快速入门2.1.安装RabbitMQ安装RabbitMQ,参考课前资料:MQ的基本结构:RabbitMQ中的一些角色:publisher:生产者consumer:消费者exchange个:交换机,负责消息路由queue:队列,存储消息virtualHost:虚拟主机,隔离不同租户的exchange、queue、消息的隔离2.2.RabbitMQ消息模型RabbitMQ官方提供了5个不同的Demo示例,对应了不同的消息模型:2.3.导入Demo工程课前资料提供了一个Demo工程,mq-demo:导入后可以看到结构如下:包括三部分:mq-demo:父工程,管理项目依赖publisher:消息的发送者consumer:消息的消费者2.4.入门案例简单队列模式的模型图:官方的HelloWorld是基于最基础的消息队列模型来实现的,只包括三个角色:publisher:消息发布者,将消息发送到队列queuequeue:消息队列,负责接受并缓存消息consumer:订阅队列,处理队列中的消息2.4.1.publisher实现思路:建立连接创建Channel声明队列发送消息关闭连接和channel代码实现:package cn.itcast.mq.helloworld; import com.rabbitmq.client.Channel; import com.rabbitmq.client.Connection; import com.rabbitmq.client.ConnectionFactory; import org.junit.Test; import java.io.IOException; import java.util.concurrent.TimeoutException; public class PublisherTest { @Test public void testSendMessage() throws IOException, TimeoutException { // 1.建立连接 ConnectionFactory factory = new ConnectionFactory(); // 1.1.设置连接参数,分别是:主机名、端口号、vhost、用户名、密码 factory.setHost("192.168.150.101"); factory.setPort(5672); factory.setVirtualHost("/"); factory.setUsername("itcast"); factory.setPassword("123321"); // 1.2.建立连接 Connection connection = factory.newConnection(); // 2.创建通道Channel Channel channel = connection.createChannel(); // 3.创建队列 String queueName = "simple.queue"; channel.queueDeclare(queueName, false, false, false, null); // 4.发送消息 String message = "hello, rabbitmq!"; channel.basicPublish("", queueName, null, message.getBytes()); System.out.println("发送消息成功:【" + message + "】"); // 5.关闭通道和连接 channel.close(); connection.close(); } }2.4.2.consumer实现代码思路:建立连接创建Channel声明队列订阅消息代码实现:package cn.itcast.mq.helloworld; import com.rabbitmq.client.*; import java.io.IOException; import java.util.concurrent.TimeoutException; public class ConsumerTest { public static void main(String[] args) throws IOException, TimeoutException { // 1.建立连接 ConnectionFactory factory = new ConnectionFactory(); // 1.1.设置连接参数,分别是:主机名、端口号、vhost、用户名、密码 factory.setHost("192.168.150.101"); factory.setPort(5672); factory.setVirtualHost("/"); factory.setUsername("itcast"); factory.setPassword("123321"); // 1.2.建立连接 Connection connection = factory.newConnection(); // 2.创建通道Channel Channel channel = connection.createChannel(); // 3.创建队列 String queueName = "simple.queue"; channel.queueDeclare(queueName, false, false, false, null); // 4.订阅消息 channel.basicConsume(queueName, true, new DefaultConsumer(channel){ @Override public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException { // 5.处理消息 String message = new String(body); System.out.println("接收到消息:【" + message + "】"); } }); System.out.println("等待接收消息。。。。"); } }2.5.总结基本消息队列的消息发送流程:建立connection创建channel利用channel声明队列利用channel向队列发送消息基本消息队列的消息接收流程:建立connection创建channel利用channel声明队列定义consumer的消费行为handleDelivery()利用channel将消费者与队列绑定3.SpringAMQPSpringAMQP是基于RabbitMQ封装的一套模板,并且还利用SpringBoot对其实现了自动装配,使用起来非常方便。SpringAmqp的官方地址:https://spring.io/projects/spring-amqpSpringAMQP提供了三个功能:自动声明队列、交换机及其绑定关系基于注解的监听器模式,异步接收消息封装了RabbitTemplate工具,用于发送消息3.1.Basic Queue 简单队列模型在父工程mq-demo中引入依赖<!--AMQP依赖,包含RabbitMQ--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> </dependency>3.1.1.消息发送首先配置MQ地址,在publisher服务的application.yml中添加配置:spring: rabbitmq: host: 192.168.150.101 # 主机名 port: 5672 # 端口 virtual-host: / # 虚拟主机 username: itcast # 用户名 password: 123321 # 密码然后在publisher服务中编写测试类SpringAmqpTest,并利用RabbitTemplate实现消息发送:package cn.itcast.mq.spring; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.amqp.rabbit.core.RabbitTemplate; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit4.SpringRunner; @RunWith(SpringRunner.class) @SpringBootTest public class SpringAmqpTest { @Autowired private RabbitTemplate rabbitTemplate; @Test public void testSimpleQueue() { // 队列名称 String queueName = "simple.queue"; // 消息 String message = "hello, spring amqp!"; // 发送消息 rabbitTemplate.convertAndSend(queueName, message); } }3.1.2.消息接收首先配置MQ地址,在consumer服务的application.yml中添加配置:spring: rabbitmq: host: 192.168.150.101 # 主机名 port: 5672 # 端口 virtual-host: / # 虚拟主机 username: itcast # 用户名 password: 123321 # 密码然后在consumer服务的cn.itcast.mq.listener包中新建一个类SpringRabbitListener,代码如下:package cn.itcast.mq.listener; import org.springframework.amqp.rabbit.annotation.RabbitListener; import org.springframework.stereotype.Component; @Component public class SpringRabbitListener { @RabbitListener(queues = "simple.queue") public void listenSimpleQueueMessage(String msg) throws InterruptedException { System.out.println("spring 消费者接收到消息:【" + msg + "】"); } }3.1.3.测试启动consumer服务,然后在publisher服务中运行测试代码,发送MQ消息3.2.WorkQueueWork queues,也被称为(Task queues),任务模型。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息。当消息处理比较耗时的时候,可能生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,无法及时处理。此时就可以使用work 模型,多个消费者共同处理消息处理,速度就能大大提高了。3.2.1.消息发送这次我们循环发送,模拟大量消息堆积现象。在publisher服务中的SpringAmqpTest类中添加一个测试方法:/** * workQueue * 向队列中不停发送消息,模拟消息堆积。 */ @Test public void testWorkQueue() throws InterruptedException { // 队列名称 String queueName = "simple.queue"; // 消息 String message = "hello, message_"; for (int i = 0; i < 50; i++) { // 发送消息 rabbitTemplate.convertAndSend(queueName, message + i); Thread.sleep(20); } }3.2.2.消息接收要模拟多个消费者绑定同一个队列,我们在consumer服务的SpringRabbitListener中添加2个新的方法:@RabbitListener(queues = "simple.queue") public void listenWorkQueue1(String msg) throws InterruptedException { System.out.println("消费者1接收到消息:【" + msg + "】" + LocalTime.now()); Thread.sleep(20); } @RabbitListener(queues = "simple.queue") public void listenWorkQueue2(String msg) throws InterruptedException { System.err.println("消费者2........接收到消息:【" + msg + "】" + LocalTime.now()); Thread.sleep(200); }注意到这个消费者sleep了1000秒,模拟任务耗时。3.2.3.测试启动ConsumerApplication后,在执行publisher服务中刚刚编写的发送测试方法testWorkQueue。可以看到消费者1很快完成了自己的25条消息。消费者2却在缓慢的处理自己的25条消息。也就是说消息是平均分配给每个消费者,并没有考虑到消费者的处理能力。这样显然是有问题的。3.2.4.能者多劳在spring中有一个简单的配置,可以解决这个问题。我们修改consumer服务的application.yml文件,添加配置:spring: rabbitmq: listener: simple: prefetch: 1 # 每次只能获取一条消息,处理完成才能获取下一个消息3.2.5.总结Work模型的使用:多个消费者绑定到一个队列,同一条消息只会被一个消费者处理通过设置prefetch来控制消费者预取的消息数量3.3.发布/订阅发布订阅的模型如图:可以看到,在订阅模型中,多了一个exchange角色,而且过程略有变化:Publisher:生产者,也就是要发送消息的程序,但是不再发送到队列中,而是发给X(交换机)Exchange:交换机,图中的X。一方面,接收生产者发送的消息。另一方面,知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。Exchange有以下3种类型:Fanout:广播,将消息交给所有绑定到交换机的队列Direct:定向,把消息交给符合指定routing key 的队列Topic:通配符,把消息交给符合routing pattern(路由模式) 的队列Consumer:消费者,与以前一样,订阅队列,没有变化Queue:消息队列也与以前一样,接收消息、缓存消息。Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!3.4.FanoutFanout,英文翻译是扇出,我觉得在MQ中叫广播更合适。在广播模式下,消息发送流程是这样的:1) 可以有多个队列2) 每个队列都要绑定到Exchange(交换机)3) 生产者发送的消息,只能发送到交换机,交换机来决定要发给哪个队列,生产者无法决定4) 交换机把消息发送给绑定过的所有队列5) 订阅队列的消费者都能拿到消息我们的计划是这样的:创建一个交换机 itcast.fanout,类型是Fanout创建两个队列fanout.queue1和fanout.queue2,绑定到交换机itcast.fanout3.4.1.声明队列和交换机Spring提供了一个接口Exchange,来表示所有不同类型的交换机:在consumer中创建一个类,声明队列和交换机:package cn.itcast.mq.config; import org.springframework.amqp.core.Binding; import org.springframework.amqp.core.BindingBuilder; import org.springframework.amqp.core.FanoutExchange; import org.springframework.amqp.core.Queue; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class FanoutConfig { /** * 声明交换机 * @return Fanout类型交换机 */ @Bean public FanoutExchange fanoutExchange(){ return new FanoutExchange("itcast.fanout"); } /** * 第1个队列 */ @Bean public Queue fanoutQueue1(){ return new Queue("fanout.queue1"); } /** * 绑定队列和交换机 */ @Bean public Binding bindingQueue1(Queue fanoutQueue1, FanoutExchange fanoutExchange){ return BindingBuilder.bind(fanoutQueue1).to(fanoutExchange); } /** * 第2个队列 */ @Bean public Queue fanoutQueue2(){ return new Queue("fanout.queue2"); } /** * 绑定队列和交换机 */ @Bean public Binding bindingQueue2(Queue fanoutQueue2, FanoutExchange fanoutExchange){ return BindingBuilder.bind(fanoutQueue2).to(fanoutExchange); } }3.4.2.消息发送在publisher服务的SpringAmqpTest类中添加测试方法:@Test public void testFanoutExchange() { // 队列名称 String exchangeName = "itcast.fanout"; // 消息 String message = "hello, everyone!"; rabbitTemplate.convertAndSend(exchangeName, "", message); }3.4.3.消息接收在consumer服务的SpringRabbitListener中添加两个方法,作为消费者:@RabbitListener(queues = "fanout.queue1") public void listenFanoutQueue1(String msg) { System.out.println("消费者1接收到Fanout消息:【" + msg + "】"); } @RabbitListener(queues = "fanout.queue2") public void listenFanoutQueue2(String msg) { System.out.println("消费者2接收到Fanout消息:【" + msg + "】"); }3.4.4.总结交换机的作用是什么?接收publisher发送的消息将消息按照规则路由到与之绑定的队列不能缓存消息,路由失败,消息丢失FanoutExchange的会将消息路由到每个绑定的队列声明队列、交换机、绑定关系的Bean是什么?QueueFanoutExchangeBinding3.5.Direct在Fanout模式中,一条消息,会被所有订阅的队列都消费。但是,在某些场景下,我们希望不同的消息被不同的队列消费。这时就要用到Direct类型的Exchange。在Direct模型下:队列与交换机的绑定,不能是任意绑定了,而是要指定一个RoutingKey(路由key)消息的发送方在 向 Exchange发送消息时,也必须指定消息的 RoutingKey。Exchange不再把消息交给每一个绑定的队列,而是根据消息的Routing Key进行判断,只有队列的Routingkey与消息的 Routing key完全一致,才会接收到消息案例需求如下:利用@RabbitListener声明Exchange、Queue、RoutingKey在consumer服务中,编写两个消费者方法,分别监听direct.queue1和direct.queue2在publisher中编写测试方法,向itcast. direct发送消息3.5.1.基于注解声明队列和交换机基于@Bean的方式声明队列和交换机比较麻烦,Spring还提供了基于注解方式来声明。在consumer的SpringRabbitListener中添加两个消费者,同时基于注解来声明队列和交换机:@RabbitListener(bindings = @QueueBinding( value = @Queue(name = "direct.queue1"), exchange = @Exchange(name = "itcast.direct", type = ExchangeTypes.DIRECT), key = {"red", "blue"} )) public void listenDirectQueue1(String msg){ System.out.println("消费者接收到direct.queue1的消息:【" + msg + "】"); } @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "direct.queue2"), exchange = @Exchange(name = "itcast.direct", type = ExchangeTypes.DIRECT), key = {"red", "yellow"} )) public void listenDirectQueue2(String msg){ System.out.println("消费者接收到direct.queue2的消息:【" + msg + "】"); }3.5.2.消息发送在publisher服务的SpringAmqpTest类中添加测试方法:@Test public void testSendDirectExchange() { // 交换机名称 String exchangeName = "itcast.direct"; // 消息 String message = "红色警报!日本乱排核废水,导致海洋生物变异,惊现哥斯拉!"; // 发送消息 rabbitTemplate.convertAndSend(exchangeName, "red", message); }3.5.3.总结描述下Direct交换机与Fanout交换机的差异?Fanout交换机将消息路由给每一个与之绑定的队列Direct交换机根据RoutingKey判断路由给哪个队列如果多个队列具有相同的RoutingKey,则与Fanout功能类似基于@RabbitListener注解声明队列和交换机有哪些常见注解?@Queue@Exchange3.6.Topic3.6.1.说明Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。只不过Topic类型Exchange可以让队列在绑定Routing key 的时候使用通配符!Routingkey 一般都是有一个或多个单词组成,多个单词之间以”.”分割,例如: item.insert通配符规则:#:匹配一个或多个词*:匹配不多不少恰好1个词举例:item.#:能够匹配item.spu.insert 或者 item.spuitem.*:只能匹配item.spu 图示:解释:Queue1:绑定的是china.# ,因此凡是以 china.开头的routing key 都会被匹配到。包括china.news和china.weatherQueue2:绑定的是#.news ,因此凡是以 .news结尾的 routing key 都会被匹配。包括china.news和japan.news案例需求:实现思路如下:并利用@RabbitListener声明Exchange、Queue、RoutingKey在consumer服务中,编写两个消费者方法,分别监听topic.queue1和topic.queue2在publisher中编写测试方法,向itcast. topic发送消息3.6.2.消息发送在publisher服务的SpringAmqpTest类中添加测试方法:/** * topicExchange */ @Test public void testSendTopicExchange() { // 交换机名称 String exchangeName = "itcast.topic"; // 消息 String message = "喜报!孙悟空大战哥斯拉,胜!"; // 发送消息 rabbitTemplate.convertAndSend(exchangeName, "china.news", message); }3.6.3.消息接收在consumer服务的SpringRabbitListener中添加方法:@RabbitListener(bindings = @QueueBinding( value = @Queue(name = "topic.queue1"), exchange = @Exchange(name = "itcast.topic", type = ExchangeTypes.TOPIC), key = "china.#" )) public void listenTopicQueue1(String msg){ System.out.println("消费者接收到topic.queue1的消息:【" + msg + "】"); } @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "topic.queue2"), exchange = @Exchange(name = "itcast.topic", type = ExchangeTypes.TOPIC), key = "#.news" )) public void listenTopicQueue2(String msg){ System.out.println("消费者接收到topic.queue2的消息:【" + msg + "】"); }3.6.4.总结描述下Direct交换机与Topic交换机的差异?Topic交换机接收的消息RoutingKey必须是多个单词,以 **.** 分割Topic交换机与队列绑定时的bindingKey可以指定通配符#:代表0个或多个词*:代表1个词3.7.消息转换器之前说过,Spring会把你发送的消息序列化为字节发送给MQ,接收消息的时候,还会把字节反序列化为Java对象。只不过,默认情况下Spring采用的序列化方式是JDK序列化。众所周知,JDK序列化存在下列问题:数据体积过大有安全漏洞可读性差我们来测试一下。3.7.1.测试默认转换器我们修改消息发送的代码,发送一个Map对象:@Test public void testSendMap() throws InterruptedException { // 准备消息 Map<String,Object> msg = new HashMap<>(); msg.put("name", "Jack"); msg.put("age", 21); // 发送消息 rabbitTemplate.convertAndSend("simple.queue","", msg); }停止consumer服务发送消息后查看控制台:3.7.2.配置JSON转换器显然,JDK序列化方式并不合适。我们希望消息体的体积更小、可读性更高,因此可以使用JSON方式来做序列化和反序列化。在publisher和consumer两个服务中都引入依赖:<dependency> <groupId>com.fasterxml.jackson.dataformat</groupId> <artifactId>jackson-dataformat-xml</artifactId> <version>2.9.10</version> </dependency>配置消息转换器。在启动类中添加一个Bean即可:@Bean public MessageConverter jsonMessageConverter(){ return new Jackson2JsonMessageConverter(); }
RabbitMQ基本使用 RabbitMQ1.初识MQ1.1.同步和异步通讯微服务间通讯有同步和异步两种方式:同步通讯:就像打电话,需要实时响应。异步通讯:就像发邮件,不需要马上回复。两种方式各有优劣,打电话可以立即得到响应,但是你却不能跟多个人同时通话。发送邮件可以同时与多个人收发邮件,但是往往响应会有延迟。1.1.1.同步通讯我们之前学习的Feign调用就属于同步方式,虽然调用可以实时得到结果,但存在下面的问题:总结:同步调用的优点:时效性较强,可以立即得到结果同步调用的问题:耦合度高性能和吞吐能力下降有额外的资源消耗有级联失败问题1.1.2.异步通讯异步调用则可以避免上述问题:我们以购买商品为例,用户支付后需要调用订单服务完成订单状态修改,调用物流服务,从仓库分配响应的库存并准备发货。在事件模式中,支付服务是事件发布者(publisher),在支付完成后只需要发布一个支付成功的事件(event),事件中带上订单id。订单服务和物流服务是事件订阅者(Consumer),订阅支付成功的事件,监听到事件后完成自己业务即可。为了解除事件发布者与订阅者之间的耦合,两者并不是直接通信,而是有一个中间人(Broker)。发布者发布事件到Broker,不关心谁来订阅事件。订阅者从Broker订阅事件,不关心谁发来的消息。Broker 是一个像数据总线一样的东西,所有的服务要接收数据和发送数据都发到这个总线上,这个总线就像协议一样,让服务间的通讯变得标准和可控。好处:吞吐量提升:无需等待订阅者处理完成,响应更快速故障隔离:服务没有直接调用,不存在级联失败问题调用间没有阻塞,不会造成无效的资源占用耦合度极低,每个服务都可以灵活插拔,可替换流量削峰:不管发布事件的流量波动多大,都由Broker接收,订阅者可以按照自己的速度去处理事件缺点:架构复杂了,业务没有明显的流程线,不好管理需要依赖于Broker的可靠、安全、性能好在现在开源软件或云平台上 Broker 的软件是非常成熟的,比较常见的一种就是我们今天要学习的MQ技术。1.2.技术对比:MQ,中文是消息队列(MessageQueue),字面来看就是存放消息的队列。也就是事件驱动架构中的Broker。比较常见的MQ实现:ActiveMQRabbitMQRocketMQKafka几种常见MQ的对比: RabbitMQActiveMQRocketMQKafka公司/社区RabbitApache阿里Apache开发语言ErlangJavaJavaScala&Java协议支持AMQP,XMPP,SMTP,STOMPOpenWire,STOMP,REST,XMPP,AMQP自定义协议自定义协议可用性高一般高高单机吞吐量一般差高非常高消息延迟微秒级毫秒级毫秒级毫秒以内消息可靠性高一般高一般追求可用性:Kafka、 RocketMQ 、RabbitMQ追求可靠性:RabbitMQ、RocketMQ追求吞吐能力:RocketMQ、Kafka追求消息低延迟:RabbitMQ、Kafka2.快速入门2.1.安装RabbitMQ安装RabbitMQ,参考课前资料:MQ的基本结构:RabbitMQ中的一些角色:publisher:生产者consumer:消费者exchange个:交换机,负责消息路由queue:队列,存储消息virtualHost:虚拟主机,隔离不同租户的exchange、queue、消息的隔离2.2.RabbitMQ消息模型RabbitMQ官方提供了5个不同的Demo示例,对应了不同的消息模型:2.3.导入Demo工程课前资料提供了一个Demo工程,mq-demo:导入后可以看到结构如下:包括三部分:mq-demo:父工程,管理项目依赖publisher:消息的发送者consumer:消息的消费者2.4.入门案例简单队列模式的模型图:官方的HelloWorld是基于最基础的消息队列模型来实现的,只包括三个角色:publisher:消息发布者,将消息发送到队列queuequeue:消息队列,负责接受并缓存消息consumer:订阅队列,处理队列中的消息2.4.1.publisher实现思路:建立连接创建Channel声明队列发送消息关闭连接和channel代码实现:package cn.itcast.mq.helloworld; import com.rabbitmq.client.Channel; import com.rabbitmq.client.Connection; import com.rabbitmq.client.ConnectionFactory; import org.junit.Test; import java.io.IOException; import java.util.concurrent.TimeoutException; public class PublisherTest { @Test public void testSendMessage() throws IOException, TimeoutException { // 1.建立连接 ConnectionFactory factory = new ConnectionFactory(); // 1.1.设置连接参数,分别是:主机名、端口号、vhost、用户名、密码 factory.setHost("192.168.150.101"); factory.setPort(5672); factory.setVirtualHost("/"); factory.setUsername("itcast"); factory.setPassword("123321"); // 1.2.建立连接 Connection connection = factory.newConnection(); // 2.创建通道Channel Channel channel = connection.createChannel(); // 3.创建队列 String queueName = "simple.queue"; channel.queueDeclare(queueName, false, false, false, null); // 4.发送消息 String message = "hello, rabbitmq!"; channel.basicPublish("", queueName, null, message.getBytes()); System.out.println("发送消息成功:【" + message + "】"); // 5.关闭通道和连接 channel.close(); connection.close(); } }2.4.2.consumer实现代码思路:建立连接创建Channel声明队列订阅消息代码实现:package cn.itcast.mq.helloworld; import com.rabbitmq.client.*; import java.io.IOException; import java.util.concurrent.TimeoutException; public class ConsumerTest { public static void main(String[] args) throws IOException, TimeoutException { // 1.建立连接 ConnectionFactory factory = new ConnectionFactory(); // 1.1.设置连接参数,分别是:主机名、端口号、vhost、用户名、密码 factory.setHost("192.168.150.101"); factory.setPort(5672); factory.setVirtualHost("/"); factory.setUsername("itcast"); factory.setPassword("123321"); // 1.2.建立连接 Connection connection = factory.newConnection(); // 2.创建通道Channel Channel channel = connection.createChannel(); // 3.创建队列 String queueName = "simple.queue"; channel.queueDeclare(queueName, false, false, false, null); // 4.订阅消息 channel.basicConsume(queueName, true, new DefaultConsumer(channel){ @Override public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException { // 5.处理消息 String message = new String(body); System.out.println("接收到消息:【" + message + "】"); } }); System.out.println("等待接收消息。。。。"); } }2.5.总结基本消息队列的消息发送流程:建立connection创建channel利用channel声明队列利用channel向队列发送消息基本消息队列的消息接收流程:建立connection创建channel利用channel声明队列定义consumer的消费行为handleDelivery()利用channel将消费者与队列绑定3.SpringAMQPSpringAMQP是基于RabbitMQ封装的一套模板,并且还利用SpringBoot对其实现了自动装配,使用起来非常方便。SpringAmqp的官方地址:https://spring.io/projects/spring-amqpSpringAMQP提供了三个功能:自动声明队列、交换机及其绑定关系基于注解的监听器模式,异步接收消息封装了RabbitTemplate工具,用于发送消息3.1.Basic Queue 简单队列模型在父工程mq-demo中引入依赖<!--AMQP依赖,包含RabbitMQ--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> </dependency>3.1.1.消息发送首先配置MQ地址,在publisher服务的application.yml中添加配置:spring: rabbitmq: host: 192.168.150.101 # 主机名 port: 5672 # 端口 virtual-host: / # 虚拟主机 username: itcast # 用户名 password: 123321 # 密码然后在publisher服务中编写测试类SpringAmqpTest,并利用RabbitTemplate实现消息发送:package cn.itcast.mq.spring; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.amqp.rabbit.core.RabbitTemplate; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit4.SpringRunner; @RunWith(SpringRunner.class) @SpringBootTest public class SpringAmqpTest { @Autowired private RabbitTemplate rabbitTemplate; @Test public void testSimpleQueue() { // 队列名称 String queueName = "simple.queue"; // 消息 String message = "hello, spring amqp!"; // 发送消息 rabbitTemplate.convertAndSend(queueName, message); } }3.1.2.消息接收首先配置MQ地址,在consumer服务的application.yml中添加配置:spring: rabbitmq: host: 192.168.150.101 # 主机名 port: 5672 # 端口 virtual-host: / # 虚拟主机 username: itcast # 用户名 password: 123321 # 密码然后在consumer服务的cn.itcast.mq.listener包中新建一个类SpringRabbitListener,代码如下:package cn.itcast.mq.listener; import org.springframework.amqp.rabbit.annotation.RabbitListener; import org.springframework.stereotype.Component; @Component public class SpringRabbitListener { @RabbitListener(queues = "simple.queue") public void listenSimpleQueueMessage(String msg) throws InterruptedException { System.out.println("spring 消费者接收到消息:【" + msg + "】"); } }3.1.3.测试启动consumer服务,然后在publisher服务中运行测试代码,发送MQ消息3.2.WorkQueueWork queues,也被称为(Task queues),任务模型。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息。当消息处理比较耗时的时候,可能生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,无法及时处理。此时就可以使用work 模型,多个消费者共同处理消息处理,速度就能大大提高了。3.2.1.消息发送这次我们循环发送,模拟大量消息堆积现象。在publisher服务中的SpringAmqpTest类中添加一个测试方法:/** * workQueue * 向队列中不停发送消息,模拟消息堆积。 */ @Test public void testWorkQueue() throws InterruptedException { // 队列名称 String queueName = "simple.queue"; // 消息 String message = "hello, message_"; for (int i = 0; i < 50; i++) { // 发送消息 rabbitTemplate.convertAndSend(queueName, message + i); Thread.sleep(20); } }3.2.2.消息接收要模拟多个消费者绑定同一个队列,我们在consumer服务的SpringRabbitListener中添加2个新的方法:@RabbitListener(queues = "simple.queue") public void listenWorkQueue1(String msg) throws InterruptedException { System.out.println("消费者1接收到消息:【" + msg + "】" + LocalTime.now()); Thread.sleep(20); } @RabbitListener(queues = "simple.queue") public void listenWorkQueue2(String msg) throws InterruptedException { System.err.println("消费者2........接收到消息:【" + msg + "】" + LocalTime.now()); Thread.sleep(200); }注意到这个消费者sleep了1000秒,模拟任务耗时。3.2.3.测试启动ConsumerApplication后,在执行publisher服务中刚刚编写的发送测试方法testWorkQueue。可以看到消费者1很快完成了自己的25条消息。消费者2却在缓慢的处理自己的25条消息。也就是说消息是平均分配给每个消费者,并没有考虑到消费者的处理能力。这样显然是有问题的。3.2.4.能者多劳在spring中有一个简单的配置,可以解决这个问题。我们修改consumer服务的application.yml文件,添加配置:spring: rabbitmq: listener: simple: prefetch: 1 # 每次只能获取一条消息,处理完成才能获取下一个消息3.2.5.总结Work模型的使用:多个消费者绑定到一个队列,同一条消息只会被一个消费者处理通过设置prefetch来控制消费者预取的消息数量3.3.发布/订阅发布订阅的模型如图:可以看到,在订阅模型中,多了一个exchange角色,而且过程略有变化:Publisher:生产者,也就是要发送消息的程序,但是不再发送到队列中,而是发给X(交换机)Exchange:交换机,图中的X。一方面,接收生产者发送的消息。另一方面,知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。Exchange有以下3种类型:Fanout:广播,将消息交给所有绑定到交换机的队列Direct:定向,把消息交给符合指定routing key 的队列Topic:通配符,把消息交给符合routing pattern(路由模式) 的队列Consumer:消费者,与以前一样,订阅队列,没有变化Queue:消息队列也与以前一样,接收消息、缓存消息。Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!3.4.FanoutFanout,英文翻译是扇出,我觉得在MQ中叫广播更合适。在广播模式下,消息发送流程是这样的:1) 可以有多个队列2) 每个队列都要绑定到Exchange(交换机)3) 生产者发送的消息,只能发送到交换机,交换机来决定要发给哪个队列,生产者无法决定4) 交换机把消息发送给绑定过的所有队列5) 订阅队列的消费者都能拿到消息我们的计划是这样的:创建一个交换机 itcast.fanout,类型是Fanout创建两个队列fanout.queue1和fanout.queue2,绑定到交换机itcast.fanout3.4.1.声明队列和交换机Spring提供了一个接口Exchange,来表示所有不同类型的交换机:在consumer中创建一个类,声明队列和交换机:package cn.itcast.mq.config; import org.springframework.amqp.core.Binding; import org.springframework.amqp.core.BindingBuilder; import org.springframework.amqp.core.FanoutExchange; import org.springframework.amqp.core.Queue; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class FanoutConfig { /** * 声明交换机 * @return Fanout类型交换机 */ @Bean public FanoutExchange fanoutExchange(){ return new FanoutExchange("itcast.fanout"); } /** * 第1个队列 */ @Bean public Queue fanoutQueue1(){ return new Queue("fanout.queue1"); } /** * 绑定队列和交换机 */ @Bean public Binding bindingQueue1(Queue fanoutQueue1, FanoutExchange fanoutExchange){ return BindingBuilder.bind(fanoutQueue1).to(fanoutExchange); } /** * 第2个队列 */ @Bean public Queue fanoutQueue2(){ return new Queue("fanout.queue2"); } /** * 绑定队列和交换机 */ @Bean public Binding bindingQueue2(Queue fanoutQueue2, FanoutExchange fanoutExchange){ return BindingBuilder.bind(fanoutQueue2).to(fanoutExchange); } }3.4.2.消息发送在publisher服务的SpringAmqpTest类中添加测试方法:@Test public void testFanoutExchange() { // 队列名称 String exchangeName = "itcast.fanout"; // 消息 String message = "hello, everyone!"; rabbitTemplate.convertAndSend(exchangeName, "", message); }3.4.3.消息接收在consumer服务的SpringRabbitListener中添加两个方法,作为消费者:@RabbitListener(queues = "fanout.queue1") public void listenFanoutQueue1(String msg) { System.out.println("消费者1接收到Fanout消息:【" + msg + "】"); } @RabbitListener(queues = "fanout.queue2") public void listenFanoutQueue2(String msg) { System.out.println("消费者2接收到Fanout消息:【" + msg + "】"); }3.4.4.总结交换机的作用是什么?接收publisher发送的消息将消息按照规则路由到与之绑定的队列不能缓存消息,路由失败,消息丢失FanoutExchange的会将消息路由到每个绑定的队列声明队列、交换机、绑定关系的Bean是什么?QueueFanoutExchangeBinding3.5.Direct在Fanout模式中,一条消息,会被所有订阅的队列都消费。但是,在某些场景下,我们希望不同的消息被不同的队列消费。这时就要用到Direct类型的Exchange。在Direct模型下:队列与交换机的绑定,不能是任意绑定了,而是要指定一个RoutingKey(路由key)消息的发送方在 向 Exchange发送消息时,也必须指定消息的 RoutingKey。Exchange不再把消息交给每一个绑定的队列,而是根据消息的Routing Key进行判断,只有队列的Routingkey与消息的 Routing key完全一致,才会接收到消息案例需求如下:利用@RabbitListener声明Exchange、Queue、RoutingKey在consumer服务中,编写两个消费者方法,分别监听direct.queue1和direct.queue2在publisher中编写测试方法,向itcast. direct发送消息3.5.1.基于注解声明队列和交换机基于@Bean的方式声明队列和交换机比较麻烦,Spring还提供了基于注解方式来声明。在consumer的SpringRabbitListener中添加两个消费者,同时基于注解来声明队列和交换机:@RabbitListener(bindings = @QueueBinding( value = @Queue(name = "direct.queue1"), exchange = @Exchange(name = "itcast.direct", type = ExchangeTypes.DIRECT), key = {"red", "blue"} )) public void listenDirectQueue1(String msg){ System.out.println("消费者接收到direct.queue1的消息:【" + msg + "】"); } @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "direct.queue2"), exchange = @Exchange(name = "itcast.direct", type = ExchangeTypes.DIRECT), key = {"red", "yellow"} )) public void listenDirectQueue2(String msg){ System.out.println("消费者接收到direct.queue2的消息:【" + msg + "】"); }3.5.2.消息发送在publisher服务的SpringAmqpTest类中添加测试方法:@Test public void testSendDirectExchange() { // 交换机名称 String exchangeName = "itcast.direct"; // 消息 String message = "红色警报!日本乱排核废水,导致海洋生物变异,惊现哥斯拉!"; // 发送消息 rabbitTemplate.convertAndSend(exchangeName, "red", message); }3.5.3.总结描述下Direct交换机与Fanout交换机的差异?Fanout交换机将消息路由给每一个与之绑定的队列Direct交换机根据RoutingKey判断路由给哪个队列如果多个队列具有相同的RoutingKey,则与Fanout功能类似基于@RabbitListener注解声明队列和交换机有哪些常见注解?@Queue@Exchange3.6.Topic3.6.1.说明Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。只不过Topic类型Exchange可以让队列在绑定Routing key 的时候使用通配符!Routingkey 一般都是有一个或多个单词组成,多个单词之间以”.”分割,例如: item.insert通配符规则:#:匹配一个或多个词*:匹配不多不少恰好1个词举例:item.#:能够匹配item.spu.insert 或者 item.spuitem.*:只能匹配item.spu 图示:解释:Queue1:绑定的是china.# ,因此凡是以 china.开头的routing key 都会被匹配到。包括china.news和china.weatherQueue2:绑定的是#.news ,因此凡是以 .news结尾的 routing key 都会被匹配。包括china.news和japan.news案例需求:实现思路如下:并利用@RabbitListener声明Exchange、Queue、RoutingKey在consumer服务中,编写两个消费者方法,分别监听topic.queue1和topic.queue2在publisher中编写测试方法,向itcast. topic发送消息3.6.2.消息发送在publisher服务的SpringAmqpTest类中添加测试方法:/** * topicExchange */ @Test public void testSendTopicExchange() { // 交换机名称 String exchangeName = "itcast.topic"; // 消息 String message = "喜报!孙悟空大战哥斯拉,胜!"; // 发送消息 rabbitTemplate.convertAndSend(exchangeName, "china.news", message); }3.6.3.消息接收在consumer服务的SpringRabbitListener中添加方法:@RabbitListener(bindings = @QueueBinding( value = @Queue(name = "topic.queue1"), exchange = @Exchange(name = "itcast.topic", type = ExchangeTypes.TOPIC), key = "china.#" )) public void listenTopicQueue1(String msg){ System.out.println("消费者接收到topic.queue1的消息:【" + msg + "】"); } @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "topic.queue2"), exchange = @Exchange(name = "itcast.topic", type = ExchangeTypes.TOPIC), key = "#.news" )) public void listenTopicQueue2(String msg){ System.out.println("消费者接收到topic.queue2的消息:【" + msg + "】"); }3.6.4.总结描述下Direct交换机与Topic交换机的差异?Topic交换机接收的消息RoutingKey必须是多个单词,以 **.** 分割Topic交换机与队列绑定时的bindingKey可以指定通配符#:代表0个或多个词*:代表1个词3.7.消息转换器之前说过,Spring会把你发送的消息序列化为字节发送给MQ,接收消息的时候,还会把字节反序列化为Java对象。只不过,默认情况下Spring采用的序列化方式是JDK序列化。众所周知,JDK序列化存在下列问题:数据体积过大有安全漏洞可读性差我们来测试一下。3.7.1.测试默认转换器我们修改消息发送的代码,发送一个Map对象:@Test public void testSendMap() throws InterruptedException { // 准备消息 Map<String,Object> msg = new HashMap<>(); msg.put("name", "Jack"); msg.put("age", 21); // 发送消息 rabbitTemplate.convertAndSend("simple.queue","", msg); }停止consumer服务发送消息后查看控制台:3.7.2.配置JSON转换器显然,JDK序列化方式并不合适。我们希望消息体的体积更小、可读性更高,因此可以使用JSON方式来做序列化和反序列化。在publisher和consumer两个服务中都引入依赖:<dependency> <groupId>com.fasterxml.jackson.dataformat</groupId> <artifactId>jackson-dataformat-xml</artifactId> <version>2.9.10</version> </dependency>配置消息转换器。在启动类中添加一个Bean即可:@Bean public MessageConverter jsonMessageConverter(){ return new Jackson2JsonMessageConverter(); } -
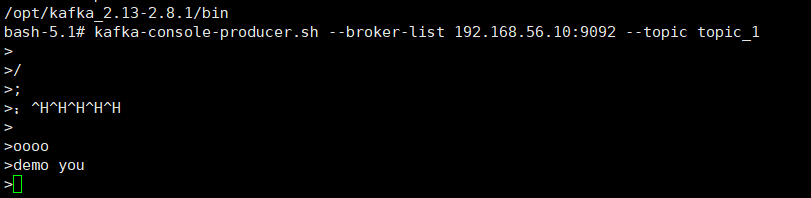
Kafka内外网隔离配置及安装使用 环境版本说明环境:CentOS7版本:JDK1.8、Zookeeper-3.4.14、Kafka2.12-1.0.2JDK安装JDK1.8安装rpm -ivh jdk-8u261-linux-x64.rpm环境变量配置vim /etc/profile最后一行加上配置export JAVA_HOME=/usr/java/jdk1.8.0_261-amd64 export PATH=$PATH:$JAVA_HOME/binjdk验证java -versionZookeeper安装安装tar -zxf zookeeper-3.4.14.tar.gz -C /opt环境变量配置vim /etc/profileZOOKEEPER_PREFIX指向Zookeeper的解压目录export ZOOKEEPER_PREFIX=/opt/zookeeper-3.4.14将Zookeeper的bin目录添加到PATH中export PATH=$PATH:$ZOOKEEPER_PREFIX/bin设置环境变量ZOO_LOG_DIR,指定Zookeeper保存日志的位置export ZOO_LOG_DIR=/var/zookeeper/log使配置生效source /etc/profile修改zookeeper配置cd conf cp zoo_sample.cfg zoo.cfg修改配置文件zoo.cfgvi zoo.cfg修改zookeeper数据存放位置配置修改前dataDir=/tmp/zookeeper修改后dataDir=/var/zookeeper/data启动zookeeper进入zookeeper安装目录=/var/zookeeper/bin启动zookeeperzkServer.sh start查看zookeeper状态zkServer.sh statusKafka安装安装kafkatar -zxf kafka_2.12-1.0.2.tgz -C /opt修改环境变量vi /etc/profile最后加上配置export KAFKA_HOME=/opt/kafka_2.12-1.0.2 export PATH=$PATH:$KAFKA_HOME/bin使配置生效source /etc/profile修改kafka配置修改server.properties配置文件vi server.properties修改链接zookeeper地址:123行修改前zookeeper.connect=localhost:2181修改后zookeeper.connect=localhost:2181/mykafka说明:表示在zookeeper目录下会创建一个mykafka节点修改消息持久化目录:60行修改前log.dirs=/tmp/kafka-logs修改后log.dirs=/var/kafka/kafka-logs创建持久化目录文件夹mkdir -p /var/kafka/kafka-logs脚本说明cd /opt/kafka_2.12-1.0.2/bin说明:kafka-topics.sh 操作主题的 kafka-server-start.sh kafka启动 kafka-server-stop.sh kafka关闭 kafka-console-consumer.sh 命令行里使用消费者 kafka-console-producer.sh 命令行里面使用的生产者启动kafka注意是进入到bin目录下的kafka-server-start.sh ../config/server.properties客户端测试使用zookeeper客户端登录zookeeper,复制启动窗口执行zkCli.sh。(注意:必须复制服务器启动窗口来执行,不然没有脚本。)zkCli.sh查看zookeeper的根节点ls /查看mykafkals /mykafka说明:cluster 集群 controller 控制器 controller_epoch 控制器纪元数据 brokers broker admin 管理者 isr_change_notification 同步的副本 consumers 消费者 log_dir_event_notification log_dir事件通知 latest_producer_id_block 最后一个生产者 config 配置客户端退出zookeeperquit关闭kafkakafka-server-stop.sh主题后台启动kafkakafka-server-start.sh -daemon /opt/kafka_2.12-1.0.2/config/server.properties查看kafka进程信息ps aux | grep kafka主题脚本使用帮助,直接执行脚本,显示主题脚本使用参数。kafka-topics.sh使用参数如下:[root@default-dev bin]# kafka-topics.sh Create, delete, describe, or change a topic. Option Description ------ ----------- --alter Alter the number of partitions, replica assignment, and/or configuration for the topic. --config <String: name=value> A topic configuration override for the topic being created or altered.The following is a list of valid configurations: cleanup.policy compression.type delete.retention.ms file.delete.delay.ms flush.messages flush.ms follower.replication.throttled. replicas index.interval.bytes leader.replication.throttled.replicas max.message.bytes message.format.version message.timestamp.difference.max.ms message.timestamp.type min.cleanable.dirty.ratio min.compaction.lag.ms min.insync.replicas preallocate retention.bytes retention.ms segment.bytes segment.index.bytes segment.jitter.ms segment.ms unclean.leader.election.enable See the Kafka documentation for full details on the topic configs. --create Create a new topic. --delete Delete a topic --delete-config <String: name> A topic configuration override to be removed for an existing topic (see the list of configurations under the --config option). --describe List details for the given topics. --disable-rack-aware Disable rack aware replica assignment --force Suppress console prompts --help Print usage information. --if-exists if set when altering or deleting topics, the action will only execute if the topic exists --if-not-exists if set when creating topics, the action will only execute if the topic does not already exist --list List all available topics. --partitions <Integer: # of partitions> The number of partitions for the topic being created or altered (WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected --replica-assignment <String: A list of manual partition-to-broker broker_id_for_part1_replica1 : assignments for the topic being broker_id_for_part1_replica2 , created or altered. broker_id_for_part2_replica1 : broker_id_for_part2_replica2 , ...> --replication-factor <Integer: The replication factor for each replication factor> partition in the topic being created. --topic <String: topic> The topic to be create, alter or describe. Can also accept a regular expression except for --create option --topics-with-overrides if set when describing topics, only show topics that have overridden configs --unavailable-partitions if set when describing topics, only show partitions whose leader is not available --under-replicated-partitions if set when describing topics, only show under replicated partitions --zookeeper <String: urls> REQUIRED: The connection string for the zookeeper connection in the form host:port. Multiple URLS can be given to allow fail-over. 注意:REQUIRED为必选参数,如上面的--zookeeper链接地址。查看所有可用主题kafka-topics.sh --zookeeper localhost:2181/mykafka --list创建主题kafka-topics.sh --zookeeper localhost/mykafka --create --topic topic_1 --partitions 1 --replication-factor 1说明:zookeeper端口可省略,使用的是默认的。--topic: 创建主题名字--partitions:创建几个分区,便于横向扩展。--replication-factor:一个分区创建几个副本,高可用。注意:当只有一个服务一个broker时,是没有意义的,当服务宕机了,数据也没了。因此--replication-factor副本必须在不同的kafka服务器上,才能实现高可用。再次查看可用主题kafka-topics.sh --zookeeper localhost:2181/mykafka --list查看主题详细信息kafka-topics.sh --zookeeper localhost/mykafka --describe --topic topic_1说明:topic_1有一个0号分区,在0号服务器上。实例创建一个topc_2主题,5个分区,每个分区1个副本.kafka-topics.sh --zookeeper localhost/mykafka --create --topic topic_2 --partitions 5 --replication-factor 1查看可用主题kafka-topics.sh --zookeeper localhost:2181/mykafka --list查看topic_2主题详情kafka-topics.sh --zookeeper localhost/mykafka --describe --topic topic_2说明:5个分区都在0号服务器上。消费消费脚本使用帮助:kafka-console-consumer.sh使用参数:The console consumer is a tool that reads data from Kafka and outputs it to standard output. Option Description ------ ----------- --blacklist <String: blacklist> Blacklist of topics to exclude from consumption. --bootstrap-server <String: server to REQUIRED (unless old consumer is connect to> used): The server to connect to. --consumer-property <String: A mechanism to pass user-defined consumer_prop> properties in the form key=value to the consumer. --consumer.config <String: config file> Consumer config properties file. Note that [consumer-property] takes precedence over this config. --csv-reporter-enabled If set, the CSV metrics reporter will be enabled --delete-consumer-offsets If specified, the consumer path in zookeeper is deleted when starting up --enable-systest-events Log lifecycle events of the consumer in addition to logging consumed messages. (This is specific for system tests.) --formatter <String: class> The name of a class to use for formatting kafka messages for display. (default: kafka.tools. DefaultMessageFormatter) --from-beginning If the consumer does not already have an established offset to consume from, start with the earliest message present in the log rather than the latest message. --group <String: consumer group id> The consumer group id of the consumer. --isolation-level <String> Set to read_committed in order to filter out transactional messages which are not committed. Set to read_uncommittedto read all messages. (default: read_uncommitted) --key-deserializer <String: deserializer for key> --max-messages <Integer: num_messages> The maximum number of messages to consume before exiting. If not set, consumption is continual. --metrics-dir <String: metrics If csv-reporter-enable is set, and directory> this parameter isset, the csv metrics will be output here --new-consumer Use the new consumer implementation. This is the default, so this option is deprecated and will be removed in a future release. --offset <String: consume offset> The offset id to consume from (a non- negative number), or 'earliest' which means from beginning, or 'latest' which means from end (default: latest) --partition <Integer: partition> The partition to consume from. Consumption starts from the end of the partition unless '--offset' is specified. --property <String: prop> The properties to initialize the message formatter. --skip-message-on-error If there is an error when processing a message, skip it instead of halt. --timeout-ms <Integer: timeout_ms> If specified, exit if no message is available for consumption for the specified interval. --topic <String: topic> The topic id to consume on. --value-deserializer <String: deserializer for values> --whitelist <String: whitelist> Whitelist of topics to include for consumption. --zookeeper <String: urls> REQUIRED (only when using old consumer): The connection string for the zookeeper connection in the form host:port. Multiple URLS can be given to allow fail-over. REQUIRED:必填参数unless old consumer is used:使用老消费者--bootstrap-server <String: server to REQUIRED (unless old consumer is connect to> used): The server to connect to. only when using old consumer:使用旧消费时使用--zookeeper <String: urls> REQUIRED (only when using old consumer): The connection string for the zookeeper connection in the form host:port. Multiple URLS can be given to allow fail-over.消费者消费链接Kafka服务端,当有多台Kafka时,只需要链接其中一台服务即可。注意,消费者消费端口是9092了。kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic_1说明:--bootstrap-server localhost:9092:指定kafka服务地址端口--topic topic_1:指定消费的主题测试界面像是卡住了,不管。消费者API使用参数配置说明生产生产脚本使用帮助kafka-console-producer.sh使用参数:Read data from standard input and publish it to Kafka. Option Description ------ ----------- --batch-size <Integer: size> Number of messages to send in a single batch if they are not being sent synchronously. (default: 200) --broker-list <String: broker-list> REQUIRED: The broker list string in the form HOST1:PORT1,HOST2:PORT2. --compression-codec [String: The compression codec: either 'none', compression-codec] 'gzip', 'snappy', or 'lz4'.If specified without value, then it defaults to 'gzip' --key-serializer <String: The class name of the message encoder encoder_class> implementation to use for serializing keys. (default: kafka. serializer.DefaultEncoder) --line-reader <String: reader_class> The class name of the class to use for reading lines from standard in. By default each line is read as a separate message. (default: kafka. tools. ConsoleProducer$LineMessageReader) --max-block-ms <Long: max block on The max time that the producer will send> block for during a send request (default: 60000) --max-memory-bytes <Long: total memory The total memory used by the producer in bytes> to buffer records waiting to be sent to the server. (default: 33554432) --max-partition-memory-bytes <Long: The buffer size allocated for a memory in bytes per partition> partition. When records are received which are smaller than this size the producer will attempt to optimistically group them together until this size is reached. (default: 16384) --message-send-max-retries <Integer> Brokers can fail receiving the message for multiple reasons, and being unavailable transiently is just one of them. This property specifies the number of retires before the producer give up and drop this message. (default: 3) --metadata-expiry-ms <Long: metadata The period of time in milliseconds expiration interval> after which we force a refresh of metadata even if we haven't seen any leadership changes. (default: 300000) --old-producer Use the old producer implementation. --producer-property <String: A mechanism to pass user-defined producer_prop> properties in the form key=value to the producer. --producer.config <String: config file> Producer config properties file. Note that [producer-property] takes precedence over this config. --property <String: prop> A mechanism to pass user-defined properties in the form key=value to the message reader. This allows custom configuration for a user- defined message reader. --queue-enqueuetimeout-ms <Integer: Timeout for event enqueue (default: queue enqueuetimeout ms> 2147483647) --queue-size <Integer: queue_size> If set and the producer is running in asynchronous mode, this gives the maximum amount of messages will queue awaiting sufficient batch size. (default: 10000) --request-required-acks <String: The required acks of the producer request required acks> requests (default: 1) --request-timeout-ms <Integer: request The ack timeout of the producer timeout ms> requests. Value must be non-negative and non-zero (default: 1500) --retry-backoff-ms <Integer> Before each retry, the producer refreshes the metadata of relevant topics. Since leader election takes a bit of time, this property specifies the amount of time that the producer waits before refreshing the metadata. (default: 100) --socket-buffer-size <Integer: size> The size of the tcp RECV size. (default: 102400) --sync If set message send requests to the brokers are synchronously, one at a time as they arrive. --timeout <Integer: timeout_ms> If set and the producer is running in asynchronous mode, this gives the maximum amount of time a message will queue awaiting sufficient batch size. The value is given in ms. (default: 1000) --topic <String: topic> REQUIRED: The topic id to produce messages to. --value-serializer <String: The class name of the message encoder encoder_class> implementation to use for serializing values. (default: kafka. serializer.DefaultEncoder) 注意:REQUIRED必填参数生产者链接kafka服务kafka-console-producer.sh --broker-list localhost:9092 --topic topic_1说明:--broker-list:指定broker,如果有很多太kafka服务器,只需要指定2个地址接口,这里只有一台kafka服务器,只指定一个。--topic:指定要发送消息到那个topic主题。此时生产者窗口也像卡住了,说明进入了发送消息界面。生产者API使用参数配置说明消息发送接收测试注意:提示如下信息检查主题名称是否错误WARN [Producer clientId=console-producer] Error while fetching metadata with correlation id 8可查看可用主题:明确消费主题和生产者是否是使用的一个主题。kafka-topics.sh --zookeeper localhost:2181/mykafka --list消息的发送与接受测试结果:注意:当关闭消费者后,生产者继续发送消息,当生产者重新链接后,只能接受到后面生产者重新发送的消息。消费历史消息如果要消费以前的消息可以指定参数--from-beginningkafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic_1 --from-beginning查看持久化数据ca /var/kafka/kafka-logs可以看到很多偏移量的文件。服务端参数配置主要是服务器kafka配置文件server.properties的配置zookeeper.connect该参数用于配置kafka要链接的Zookeeper/集群地址。它的值是一个字符串,使用都好分割zookeeper的多个地址。Zookeeper的单个地址是host:port形式的,可以在最后添加kafka在zookeeper中的根节点路径。例如: zookeeper.connect=192.1681.1:2181,192.1681.2:2181,192.1681.3:2181,192.1681.4:2181/mykafka最好服务器地址数量过半,后面zookeeper存放路径/mykafka写一个就好了。listeners用于指定当前Broker向外发布服务的地址和端口。与advertised.listeners配合,用于做内外网隔离。注意:端口号也是可以修改的。内外网隔离配置listeners用于配置broker监听的URL以及监听器名称列表,使用逗号隔开多个URL及监听器名称。例如:服务器有2个ip,ip如下则配置如下:listeners配置:注意监听器名称不能相同,端口不能相同。PLAINTEXT代表了都使用PLAINTEXT协议,也代表了监听器的名称,但是名称又不能相同,因此使用映射配置参数listner.sercurity.protocol.map。加上上面配置后,启动还是会报错,因此必须加上如下配置:整体说明:注意kafka是使用的PLAINTEXT协议listener.security.protocol.map=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT listeners=INTERNAL://10.0.2.15:9000,EXTERNAL://192.168.56.30:9001 advertised.listeners=EXTERNAL://192.168.56.30:9001 inter.broker.listener.name=EXTERNALlistener.security.protocol.map:解决监听协议、监听器名称一样问题。listeners:集群多台服务地址advertised.listeners:暴露给消费者生产者,以及节点间通讯使用的地址和端口(需要将该地址发布到zookeeper供客户端使用,如果客户端使用的地址与listeners配置不同),而另一个地址端口INTERNAL://10.0.2.15:9000则可用于内部管理kafka。inter.broker.listener.name:暴力给消费者生产者使用监听的监听器名称,如果要暴露多个直接可以逗号隔开多加几个,前提是listeners里面有的。listener.security.protocol.map用于内外网隔离配置,监听器名称和安全协议的映射配置。例如:将内外网隔离,即使他们都使用SSL,上面的配置问题就可以加下面参数解决。listener.security.protocol.map=INTERNAL:SSL,EXTERNAL:SSL说明:INTERNAL,EXTERNAL:代表监听器名称SSL:代表都是使用SSL协议。加上这个参数配置,就可以解决上面的监听器名称和协议冲突的问题了。注意:每个监听器的名称只能在map中出现一次。如果监听器名称代表的不是安全协议,必须配置listener.security.protocol.map。每个监听器必须使用不同的网络端口。查看zoopeeper信息:客户端脚本链接zookeeper:zkCli.sh查看kafka信息get /mykafka/brokers/ids/0查看可用主题:kafka-topics.sh --zookeeper localhost:2181/mykafka --listbroker.id该属性用于唯一标记一个kafka的Broker,它的值是一个任意integer值。当kafka以分布式集群部署使用时,非常重要。最好该值只跟该Broker所在的物理主机有关的,如主机名为host1.yanxizhu.com,则broker.id=1,如果主机名为192.168.56.30,则broker.id=30.log.dir通过该属性的值,指定kafka在磁盘上保存消息的日志片段的目录。它时一组用逗号分隔的本地文件系统路径。如果指定了多个路径,那么broker会根据”最少使用“原则,把同一个分区的日志片段保存到同一个路径下。broker会往拥有最少数目分区的路径新增分区,而不是往拥有最小磁盘空间的路径新增分区。
-
docker部署kafka Docker部署Kafka一、拉取镜像docker pull wurstmeister/zookeeper docker pull wurstmeister/kafka二、启动zookpeerdocker run -d --name zookeeper -p 2181:2181 -t wurstmeister/zookeeper三、启动kafkadocker run -d --name kafka \ -p 9092:9092 \ -e KAFKA_BROKER_ID=0 \ -e KAFKA_ZOOKEEPER_CONNECT=192.168.56.10:2181 \ -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.56.10:9092 \ -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 wurstmeister/kafka注意修改自己ip地址四、测试1、进入kafka容器docker exec -it kafka bash2、进入kafak脚本目录cd /opt/kafka_2.13-2.8.1/bin注意修改自己kafka版本3、创建主题kafka-topics.sh --create --zookeeper 192.168.56.10:2181 --replication-factor 1 --partitions 1 --topic topic_1 这里创建了一个topic_1主题。4、添加消息生产者发送消息kafka-console-producer.sh --broker-list 192.168.56.10:9092 --topic topic_1此时进入发送消息界面:5、消费消息消费者消费消息kafka-console-consumer.sh --bootstrap-server 192.168.56.10:9092 --topic topic_1 --from-beginning测试进入消费消息窗口:
-
MyCat的安装及使用 MyCat的安装及使用一、MyCat的安装1、环境准备 本次课程使用的虚拟机环境是centos6.5,首先准备四台虚拟机,安装好mysql,方便后续做读写分离和主从复制。192.168.85.111 node01 192.168.85.112 node02 192.168.85.113 node03 192.168.85.114 node04 安装jdk 使用rpm的方式直接安装jdk,配置好具体的环境变量2、安装 从官网下载需要的安装包,并且上传到具体的虚拟机中,我们在使用的时候将包上传到node01这台虚拟机,由node01充当MyCat。 下载地址为:http://dl.mycat.org.cn/1.6.7.5/2020-4-10/解压文件到/usr/local文件夹下tar -zxvf Mycat-server-1.6.7.5-release-20200422133810-linux.tar.gz -C /usr/local配置环境变量vi /etc/profile 添加如下配置信息: export MYCAT_HOME=/usr/local/mycat export PATH=$MYCAT_HOME/bin:$PATH:$JAVA_HOME/bin当执行到这步的时候,其实就可以启动了,但是为了能正确显示出效果,最好修改下MyCat的具体配置,让我们能够正常进行访问。3、配置MyCat 进入到/usr/local/mycat/conf目录下,修改该文件夹下的配置文件1、修改server.xml文件<?xml version="1.0" encoding="UTF-8"?> <!-- - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - - Unless required by applicable law or agreed to in writing, software - distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the License for the specific language governing permissions and - limitations under the License. --> <!DOCTYPE mycat:server SYSTEM "server.dtd"> <mycat:server xmlns:mycat="http://io.mycat/"> <user name="root" defaultAccount="true"> <property name="password">123456</property> <property name="schemas">TESTDB</property> <property name="defaultSchema">TESTDB</property> </user> </mycat:server>2、修改schema.xml文件<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"> </schema> <dataNode name="dn1" dataHost="host1" database="msb" /> <dataHost name="host1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1" url="192.168.85.111:3306" user="root" password="123456"> <readHost host="hostS1" url="192.168.85.112:3306" user="root" password="123456"></readHost> </writeHost> </dataHost> </mycat:schema>4、启动mycat mycat的启动有两种方式,一种是控制台启动,一种是后台启动,在初学的时候建议大家使用控制台启动的方式,当配置文件写错之后,可以方便的看到错误,及时修改,但是在生产环境中,使用后台启动的方式比较稳妥。 控制台启动:去mycat/bin目录下执行 ./mycat console 后台启动:去mycat/bin目录下执行 ./mycat start 按照如上配置在安装的时候应该不会报错,如果出现错误,根据错误的提示解决即可。5、登录验证 管理窗口的登录 从另外的虚拟机去登录访问当前MyCat,输入如下命令即可mysql -uroot -p123456 -P 9066 -h 192.168.85.111 此时访问的是MyCat的管理窗口,可以通过show @@help查看可以执行的命令 数据窗口的登录 从另外的虚拟机去登录访问MyCat,输入命令如下:mysql -uroot -p123456 -P8066 -h 192.168.85.111 当都能够成功的时候以为着mycat已经搭建完成。二、读写分离 通过MyCat和MySQL的主从复制配合搭建数据库的读写分离,可以实现MySQL的高可用性,下面我们来搭建MySQl的读写分离。1、一主一从(主从复制的原理之前讲解过了,需要的同学自行参阅文档)1、在node01上修改/etc/my.cnf的文件#mysql服务唯一id,不同的mysql服务必须拥有全局唯一的id server-id=1 #启动二进制日期 log-bin=mysql-bin #设置不要复制的数据库 binlog-ignore-db=mysql binlog-ignore-db=information-schema #设置需要复制的数据库 binlog-do-db=msb #设置binlog的格式 binlog_format=statement2、在node02上修改/etc/my.cnf文件#服务器唯一id server-id=2 #启动中继日志 relay-log=mysql-relay3、重新启动mysql服务4、在node01上创建账户并授权slavegrant replication slave on *.* to 'root'@'%' identified by '123456'; --在进行授权的时候,如果提示密码的问题,把密码验证取消 set global validate_password_policy=0; set global validate_password_length=1;5、查看master的状态show master status6、在node02上配置需要复制的主机CHANGE MASTER TO MASTER_HOST='192.168.85.111',MASTER_USER='root',MASTER_PASSWORD='123456',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=437;7、启动从服务器复制功能start slave;8、查看从服务器状态show slave status\G 当执行完成之后,会看到两个关键的属性Slave_IO_Running,Slave_SQL_Running,当这两个属性都是yes的时候,表示主从复制已经准备好了,可以进行具体的操作了2、一主一从验证 下面我们通过实际的操作来验证主从复制是否完成。--在node01上创建数据库 create database msb; --在node01上创建具体的表 create table mytbl(id int,name varchar(20)); --在node01上插入数据 insert into mytbl values(1,'zhangsan'); --在node02上验证发现数据已经同步成功,表示主从复制完成 通过MyCat实现读写分离 在node01上插入如下sql语句,-- 把主机名插入数据库中 insert into mytbl values(2,@@hostname); -- 然后通过mycat进行数据的访问,这个时候大家发现无论怎么查询数据,最终返回的都是node01的数据,为什么呢? select * from mytbl; 在之前的mycat基本配置中,其实我们已经配置了读写分离,大家还记得readHost和writeHost两个标签吗?<writeHost host="hostM1" url="192.168.85.111:3306" user="root" password="123456"> <readHost host="hostS1" url="192.168.85.112:3306" user="root" password="123456"></readHost> </writeHost> 其实我们已经配置过了这两个标签,默认情况下node01是用来完成写入操作的,node02是用来完成读取操作的,但是刚刚通过我们的验证发现所有的读取都是node01完成的,这是什么原因呢? 原因很简单,就是因为我们在进行配置的时候在 dataHost 标签中缺失了一个非常重要的属性balance,此属性有四个值,用来做负载均衡的,下面我们来详细介绍 1、balance=0 :不开启读写分离机制,所有读操作都发送到当前可用的writehost上 2、balance=1:全部的readhost和stand by writehost参与select 语句的负载均衡,简单的说,当双主双从模式下,其他的节点都参与select语句的负载均衡 3、balance=2:所有读操作都随机的在writehost,readhost上分发 4、balance=3:所有读请求随机的分发到readhost执行,writehost不负担读压力 当了解了这个参数的含义之后,我们可以将此参数设置为2,就能够看到在两个主机上切换执行了。3、双主双从 在上述的一主一从的架构设计中,很容易出现单点的问题,所以我们要想让生产环境中的配置足够稳定,可以配置双主双从,解决单点的问题。 架构图如下所示: 在此架构中,可以让一台主机用来处理所有写请求,此时,它的从机和备机,以及备机的从机复制所有读请求,当主机宕机之后,另一台主机负责写请求,两台主机互为备机。 主机分布如下:编号角色ip主机名1master1192.168.85.111node012slave1192.168.85.112node023master2192.168.85.113node034slave2192.168.85.114node04 下面开始搭建双主双从。 1、修改node01上的/etc/my.cnf文件#主服务器唯一ID server-id=1 #启用二进制日志 log-bin=mysql-bin # 设置不要复制的数据库(可设置多个) binlog-ignore-db=mysql binlog-ignore-db=information_schema #设置需要复制的数据库 binlog-do-db=msb #设置logbin格式 binlog_format=STATEMENT # 在作为从数据库的时候, 有写入操作也要更新二进制日志文件 log-slave-updates #表示自增长字段每次递增的量,指自增字段的起始值,其默认值是1, 取值范围是1 .. 65535 auto-increment-increment=2 # 表示自增长字段从哪个数开始,指字段一次递增多少,他的取值范围是1 .. 65535 auto-increment-offset=1 2、修改node03上的/etc/my.cnf文件#主服务器唯一ID server-id=3 #启用二进制日志 log-bin=mysql-bin # 设置不要复制的数据库(可设置多个) binlog-ignore-db=mysql binlog-ignore-db=information_schema #设置需要复制的数据库 binlog-do-db=msb #设置logbin格式 binlog_format=STATEMENT # 在作为从数据库的时候,有写入操作也要更新二进制日志文件 log-slave-updates #表示自增长字段每次递增的量,指自增字段的起始值,其默认值是1,取值范围是1 .. 65535 auto-increment-increment=2 # 表示自增长字段从哪个数开始,指字段一次递增多少,他的取值范围是1 .. 65535 auto-increment-offset=2 3、修改node02上的/etc/my.cnf文件#从服务器唯一ID server-id=2 #启用中继日志 relay-log=mysql-relay 4、修改node04上的/etc/my.cnf文件#从服务器唯一ID server-id=4 #启用中继日志 relay-log=mysql-relay 5、所有主机重新启动mysql服务 6、在两台主机node01,node03上授权同步命令GRANT REPLICATION SLAVE ON *.* TO 'root'@'%' IDENTIFIED BY '123456'; 7、查看两台主机的状态show master status; 8、在node02上执行要复制的主机CHANGE MASTER TO MASTER_HOST='192.168.85.111',MASTER_USER='root',MASTER_PASSWORD='123456',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=154; 9、在node04上执行要复制的主机CHANGE MASTER TO MASTER_HOST='192.168.85.113',MASTER_USER='root',MASTER_PASSWORD='123456',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=154; 10、启动两个从机的slave并且查看状态,当看到两个参数都是yes的时候表示成功start slave; show slave status; 11、完成node01跟node03的相互复制--在node01上执行 CHANGE MASTER TO MASTER_HOST='192.168.85.113',MASTER_USER='root',MASTER_PASSWORD='123456',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=442; --开启slave start slave --查看状态 show slave status\G --在node03上执行 CHANGE MASTER TO MASTER_HOST='192.168.85.111',MASTER_USER='root',MASTER_PASSWORD='123456',MASTER_LOG_FILE='mysql-bin.000002',MASTER_LOG_POS=442; --开启slave start slave --查看状态 show slave status\G4、双主双从验证在node01上执行如下sql语句:create database msb; create table mytbl(id int,name varchar(20)); insert into mytbl values(1,'zhangsan'); --完成上述命令之后可以去其他机器验证是否同步成功 当上述操作完成之后,我们可以验证mycat的读写分离,此时我们需要进行重新的配置,修改schema.xml文件。 在当前mysql架构中,我们使用的是双主双从的架构,因此可以将balance设置为1 除此之外我们需要注意,还需要了解一些参数: 参数writeType,表示写操作发送到哪台机器,此参数有两个值可以进行设置: writeType=0:所有写操作都发送到配置的第一个writeHost,第一个挂了切换到还生存的第二个 writeType=1:所有写操作都随机的发送到配置的writehost中,1.5之后废弃, 需要注意的是:writehost重新启动之后以切换后的为准,切换记录在配置文件dnindex.properties中 参数switchType:表示如何进行切换: switchType=1:默认值,自动切换 switchType=-1:表示不自动切换 switchType=2:基于mysql主从同步的状态决定是否切换<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"> </schema> <dataNode name="dn1" dataHost="host1" database="msb" /> <dataHost name="host1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1" url="192.168.85.111:3306" user="root" password="123456"> <readHost host="hostS1" url="192.168.85.112:3306" user="root" password="123456"></readHost> </writeHost> <writeHost host="hostM2" url="192.168.85.113:3306" user="root" password="123456"> <readHost host="hostS2" url="192.168.85.114:3306" user="root" password="123456"></readHost> </writeHost> </dataHost> </mycat:schema> 下面开始进行读写分离的验证--插入以下语句,使数据不一致 insert into mytbl values(2,@@hostname); --通过查询mycat表中的数据,发现查询到的结果在node02,node03,node04之间切换,符合正常情况 select * from mytbl; --停止node01的mysql服务 service mysqld stop --重新插入语句 insert into mytbl values(3,@@hostname); --开启node01的mysql服务 service mysqld start --执行相同的查询语句,此时发现在noede01,node02,node04之间切换,符合情况 通过上述的验证,我们可以得到一个结论,node01,node03互做备机,负责写的宕机切换,其他机器充作读请求的响应。 做到此处,希望大家能够思考一个问题,在上述我们做的读写分离操作,其实都是基于主从复制的,也就是数据同步,但是在生产环境中会存在很多种情况造成主从复制延迟问题,那么我们应该如何解决延迟问题,这是一个值得思考的问题,到底如何解决呢?三、数据切分 数据切分指的是通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库上面,以达到分散单台设备负载的效果。 数据的切分根据其切分规则的类型,可以分为两种切分模式。一种是按照不同的表来切分到不同的数据库之上,这种切可以称之为数据的垂直切分或者纵向切分,另外一种则是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库上面,这种切分称之为数据的水平切分或者横向切分。 垂直切分的最大特点就是 规则简单,实施也更为方便,尤其适合各业务之间的耦合度非常低,相互影响很小,业务逻辑非常清晰的系统。在这种系统中,可以很容易做到将不同业务模块所使用的表分拆到不同的数据库中。根据不同的表来进行拆分,对应用程序的影响也很小,拆分规则也会比较简单清晰。 水平切分与垂直切分相比,相对来说稍微复杂一些。因为要将同一个表中的不同数据拆分到不同的数据库中,对于应用程序来说,拆分规则本身就较根据表明来拆分更为复杂,后期的数据维护也会更为复杂一些。1、垂直切分 一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同的数据库上面,这样也就将数据或者压力分担到不同的库上面。 如上图所示,一个系统被切分成了用户系统、订单交易、支付系统等多个库。 一个架构设计较好的应用系统,其总体功能肯定是又多个功能模块所组成的。而每一个功能模块所需要的数据对应到数据库中就是一个或者多个表。而在架构设计中,各个功能模块相关质检的交互点越统一越少,系统的耦合度就越低,系统各个模块的维护性以及扩展性也就越好。这样的系统,实现数据的垂直切分也就越容易。 但是往往系统中有些表难以做到完全的独立,存在着跨库join的情况,对于这类的表,就需要去做平衡,是数据让步业务,共用一个数据源还是分成多个库,业务之间通过接口来做调用。在系统初期,数据量比较少,或者资源有限的情况下,会选择共用数据源,但是当数据发展到一定规模,负载很大的情况下就必须要做分割。 一般来讲业务存在着复杂join的场景是难以切分的,往往业务独立的易于切分。如何切分,切分到何种程度是考验技术架构的一个难题。下面来分析下垂直切分的优缺点: 优点: 1、拆分后业务清晰,拆分规则明确 2、系统之间整合或扩展容易 3、数据维护简单 缺点: 1、部分业务表无法实现join,只能通过接口方式解决,提高了系统复杂度 2、受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高 3、事务处理复杂2、水平切分 相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行切分,就是将表中的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中, 拆分数据就需要定义分片规则。关系型数据库是行列的二维模型,拆分的第一原则是找到拆分维度。比如从会员的角度来分析,商户订单交易类系统中查询会员某天某月某个订单,那么就需要按照会员结合日期来拆分,不同的数据按照会员id做分组,这样所有的数据查询join都会在单库内解决;如果从商户的角度来讲,要查询某个商家某天所有的订单数,就需要按照商户id做拆分;但是如果系统既想按照会员拆分,又想按照商家数据拆分,就会有一定的困难,需要综合考虑找到合适的分片。 几种典型的分片规则包括: 1、按照用户id取模,将数据分散到不同的数据库,具有相同数据用户的数据都被分散到一个库中; 2、按照日期,将不同月甚至日的数据分散到不同的库中; 3、按照某个特定的字段求模,或者根据特定范围段分散到不同的库中。 如图,切分原则都是根据业务找到适合的切分规则分散到不同的库,下图是用用户id求模的案例: 数据做完了水平拆分之后也是有优缺点的。 优点: 1、拆分规则抽象好,join操作基本可以数据库做; 2、不存在单库大数据,高并发的性能瓶颈; 3、应用端改造较少; 4、提高了系统的稳定性跟负载能力 缺点: 1、拆分规则难以抽象 2、分片事务一致性难以解决 3、数据多次扩展跟维护量极大 4、跨库join性能较差3、总结 数据切分的两种方式,会发现每种方式都有自己的缺点,但是他们之间有共同的缺点,分别是: 1、引入了分布式事务的问题 2、跨节点join的问题 3、跨节点合并排序分页的问题 4、多数据源管理的问题 针对数据源管理,目前主要有两种思路: 1、客户端模式,在每个应用程序模块中配置管理自己需要的一个或多个数据源,直接访问各个数据库,在模块内完成数据的整合 2、通过中间代理层来统一管理所有的数据源,后端数据库集群对前端应用程序透明; 在实际的生产环境中,我们都会选择第二种方案来解决问题,尤其是系统不断变得庞大复杂的时候,其实这是非常正确的,虽然短期内付出的成本可能会比较大,但是对整个系统的扩展性来说,是非常有帮助的。 MyCat通过数据切分解决传统数据库的缺陷,又有了nosql易于扩展的优点。通过中间代理层规避了多数据源的数据问题,对应用完全透明,同时对数据切分后存在的问题,也做了解决方案。 MyCat在做数据切分的时候应该尽可能的遵循以下原则,当然这也是经验之谈,最终的落地实现还是要看具体的应用场景在做具体的分析 第一原则:能不切分尽量不要切分 第二原则:如果要切分一定要选择合适的切分规则,提前规划好 第三原则:数据切分尽量通过数据冗余或表分组来降低跨库join的可能 第四原则:由于数据库中间件对数据join实现的优劣难以把握,而且实现高性能难度极大,业务读取尽量少使用多表join。四、MyCat的配置文件讲解 在之前的操作中,我们已经做了部分文件的配置,但是具体的属性并没有讲解,下面我们讲解下每一个配置文件具体的属性以及相关的基本配置。1、搞定schema.xml文件 schema.xml作为MyCat中重要地配置文件之一,管理着MyCat的逻辑库、表、分片规则、DataNode以及DataSource。1、schema标签<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"></schema> schema标签用于定义MyCat实例中的逻辑库,MyCat可以有多个逻辑库,每个逻辑库都有自己相关的配置,可以使用schema标签来划分这些不同的逻辑库。如果不配置schame,那么所有的表配置都将属于同一个默认的逻辑库。 dataNode:该属性用于绑定逻辑库到某个具体的database上。 checkSQLschema:当该值为true时,如果执行select from TESTDB.user,那么MyCat会将语句修改为select from user,即把表示schema的字符去掉,避免发送到后端数据库执行时报错。 sqlMaxLimit:当该值设置为某个数值的时候,每次执行的sql语句,如果没有加上limit语句,MyCat也会自动加上对应的值。例如,当设置值为100的时候,那么select from user的效果跟执行select from user limit 100相同。如果不设置该值的话,MyCat默认会把所有的数据信息都查询出来,造成过多的输出,所以,还是建议设置一个具体的值,以减少过多的数据返回。当然sql语句中可以显式的制定limit的大小,不受该属性的约束。2、table标签<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" ></table> table标签定义了MyCat中的逻辑表,所有需要拆分的表都需要在这个标签中定义。 name:定义逻辑表的表名,这个名字就如同创建表的时候指定的表名一样,同个schema标签中定义的名字必须唯一。 dataNode:定义这个逻辑表所属的dataNode,该属性的值需要和dataNode标签中的name属性值对应,如果需要定义的dn过多,可以使用如下方法减少配置:<table name="travelrecord" dataNode="multipleDn$0-99,multipleDn2$100-199" rule="auto-shardinglong" ></table> <dataNode name="multipleDn$0-99" dataHost="localhost1" database="db$0-99" ></dataNode> <dataNode name="multipleDn2$100-199" dataHost="localhost1" database=" db$100-199" ></dataNode> rule:该属性用于指定逻辑表要使用的规则名字,规则名字在rule.xml中定义,必须与tableRule标签中的name属性值一一对应 ruleRequired:该属性用于指定表是否绑定分片规则,如果配置为true,但没有配置具体rule的话,程序会报错。 primaryKey:该逻辑表对应真实表的主键,例如:分片的规则是使用非主键进行分片的,那么在使用主键查询的时候,就会发送查询语句到所有配置的DN上,如果使用改属性配置真实表的主键。那么MyCat会缓存主键与具体DN的信息,那么再次使用非主键进行查询的时候就不会进行广播式的查询,就会直接发送语句到具体的DN,但是尽管配置改属性,如果缓存没有命中的话,还是会发送语句给具体的DN来获得数据 type:该属性定义了逻辑表的类型,目前逻辑表只有全局表和普通表两种类型。对应的配置: 全局表:global 普通表:不指定该值为global的所有表 autoIncrement:MySQL 对非自增长主键,使用 last_insert_id()是不会返回结果的,只会返回 0。所以,只有定义了自增长主键的表才可以用 last_insert_id()返回主键值。MyCat目前提供了自增长主键功能,但是如果对应的MySQL节点上数据表,没有定义 auto_increment,那么在MyCat层调用 last_insert_id()也是不会返回结果的。由于 insert 操作的时候没有带入分片键, MyCat 会先取下这个表对应的全局序列,然后赋值给分片键。 这样才能正常的插入到数据库中,最后使用 last_insert_id()才会返回插入的分片键值。如果要使用这个功能最好配合使用数据库模式的全局序列。使用 autoIncrement=“true” 指定这个表有使用自增长主键,这样 MyCat才会不抛出分片键找不到的异常。使用 autoIncrement=“false” 来禁用这个功能,当然你也可以直接删除掉这个属性。默认就是禁用的。 needAddLimit:指定表是否需要自动的在每个语句后面加上limit限制。由于使用了分库分表,数据量有时会特别巨大。这时候执行查询语句,如果恰巧又忘记了加上数量限制的话,那么查询所有的数据出来,就会执行很久的时间,所以mycat自动为我们加上了limit 100。当前如果语句中又limit,那么就不会添加了。3、childTable标签 childTable标签用于定义ER分片的子表。通过标签上的属性与父表进行关联。 name:定义子表的表名 joinKey:插入子表的时候会使用这个列的值查找父表存储的数据节点 parentKey:属性指定的值一般为与父表建立关联关系的列名。程序首先获取joinkey的值,再通过parentKey属性指定的列名产生查询语句,通过执行该语句得到父表存储再哪个分片上,从而确定子表存储的位置。 primaryKey:跟table标签所描述相同 needAddLimit:跟table标签所描述相同4、dataNode标签<dataNode name="dn1" dataHost="lch3307" database="db1" ></dataNode> dataNode标签定义了mycat中的数据节点,也就是我们通常说的数据分片,一个dataNode标签就是一个独立的数据分片。 name:定义数据节点的名字,这个名字需要是唯一的,我们需要再table标签上应用这个名字,来建立表与分片对应的关系 dataHost:该属性用于定义该分片属于哪个数据库实例,属性值是引用dataHost标签上定义的name属性。 database:该属性用于定义该分片属性哪个具体数据库实力上的具体库,5、dataHost标签 该标签定义了具体的数据库实例、读写分离配置和心跳语句<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <!-- can have multi write hosts --> <writeHost host="hostM1" url="localhost:3306" user="root" password="123456"> <!-- can have multi read hosts --> <!-- <readHost host="hostS1" url="localhost:3306" user="root" password="123456" /> --> </writeHost> <!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> --> </dataHost> name:唯一标识dataHost标签,供上层的标签使用 maxcon:指定每个读写实例连接池的最大连接 mincon:指定每个读写实例连接连接池的最小链接,初始化连接池的大小 balance:负载均衡类型: 0:不开启读写分离机制,所有读操作都发送到当前可用的writeHost上 1:全部的readHost和stand by writeHost参与select语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且M1与M2互为主备),正常情况下,M2,S1,S2都参与select语句的负载均衡 2:所有读操作都随机的再writeHost、readHost上分发 3:所有读请求随机的分发到writeHost对应readHost执行,writeHost不负担读压力,在之后的版本中失效。 writeType:写类型 writeType=0:所有的写操作发送到配置的第一个writeHost,第一个挂了切换到还生存的第二个writeHost,重启之后以切换后的为准,切换记录保存在配置文件 dnindex.properties writeType=1:所有写操作都随机的发送到配置的writeHost,1.5以后废弃不推荐 dbType:指定后端连接的数据库类型,如MySQL,mongodb,oracle dbDriver:指定连接后端数据库使用的Driver,目前可选的值有native和JDBC。使用native的话,因为这个值执行的是二进制的mysql协议,所以可以使用mysql和maridb,其他类型的数据库则需要使用JDBC驱动来支持。 switchType:是否进行主从切换 -1:表示不自动切换 1:默认值,自动切换 2:基于mysql主从同步的状态决定是否切换6、heartbeat标签 这个标签指明用于和后端数据库进行心跳检测的语句。2、搞定server.xml文件 server.xml几乎保存了所有mycat需要的系统配置信息。<user name="test"> <property name="password">test</property> <property name="schemas">TESTDB</property> <property name="schemas">TESTDB</property> <property name="schemas">TESTDB</property> <property name="schemas">TESTDB</property> <privileges check="false"> <schema name="TESTDB" dml="0010" showTables="custome/mysql"> <table name="tbl_user" dml="0110"></table> <table name="tbl_dynamic" dml="1111"></table> </schema> </privileges> </user> server.xml中的标签本就不多,这个标签主要用于定义登录mycat的用户和权限。 property标签用来声明具体的属性值,name用来指定用户名,password用来修改密码,readonly用来限制用户是否是只读的,schemas用来控制用户课访问的schema,如果有多个的话,用逗号分隔 privileges标签是对用户的schema及下级的table进行精细化的DML控制,privileges节点的check属性适用于标识是否开启DML权限检查,默认false标识不检查,当然不配置等同于不检查 在进行检查的时候,是通过四个二进制位来标识的,insert,update,select,delete按照顺序标识,0表示未检查,1表示要检查 system标签表示系统的相关属性:属性含义备注charset字符集设置utf8,utf8mb4defaultSqlParser指定的默认解析器druidparser,fdbparser(1.4之后作废)processors系统可用的线程数,默认为机器CPU核心线程数processorBufferChunk每次分配socket direct buffer的大小默认是4096个字节processorExecutor指定NIOProcessor共享的businessExecutor固定线程池大小,mycat在处理异步逻辑的时候会把任务提交到这个线程池中 sequnceHandlerTypemycat全局序列的类型0为本地文件,1为数据库方式,2为时间戳方式,3为分布式ZK ID生成器,4为zk递增id生成3、rule.xml rule.xml里面就定义了我们对表进行拆分所涉及到的规则定义。我们可以灵活的对表使用不同的分片算法,或者对表使用相同的算法但具体的参数不同,这个文件里面主要有tableRule和function这两个标签。1、tableRule 这个标签被用来定义表规则,定义的表规则在schema.xml文件中<tableRule name="rule1"> <rule> <columns>id</columns> <algorithm>func1</algorithm> </rule> </tableRule> name属性指定唯一的名字,用来标识不同的表规则 内嵌的rule标签则指定对物理表中的哪一列进行拆分和使用什么路由算法 columns内指定要拆分的列的名字 algorithm使用function标签中的那么属性,连接表规则和具体路由算法。当然,多个表规则可以连接到同一个路由算法上。2、function<function name="hash-int" class="io.mycat.route.function.PartitionByFileMap"> <property name="mapFile">partition-hash-int.txt</property> </function> name指定算法的名字 class指定路由算法具体的类名字 property为具体算法需要用到的一些属性
-
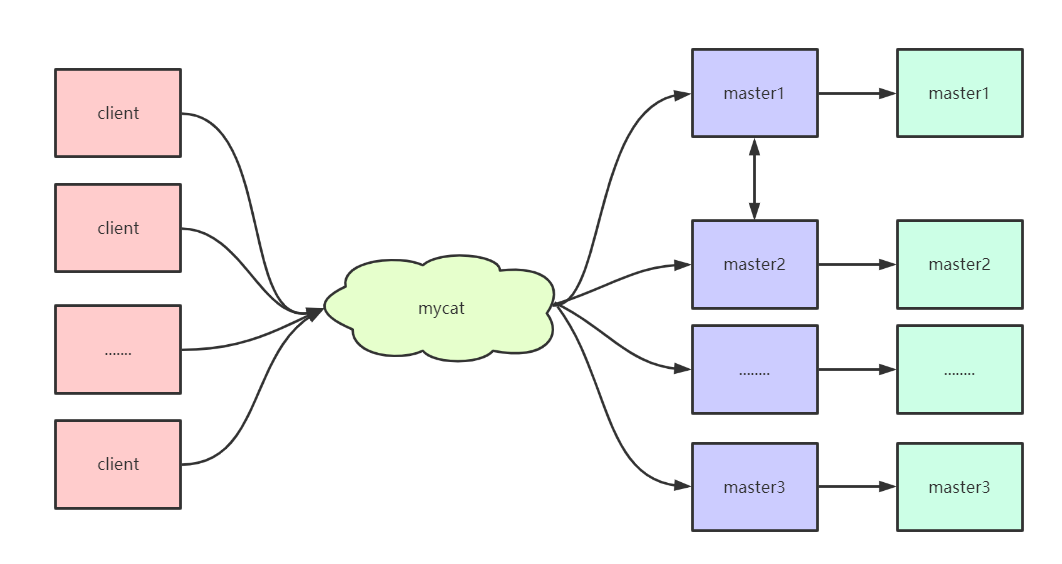
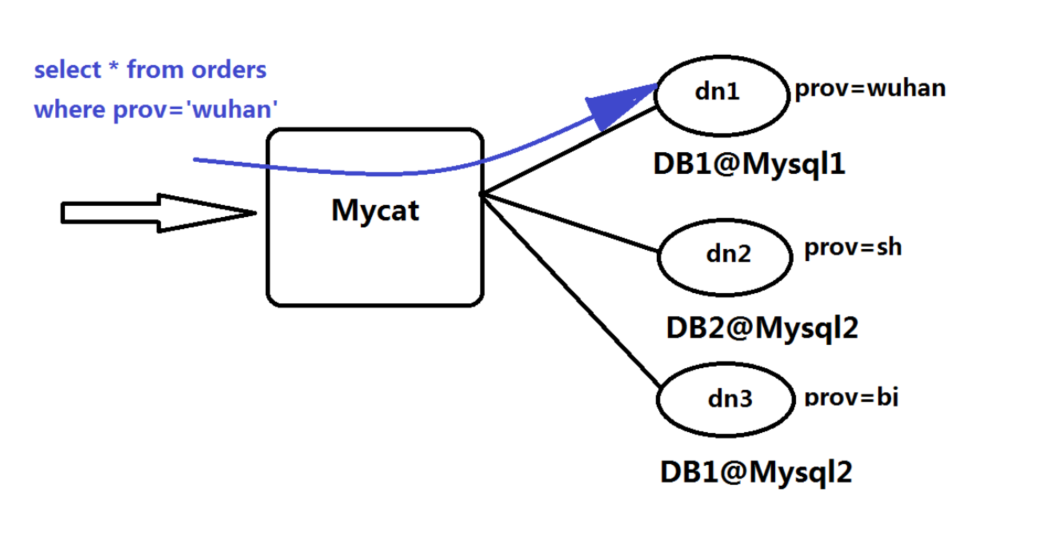
MyCat MyCat一、基础知识1、分布式系统 分布式系统是指其组件分布在网络上,组件之间通过传递消息进行通信和动作协调的系统。它的核心理念是让多台服务器协同工作,完成单台服务器无法处理的任务,尤其是高并发或者大数据量的额任务。它的特点是: 透明性:分布式系统对于用户是透明的,一个分布式系统在用户面前的表现就像一个传统的单处理机分时系统,可用用户不必了解其内部结构就能使用; 扩展性:分布式系统的最大特点是可扩展性,它能够根据需求的增加而扩展,可以通过横向扩展使集群的整体性能得到线性提升,也可以通过纵向扩展单台服务器的性能使服务器集群的性能得到提升; 可靠性:分布式系统不允许单点失效的问题存在,它的基本思想是,如果一台机器坏了,则其他机器能够接替它进行工作,具有持续服务的特性; 高性能:高性能才是设计分布式系统的初衷. 分布式系统的缺点: 1、在节点通信部分的开销比较大,线程安全问题也变得复杂,需要在保证数据完整性的同时兼顾性能 2、过分依赖网络,网络信息的丢失和饱和将会抵消分布式系统的大部分优势 3、有潜在的数据安全和网络安全等安全性问题。2、分布式数据库 随着技术的发展,各个行业所产生的数据量呈爆炸式增长,动辄就达到数百TB或者PB的级别,已经远远超过了传统单机数据库的处理能力,因此分布式数据库已经成为了最最迫切的需求。 分布式数据库是指数据在物理上分步而在逻辑上集中管理的数据库系统。物理上分步是指分布式数据库的数据分步在物理位置不同并由网络连接的节点或站点上;逻辑上集中是指各数据库节点之间在逻辑上是一个整体,并由统一的数据库管理系统管理,不同的节点分步可以跨不同的机房、城市甚至国家。 分布式数据库的特点: 透明性:用户不必关系数据的逻辑分区和物理位置分步的细节,也不必关系重复副本的一致性问题,同时不必关系在局部场地上数据库支持哪种数据模型,对于开发工程师而言,当数据库从一个场地移到另一个场地时必须改写应用程序,使用起来如果一个数据库。 数据冗余性:分布式数据库通过冗余实现系统的可靠性、可用性,并改善其性能。多个节点存储数据副本,当某一个节点的数据遭到破坏时,冗余的副本可保证数据的完整性;当工作的节点受损害时,可通过心跳等机制进行切换,系统整体不被破坏。还可以通过热点数据的就近分步原则减少网络通信的消耗,加快访问速度,改善性能。 易于扩展性:在分布式数据库中能够方便地通过水平扩展提高系统的整体性能,也能够通过垂直扩展来提高性能,扩展并不需要修改系统程序。 自治性:各节点上的数据由本地的DBMS管理,具有自治处理能力,完成本场地的应用或局部应用 分布式数据库还具有经济、性能优越、响应速度更快、灵活的体系结构、易于继承现有系统等特点。3、分布式数据库的实现原理 分布式数据库具有逻辑整体性、物理分布式,正是因为其物理分布性才使得分布式数据库的实现变得更加复杂,因为数据划分后存储在不同的节点上,而为了保证可靠性,需要存储多个副本,所以产生了数据复制的问题。为了保证良好的性能,分布式数据库必须易于扩展,具体来讲分布式数据库应有4个优势:数据分片及复制管理、具有事务的可靠性存取、良好的性能、易于扩展,所以分布式数据库在设计上需要实现数据库数据库的目录管理、数据分片、分布式查询处理、分布式并发控制、分布式锁管理、分布式存储、分布式网络架构、分布式安全管理等。 1、分布式数据库的目录管理 分布式数据库的目录存放着系统元数据及数据库的元数据的全部信息,这些数据的存在是为了正确、有效地访问数据。数据的增删改查操作都需要用到目录,用户授权、安全管理及并发控制等也都需要用到目录,目录结构的合理性直接影响数据库的性能。目录一般包括各级的描述、访问方法的描述、关于数据库的统计数据和一致性信息等,系统根据这些信息将用户查询转换为物理数据库上的查询,选择一条最佳的存取路径进行事务管理及安全性、完整性检查等。 分布式数据库的目录课分为全局目录、分布式目录、全局与本地混合目录。 2、数据分片 当数据库过于庞大,尤其是写入过于频繁且很难由一台主机支撑时,我们还是会面临扩展瓶颈。我们将存放在同一个数据库实例中的数据分散存放到多个数据库实例上,进行多台设备存取以提高性能,在切分数据的同时可以提高系统整体的可用性。 数据分片是指将数据全局地划分为相关的逻辑片段,有水平切分、垂直切分、混合切分三种类型。 水平切分:按照某个字段的某种规则分散到多个节点库中,每个节点中包含一部分数据。可以将数据的水平切分简单理解为按照数据行进行切分,就是将表中的某些行却分到一个节点,将另外某些行切分到其他节点,从分布式的整体来看它们是一个整体的表 垂直切分:一个数据库由很多表构成,每个表对应不同的业务,垂直切分是指按照业务将表进行分类并分不到不同的节点上,垂直拆分简单明了,拆分规则明确,应用程序模块清晰、明确、容易整合,但是某个表的数据量达到一定程度后扩展起来比较困难。 混合切分:水平切分和垂直切分的结合 3、分布式查询处理 分布式查询处理的任务就是把一个分布式数据库上的高层次查询映射为在本地数据库上的操作,查询的解析必须拆分为代数查询的关系运算序列,将要查询的数据定位到各节点,使得查询在各节点进行,最后通过网络通信的操作汇聚查询结果。 4、分布式并发控制 并发控制是分布式事务管理的基本任务之一,其目的是保证分布式数据库中的多个事务并发高效、正确的执行。并发控制用来保证事务的可串行性,也就是说事务的并发执行等价于它们按某种次序的串行执行,从而为用户提供并发的透明性。进行并发控制的方法主要有三种:加锁并发控制、时间戳控制、乐观并发控制。加锁并发控制应用广泛,但是容易发生死锁;时间戳控制消除了死锁,一旦发生冲突变回重启而不是等待,需要有全局的统一时钟;乐观并发控制对于冲突较少的系统较为合适,对于冲突多的系统则效率低下。4、OLTP和OLAP 在互联网时代,海量数据的存储和访问成为系统设计与使用的瓶颈,对于海量数据处理,按照使用场景,主要分为两种类型:联机事务处理(OLTP)和联级分析处理(OLAP)。 联机事务处理也称为面向事务的处理系统,其基本特征是原始数据可以立即传送到计算中心进行处理,在很短的时间内给出处理结果。 联级分析处理是指通过多维的方式对数据进行分析、查询和报表,可以同数据挖掘工具、统计分析工具配合使用,增强决策分析功能。 两者之间的区别: OLTPOLAP系统功能日常交易处理统计、分析、报表DB设计面向实时交易类应用面向统计分析类应用数据处理当前的,最新的细节的,历史的、聚集的、多维的、集成的实时性实时读写要求高实时要求读写低事务强一致性弱事务分析要求低,简单高,复杂5、关系型数据库和NoSQL 关系型数据库是建立在关系模型基础上的数据库,其借助于集合代数等数学概念和方法来处理数据库中的数据,主流的是Oracle,DB2,SQL Server,MySQL NoSQL数据库,全称为Not Only SQL,意思就是适用关系型数据库的时候就是用关系型数据库,不适用的时候也没必要非使用关系型数据库不可,可以考虑更加合适的数据存储,主要分为临时性键值存储(Memcached,Redis),永久性键值存储(Redis),面向文档的数据库(MongoDB,CouchDB),面向列的数据库(Cassandra,HBase),每种NoSQL都有其特有的使用场景及优点。 关系型数据库NoSQL数据库特点数据关系模型基于关系模型,结构化存储,完整性约束基于二维表及其之间的联系,需要连接、并、交、差等操作采用结构化的查询语言做数据读写操作需要数据的一致性,需要事务甚至强一致性非结构化的存储基于多维关系模型具有特色的使用场景优点保证数据的一致性可以进行join等复杂查询通用化,技术成熟高并发、大数据下读写能力强支持分布式,易于扩展,可伸缩简单,弱结构化存储缺点数据读写必须经过sql解析,大量数据、高并发读写性能不足对数据做读写,或修改数据结构时需要加锁,影响并发操作无法适应非结构化存储扩展困难昂贵、复杂join等复杂操作能力较弱事务支持较弱通用性差无完整约束复杂业务场景支持较差二、MyCat介绍1、MyCat是什么 MyCat 是什么?从定义和分类来看,它是一个开源的分布式数据库系统,是一个实现了 MySQL 协议的Server,前端用户可以把它看作是一个数据库代理,用 MySQL 客户端工具和命令行访问,而其后端可以用MySQL 原生(Native) 协议与多个 MySQL 服务器通信,也可以用 JDBC 协议与大多数主流数据库服务器通信,其核心功能是分表分库,即将一个大表水平分割为 N 个小表,存储在后端 MySQL 服务器里或者其他数据库里。 MyCat 发展到目前的版本,已经不是一个单纯的 MySQL 代理了,它的后端可以支持 MySQL、 SQL Server、Oracle、 DB2、 PostgreSQL 等主流数据库,也支持 MongoDB 这种新型 NoSQL 方式的存储,未来还会支持更多类型的存储。而在最终用户看来,无论是那种存储方式,在 MyCat 里,都是一个传统的数据库表,支持标准的SQL 语句进行数据的操作,这样一来,对前端业务系统来说,可以大幅降低开发难度,提升开发速度,在测试阶段,可以将一个表定义为任何一种 MyCat 支持的存储方式,比如 MySQL 的 MyASIM 表、内存表、或者MongoDB、 LevelDB 以及号称是世界上最快的内存数据库 MemSQL 上。试想一下,用户表存放在 MemSQL 上,大量读频率远超过写频率的数据如订单的快照数据存放于 InnoDB 中,一些日志数据存放于 MongoDB 中,而且还能把 Oracle 的表跟 MySQL 的表做关联查询,你是否有一种不能呼吸的感觉?而未来,还能通过 MyCat 自动将一些计算分析后的数据灌入到 Hadoop 中,并能用 MyCat+Storm/Spark Stream 引擎做大规模数据分析,看到这里,你大概明白了, MyCat 是什么? MyCat 就是 BigSQL, Big Data On SQL Database。 对于不同的角色,MyCat到底是个啥? 对于DBA而言,可以这么理解MyCat: MyCat就是MySQL Server,而Mycat后面连接的MySQL Server,就好像是MySQL的存储引擎,如InnoDB,MyISAM等,因此,MyCat本身并不存储数据,数据是再后端的MySQL上存储的,因此数据可靠性以及事务都是MySQL保证的,简单说,MyCat就s是MySQL最佳伴侣,它再一定程度上让MySQL拥有了能跟Oracle PK的能力。 对于软件工程师来说,可以这么理解MyCat: MyCat就是一个近似等于MySQL的数据库服务器,你可以用连接MySQL的方式去连接MyCat,除了端口不同,默认的MyCat端口是8066而不是MySQL的3306,因此需要再连接字符串上增加端口信息,大多数情况下,可以用你熟悉的对象映射框架使用MyCat,但建议对于分片表,尽量使用基础的SQL语句,因为这样能达到最佳性能,特别是几千万甚至几百亿条记录的情况下。 对于架构师来说,可以这么理解MyCat: MyCat是一个强大的数据库中间件,不仅仅可以用作读写分离、以及分库分表、容灾备份,而且可以用于多租户应用开发,云平台基础设施,让你的架构具备很强的适应性和灵活性,借助于即将发布的mycat只能优化模块,系统的数据访问瓶颈和热点一目了然,根据这些统计分析数据,你可以自动或手工调整后端存储,将不同的表映射到不同的存储引擎上,而整个应用的代码一行也不用改变。2、MyCat的原理 MyCat的原理并不复杂,复杂的是代码,如果代码也不复杂,那么早就成为了一个传说了。 MyCat的原理中最重要的一个动作是“拦截”,它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发送后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。 上述图片里,orders表被分为了三个分片DataNode(简称dn),这三个分片是分布在两台MySQL Server上(Datahost),即datanode=database@datahost方式,因此你可以用一台到N台服务器来分片,分片规则为(sharding rule)典型的字符串枚举分片规则,一个规则的定义是分片字段(sharding column)+分片函数(rule function),这里的分片字段为prov而分片函数为字符串枚举方式。 当MyCat收到一个SQL时,会先解析这个SQL,查找涉及到的表,然后看此表的定义,如果有分片规则,则获取到SQL里分片字段的值,并分配分片函数,得到该SQL对应的分片列表,然后将SQL发往这些分片去执行,最后收集和处理所有分片返回的结果数据,并输出到客户端,以select * from orders where prov = ?语句为例,查到prov=wuhan,按照分片函数,wuhan返回dn1,于是sql就发给了mysql1,去取db1上的查询结果,并返回给用户。 如果上述sql改为select * from orders where prov in (wuhan,beijing),那么,sql就会发给MySQL1和MySQL2去执行,然后结果集合并后输出给用户。但通常业务中我们的SQL会有order by以及limit翻页语法,此时就设计到结果集在MyCat端的二次处理,这部分代码也比较复杂,而最复杂的则属两个表的join,为此,MyCat提出了创新性的ER分片,全局表,HBT(human brain tech)人工智能的Catlet,以及结合Storm/Spark引擎等十八般武艺的解决办法,从而称为目前业界最强大的方案,这就是开源的力量。3、应用场景 MyCat发展到现在,使用的场景已经很丰富,而且不断有新用户给出新的创新性的方案,以下是典型的应用场景: 1、单纯的读写分离,此时配置最为简单,支持读写分离,主从切换 2、分库分表,对于超过1000万的表进行分片,最大支持1000亿的单表分片 3、多租户应用,每个应用一个库,但应用程序只连接MyCat,从而不改造程序本身,实现多租户化 4、报表系统,借助MyCat的分表能力,处理大规模报表的统计 5、整合多数据源 6、作为海量数据实时查询的一种简单有效方案,比如100亿条频繁查询的记录需要在3秒内查询出来结果,除了基于主键的查询,还可能存在范围查询或其他属性查询,此时MyCat可能是最简单有效的选择 7、数据库路由器,MyCat基于MySQL实例的连接池复用机制,可以让每一个应用最大程度地共享一个MySQL实例的所有连接池,让数据库的并发访问能力大大提升4、为什么使用MyCat 1、java与数据库紧耦合 2、高访问量高并发对数据库的压力 3、读写请求数据不一致5、数据库中间件对比对比项目mycatmangocobarheisenbergaltasamoeba数据切片支持支持支持支持支持支持读写分离支持支持支持支持支持支持宕机自动切换支持不支持支持不支持半支持,影响写不支持mysql协议前后端支持JDBC前端支持前后端支持前后端支持JDBC支持的数据库mysql,oracle,mongodb,postgresqlmysqlmysqlmysqlmysqlmysql,mongodb社区活跃度高活跃停滞低中等停滞文档资料极丰富较齐全较齐全较少中等缺少是否开源开源开源开源开源开源开源是否支持事务弱XA支持单库强一致,分布式弱事务单库强一致,多库弱事务单库强一致,分布弱事务不支持三、MyCat的核心概念 MyCat是数据库中间件,就是介于数据库与应用之间,进行数据处理和交互的中间服务。从原有的一个库,被切分为多个分片数据库,所有的分片数据库集群构成了整个完整的数据库存储。 如上图所示,数据被分到多个分片数据库之后,应用如果需要读取数据,就要处理多个数据源的数据。如果没有数据库中间件,那么应用将直接面对分片集群,数据源切换、事务处理、数据聚合都需要应用直接处理,原本该是专注于业务的应用,将会话大量的工作来处理分片后的问题,最重要的是每个应用处理将是完全的重复造轮子。1、逻辑库 对于实际应用而言,其实并不需要知道中间件的存在,开发人员只需要知道数据库的概念即可,所以数据库中间件可以被看作是一个或多个数据库集群构成的逻辑库。 在云计算时代,数据库中间件可以以多租户的形式给一个或多个应用提供服务,每个应用访问的可能是一个独立或者共享的物理库,常见的如阿里云数据库服务器RDS2、逻辑表 既然有逻辑库,那么就应该有逻辑表,在分布式数据库中,对应用来说,读写数据的表就是逻辑表。逻辑表可以使数据切分后,分步在一个或多个分片库中,也可以不做数据切分,不分片,只有一个表构成3、分片表 分片表,是指哪些原有的很大数据的表,需要切分到多个数据库的表,这样每一个分片都会有一部分数据,所有分片构成了完整的数据。4、非分片表 一个数据库中并不是所有的表都很大,某些表是可以不用进行切分的,非分片是相对分片表来说的,就是那些不需要进行数据切分的表。5、ER表 关系型数据库是基于实体关系模型之上,通过其描述了真实世界中事物与关系,MyCat中的ER表既是来源于此。根据这一思路,提出了基于ER关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上,即子类依赖于父类,通过表分组保证数据join不会跨库操作。 表分组是解决跨分片数据join的一种很好的思路,也是数据切分规划的重要一条规则。6、全局表 一个真实的业务系统中,往往存在大量的类似字典表的表,这些表基本上很少变动,字典表具有以下几个特点: 1、变动不频繁 2、数据量总体变化不大 3、数据规模不大,很少有超过数十万条记录 对于这类的表,在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联,就成了比较棘手的问题,所以MyCat中通过数据冗余来解决这类表的join,即所有的分片都有一份数据的拷贝,所有将字典表或者符合字典表特性的一些表定义为全局表。 数据冗余是解决跨分片数据join的一种很好思路,也是数据切分规划的另外一条重要原则7、分片节点(dataNode) 数据切分后,一个大表被分到不同的分片数据库上面,每个表分片所在的数据库就是分片节点(dataNode)8、节点主机(dataHost) 数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机器上面可以有多个分片数据库,这样一个或多个分片节点(dataNode)所在的机器就是节点主机(dataHost),为了规避单节点主机并发数限制,尽量将读写压力高的分片节点(dataNode)均衡的放在不同的节点主机(dataHost)。9、分片规则 数据切分是指一个大表被分成若干个分片表,就需要一定的规则,这样按照某种规则把数据分到某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,将极大的避免后续数据处理的难度。10、全局序列号 数据切分后,原有的关系数据库中的主键约束在分布式条件下将无法使用,因此需要引入外部机制保证数据唯一性标识,这种保证全局性的数据唯一标识的机制就是全局序列号。11、多租户 多租户技术或称多重租赁技术,是一种软件架构技术,它是在探讨与实现如何于多用户的环境下共用相同的系统或程序组件,并且扔可确保各用户间数据的隔离性。在云计算时代,多租户技术在共用的数据中心以单一系统架构与服务提供多数客户端相同甚至可定制化的服务,并且仍然可以保障客户的数据隔离。目前各种各样的云计算服务就是这类技术范畴,例如阿里云数据库服务(RDS),阿里云服务器等等。 多租户在数据存储上存在三种主要的方案,分别是:1、独立数据库 一个租户一个数据库,这种方案的用户数据隔离级别最高,安全性最好,但成本也高。 优点:为不同的租户提供独立的数据库,有助于简化数据模型的扩展设计,满足不同租户的独特需求,如果出现故障,恢复数据比较简单。 缺点:增大了数据库的安装数量,随之带来维护成本和购置成本的增加2、共享数据库,隔离数据架构 多个或者所有租户共享database,但是每一个租户一个schema 优点:为安全性要求较高的租户提供了一定程度的逻辑数据隔离,并不是完全隔离;每个数据库可以支持更多的租户数量 缺点:如果出现故障,数据恢复比较困难,因此恢复数据库将牵扯到其他租户的数据,如果需要跨租户统计数据,存在一定困难3、共享数据库,共享数据结构 租户共享同一个database,同一个schema,但在表中通过tenantID区分租户的数据。这是共享程度最高、隔离级别最低的模式 优点:维护和购置成本最低,运行每个数据库支持的租户数量最多 缺点:隔离级别最低,安全性最低,需要在设计开发时加大对安全的开发量,数据备份和恢复最困难,需要逐表逐条备份和还原。
-
-
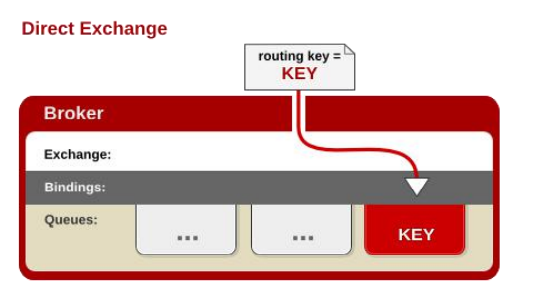
RabbitMQ运行机制 RabbitMQ运行机制AMQP 中的消息路由 AMQP 中消息的路由过程和 Java 开 发者熟悉的 JMS 存在一些差别, AMQP 中增加了 Exchange 和 Binding 的角色。生产者把消息发布 到 Exchange 上,消息最终到达队列 并被消费者接收,而 Binding 决定交 换器的消息应该发送到那个队列Exchange 类型Exchange分发消息时根据类型的不同分发策略有区别,目前共四种类型:direct、 fanout、topic、headers 。headers 匹配 AMQP 消息的 header 而不是路由键, headers 交换器和 direct 交换器完全一致,但性能差很多,目前几乎用不到了,所以直接 看另外三种类型:Direct Exchange消息中的路由键(routing key)如果和 Binding 中的 binding key 一致, 交换器 就将消息发到对应的队列中。路由键与队 列名完全匹配,如果一个队列绑定到交换 机要求路由键为“dog”,则只转发 routing key 标记为“dog”的消息,不会转发 “dog.puppy”,也不会转发“dog.guard” 等等。它是完全匹配、单播的模式Fanout Exchange每个发到 fanout 类型交换器的消息都 会分到所有绑定的队列上去。fanout 交 换器不处理路由键,只是简单的将队列 绑定到交换器上,每个发送到交换器的 消息都会被转发到与该交换器绑定的所 有队列上。很像子网广播,每台子网内 的主机都获得了一份复制的消息。 fanout 类型转发消息是最快的Topic Exchangetopic 交换器通过模式匹配分配消息的 路由键属性,将路由键和某个模式进行 匹配,此时队列需要绑定到一个模式上。 它将路由键和绑定键的字符串切分成单 词,这些单词之间用点隔开。它同样也 会识别两个通配符:符号“#”和符号 “”。#匹配0个或多个单词,匹配一 个单词RabbitMQ消息确认机制-可靠抵达保证消息不丢失,可靠抵达,可以使用事务消息,性能下降250倍,为此引入确认机制publisher confirmCallback 确认模式publisher returnCallback 未投递到 queue 退回模式consumer ack机制1、发送端-可靠抵达-ConfirmCallback• spring.rabbitmq.publisher-confirms=true• 在创建 connectionFactory 的时候设置 PublisherConfirms(true) 选项,开启confirmcallback 。• CorrelationData:用来表示当前消息唯一性。• 消息只要被 broker 接收到就会执行 confirmCallback,如果是cluster 模式,需要所有broker 接收到才会调用 confirmCallback。• 被 broker 接收到只能表示 message 已经到达服务器,并不能保证消息一定会被投递到目标 queue 里。所以需要用到接下来的 returnCallback 。2、发送端-可靠抵达-ReturnCallback• spring.rabbitmq.publisher-returns=true• spring.rabbitmq.template.mandatory=true• confrim 模式只能保证消息到达 broker,不能保证消息准确投递到目标queue里。在有些业务场景下,我们需要保证消息一定要投递到目标queue 里,此时就需要用到return 退回模式。• 这样如果未能投递到目标 queue 里将调用 returnCallback ,可以记录下详细到投递数据,定期的巡检或者自动纠错都需要这些数据。3、消费端-可靠抵达-Ack消息确认机制消费者获取到消息,成功处理,可以回复Ack给Broker•basic.ack用于肯定确认;broker将移除此消息 •basic.nack用于否定确认;可以指定broker是否丢弃此消息,可以批量 •basic.reject用于否定确认;同上,但不能批量•默认自动ack,消息被消费者收到,就会从broker的queue中移除•queue无消费者,消息依然会被存储,直到消费者消费•消费者收到消息,默认会自动ack。但是如果无法确定此消息是否被处理完成,或者成功处理。我们可以开启手动ack模式•消息处理成功,ack(),接受下一个消息,此消息broker就会移除•消息处理失败,nack()/reject(),重新发送给其他人进行处理,或者容错处理后ack•消息一直没有调用ack/nack方法,broker认为此消息正在被处理,不会投递给别人,此时客户端断开,消息不会被broker移除,会投递给别人详细使用可参考,springboot整合RabbitMQ 及初识RabbitMQ
-
SpringBoot整合RabbitMQ SpringBoot整合RabbitMQ1、引入依赖<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> <version>2.6.3</version> </dependency>2、配置rabbitmq通过RabbitProperties.properties配置文件配置链接 rabbitmq: host: 192.168.56.10 virtual-host: / port: 5672 publisher-confirm-type: correlated publisher-returns: true template: mandatory: true重点:#开启发送端确认机制,发送到Broke的确认 publisher-confirm-type: correlated #开启时消息发送到队列的消息确认机制 publisher-returns: true #只要抵达队列,以异步发送优先回调我们这个Returnconfirm template: mandatory: true3、开启Rabbit启动类添加@EnableRabbit注解@EnableRabbit @SpringBootApplication public class FamilyBookingApplication { public static void main(String[] args) { SpringApplication.run(FamilyBookingApplication.class, args); } }4、Rabbit使用现在RabbitAutoConfiguration就生效了,就有了组件RabbitTemplate、AmqpAdmin、CachingConnectionFactory、RabbitMessagingTemplate5、使用测试1、创建Exchange、Queue、Binding使用AmqpAdmin创建。通过创建各交换机构造方法,找到对应接口的实现,传入参数即可创建Exchange。public DirectExchange(String name, boolean durable, boolean autoDelete, Map<String, Object> arguments) @Autowired AmqpAdmin amqpAdmin; /** * 创建Exchange交换机 */ @Test public void craeteChage() { /** * public DirectExchange(String name, boolean durable, boolean autoDelete, Map<String, Object> arguments) */ DirectExchange directExchange = new DirectExchange("Family-Hello-Exchange",true,false); amqpAdmin.declareExchange(directExchange); } /** * 创建Queue交换机 */ @Test public void craetQueue() { /** * public Queue(String name, boolean durable, boolean exclusive, boolean autoDelete, @Nullable Map<String, Object> arguments) */ Queue queue = new Queue("Family-Hello-Queue", true,false, false); amqpAdmin.declareQueue(queue); } /** * 创建Bind交换机 */ @Test public void craetBind() { /** * public Binding(String destination, 绑定目标 * Binding.DestinationType destinationType, 绑定类型 * String exchange, 交换机 * String routingKey, router-key * @Nullable Map<String, Object> arguments 参数) { */ Binding binding = new Binding("Family-Hello-Queue", Binding.DestinationType.QUEUE, "Family-Hello-Exchange", "Java.hello", null); amqpAdmin.declareBinding(binding); }上面为DirectExchange类型交换机的创建,其它类型Exchange类似。更多API可参考AmqpAdmin的各方法。2、收发消息发送消息 /** * rabbitTemplate 发送消息 */ @Test public String sendMessage(){ //发送字符串 rabbitTemplate.convertAndSend("Family-Hello-Exchange","Java.hello","Hello RabbitMQ 。。。",new CorrelationData(UUID.randomUUID().toString())); //发送对象 MemberEntity memberEntity = new MemberEntity(); memberEntity.setAddress("rabbitMQ测试-会员地址信息"); memberEntity.setEmail("rabbitMQ测试-会员邮箱,batis@foxmial.com"); //发送对象,注意:发送的对象必须序列化。默认发送的对象是序列化的,如果想以json格式方式发送,需要进行配置。 rabbitTemplate.convertAndSend("Family-Hello-Exchange","Java.hello",memberEntity,new CorrelationData(UUID.randomUUID().toString())); return "向RabbitMQ发送消息成功"; }3、接受消息RabbitMQ为我们提供了监听@RabbitListener监听注解,使用时,必须开启@EnableRabbit功能。不用监听消息队列时,可以不用开启@EnableRabbit注解。 /** * 监听队列是各数组,可以同时监听多个队列 * 通过返回的消息类型知道是一个org.springframework.amqp.core.Message; * @param message */ @RabbitListener(queues={"Family-Hello-Queue"}) public String sendMessage(){ //发送字符串 // rabbitTemplate.convertAndSend("Family-Hello-Exchange","Java.hello","Hello RabbitMQ 。。。",new CorrelationData(UUID.randomUUID().toString())); //发送对象 MemberEntity memberEntity = new MemberEntity(); memberEntity.setAddress("rabbitMQ测试-会员地址信息"); memberEntity.setEmail("rabbitMQ测试-会员邮箱,batis@foxmial.com"); //发送对象,注意:发送的对象必须序列化。默认发送的对象是序列化的,如果想以json格式方式发送,需要进行配置。 rabbitTemplate.convertAndSend("Family-Hello-Exchange","Java.hello",memberEntity,new CorrelationData(UUID.randomUUID().toString())); return "向RabbitMQ发送消息成功"; } /** * * 通过传入第二个参数spring可以帮我们把之间转的对象获取后转成对象,第二个参数不固定的泛型<T> * 比如上面发送的是一个user对象,那我们第二个参数就是User user,接受到的数据就直接是user了。 * 还可以直接获取到链接中传输数据的通道channel * @param message */ @RabbitListener(queues={"Family-Hello-Queue"}) public void receiveMessageAndObject(Message message, MemberEntity memberEntity, Channel channel){ //消息体,数据内容 //通过原生Message message获取的消息还得进行转化才好使用,需要转成对象。 byte[] body = message.getBody(); //消息头信息 MessageProperties messageProperties = message.getMessageProperties(); System.out.println("监听到队列消息2:"+message+"消息类型:"+message.getClass()); System.out.println("监听到队列消息2:"+message+"消息内容:"+memberEntity); }Queue:可以很多人都来监听。只要收到消息,队列删除消息,而且只能有一个收到此消息注意:1)、同一个消息,只能有一个客户端收到2)、只有一个消息完全处理完,方法运行结束,我们才可以接收到下一个消息3)、@RabbitHandler也可以接受队列消息@RabbitListener可以用在类和方法上@RabbitHandler只能用在方法上。@RabbitHandler应用场景:当发送的数据为不同类型时,@RabbitListener接口消息时,参数类型不知道定义那个。比如:想队列发送的对象有user、People people,那下面接受时,对象不知道写那个public void receiveMessageObject(Message message, 这里该写那个对象, Channel channel)因此@RabbitHandler就可以用上了。通过在类上加上@RabbitHandler注解监听队列消息,在方法上加@RabbitHandler注解,参数就可以指定接受那个数据类型的消息了。简单代码如下:@RabbitListener(queues={"Family-Hello-Queue"}) @Service("memberService") public class MemberServiceImpl extends ServiceImpl<MemberDao, MemberEntity> implements MemberService { //接受队列中指定的People类型数据 @RabbitHandler public void receiveMessageObj(Message message, MemberEntity memberEntity, Channel channel){ //消息体,数据内容 //通过原生Message message获取的消息还得进行转化才好使用,需要转成对象。 byte[] body = message.getBody(); //消息头信息 MessageProperties messageProperties = message.getMessageProperties(); System.out.println("监听到队列消息:"+message+"消息内容:"+memberEntity); } //接受队列中指定的User类型数据 @RabbitHandler public void receiveMessageObj(Message message, MemberEntity memberEntity, Channel channel){ //消息体,数据内容 //通过原生Message message获取的消息还得进行转化才好使用,需要转成对象。 byte[] body = message.getBody(); //消息头信息 MessageProperties messageProperties = message.getMessageProperties(); System.out.println("监听到队列消息:"+message+"消息内容:"+memberEntity); } }6、RabbitMQ Java配置Json序列化通过RabbitAutoConfiguration.java中注入的RabbitTemplate看到configure。@Bean @ConditionalOnMissingBean public RabbitTemplateConfigurer rabbitTemplateConfigurer(RabbitProperties properties, ObjectProvider<MessageConverter> messageConverter, ObjectProvider<RabbitRetryTemplateCustomizer> retryTemplateCustomizers) { RabbitTemplateConfigurer configurer = new RabbitTemplateConfigurer(); configurer.setMessageConverter((MessageConverter)messageConverter.getIfUnique()); configurer.setRetryTemplateCustomizers((List)retryTemplateCustomizers.orderedStream().collect(Collectors.toList())); configurer.setRabbitProperties(properties); return configurer; } @Bean @ConditionalOnSingleCandidate(ConnectionFactory.class) @ConditionalOnMissingBean({RabbitOperations.class}) public RabbitTemplate rabbitTemplate(RabbitTemplateConfigurer configurer, ConnectionFactory connectionFactory) { RabbitTemplate template = new RabbitTemplate(); configurer.configure(template, connectionFactory); return template; }如果配置中有MessageConverter消息转换器就用configurer.setMessageConverter((MessageConverter)messageConverter.getIfUnique());如果没有就用RabbitTemplate默认配置的。RabbitTemplateConfigurer.java默认配置源码中可以看到默认使用的转换器如下:public MessageConverter getMessageConverter() { return this.messageConverter; } private MessageConverter messageConverter = new SimpleMessageConverter(); 然后通过SimpleMessageConverter可以看到默认创建消息时,使用的消息转换器类型 protected Message createMessage(Object object, MessageProperties messageProperties) throws MessageConversionException { byte[] bytes = null; if (object instanceof byte[]) { bytes = (byte[])((byte[])object); messageProperties.setContentType("application/octet-stream"); } else if (object instanceof String) { try { bytes = ((String)object).getBytes(this.defaultCharset); } catch (UnsupportedEncodingException var6) { throw new MessageConversionException("failed to convert to Message content", var6); } messageProperties.setContentType("text/plain"); messageProperties.setContentEncoding(this.defaultCharset); } else if (object instanceof Serializable) { try { bytes = SerializationUtils.serialize(object); } catch (IllegalArgumentException var5) { throw new MessageConversionException("failed to convert to serialized Message content", var5); } messageProperties.setContentType("application/x-java-serialized-object"); } if (bytes != null) { messageProperties.setContentLength((long)bytes.length); return new Message(bytes, messageProperties); } else { throw new IllegalArgumentException(this.getClass().getSimpleName() + " only supports String, byte[] and Serializable payloads, received: " + object.getClass().getName()); } }如果是序列化的就是使用的SerializationUtils.serialize(object);else if (object instanceof Serializable) { try { bytes = SerializationUtils.serialize(object); } catch (IllegalArgumentException var5) { throw new MessageConversionException("failed to convert to serialized Message content", var5); } messageProperties.setContentType("application/x-java-serialized-object");因此我们可以自定义MessageConverter。通过MessageConverter接口实现类型,可以看到json各实现类。因此RabbitMQ自定义配置如下:import org.springframework.amqp.support.converter.Jackson2JsonMessageConverter; import org.springframework.amqp.support.converter.MessageConverter; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; /** * @description: RabbitMQ配置 * @author: <a href="mailto:batis@foxmail.com">清风</a> * @date: 2022/3/12 17:07 * @version: 1.0 */ @Configuration public class MyRabbitConfig { @Bean public MessageConverter messageConverter(){ return new Jackson2JsonMessageConverter(); } }再次发送对象时,从mq里面获取的对象就是json格式了。7、开启消息回调确认机制#开启发送端确认机制,发送到Broke的确认 publisher-confirm-type: correlated #开启时消息发送到队列的消息确认机制 publisher-returns: true #只要抵达队列,以异步发送优先回调我们这个ReturnCallback template: mandatory: true #手动确认ack listener: simple: acknowledge-mode: manual8、重点:发送端:package com.yanxizhu.family.users.config; import org.springframework.amqp.core.Message; import org.springframework.amqp.rabbit.connection.ConnectionFactory; import org.springframework.amqp.rabbit.connection.CorrelationData; import org.springframework.amqp.rabbit.core.RabbitTemplate; import org.springframework.amqp.support.converter.Jackson2JsonMessageConverter; import org.springframework.amqp.support.converter.MessageConverter; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.context.annotation.Primary; /** * @description: RabbitMQ配置 序列化 * @author: <a href="mailto:batis@foxmail.com">清风</a> * @date: 2022/4/17 16:44 * @version: 1.0 */ @Configuration public class RabbitConfig { private RabbitTemplate rabbitTemplate; /** * rabbitTemplate循环依赖,解决方法:手动初始化模板方法 * @param connectionFactory * @return */ @Primary @Bean public RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory) { RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory); this.rabbitTemplate = rabbitTemplate; rabbitTemplate.setMessageConverter(messageConverter()); initRabbitTemplate(); return rabbitTemplate; } @Bean public MessageConverter messageConverter(){ return new Jackson2JsonMessageConverter(); } /** * 定制rabbitMaTemplate * 一、发送端消息确认机制,发送给Broke的消息确认回调 * 1、开始消息确认 publisher-confirm-type: correlated * 2、设置确认回调 setConfirmCallback() * 二、发送端消息确认机制,发送给队列的消息确认回调 * 1、开始消息确认 * publisher-returns: true * template: * mandatory: true * 2、设置确认回调 setReturnsCallback * 三、消费端确认(保证每个消息被正确消费,此时才可以broker删除这个消息) * 1、开启消费端消息确认 * listener: * simple: * acknowledge-mode: manual * 2、消费端默认是自动消息确认的,只要消息手法哦,客户端会自动确认,服务器就会移除这个消息。 * 默认的消息确认(默认ACK)问题: * 我们收到很多消息,自动回复给服务器ack,只有一个消息处理成功,服务器宕机了。会发生消息丢失; * 3、因此,需要使用消费者手动确认默认(手动ack),只要我们没有明确高数MQ,消息被消费,就没有ack,消息就一致是unacked状态。 * 即使服务器宕机,消息也不会丢失,会重新变为ready,下一次有新的消费者链接进来就发给它处理。 * 4、手动ack如何签收 * //消息头信息 * MessageProperties messageProperties = message.getMessageProperties(); * long deliveryTag = messageProperties.getDeliveryTag(); * channel.basicAck(deliveryTag,true); //手动确认签收,deliveryTag默认自增的,true是否批量确认签收 * 5、消费退回 * * //参数:long var1, boolean var3(是否批量), boolean var4 * channel.basicNack(deliveryTag,true,true); //可以批量回退 * * //参数:long var1, boolean var3 * channel.basicReject(deliveryTag,true); //单个回退 * * 第三个参数或第二个参数:false 丢弃 true:发回服务器,服务器重新入对。 */ public void initRabbitTemplate(){ //设置确认回调 rabbitTemplate.setConfirmCallback(new RabbitTemplate.ConfirmCallback() { /** * 只要消息抵达服务器 * @param correlationData 当前消息关联的唯一数据(这个消息的唯一id) * @param ack 消息是否成功收到 * @param cause 失败原因 */ @Override public void confirm(CorrelationData correlationData, boolean ack, String cause) { //correlationData:注意,这个correlationData就是发送消息时,设置的correlationData。 System.out.println("====确认收到消息了。。。。================"); System.out.println(correlationData+"|"+ack+"|"+cause); } }); //注意:必须要有这一步,不然不生效 rabbitTemplate.setMandatory(true); //设置消息抵达队列回调 rabbitTemplate.setReturnCallback(new RabbitTemplate.ReturnCallback() { /** * 只要消息没有投递给指定的队列,就触发这个失败回调 * @param message 投递失败的消息详细信息 * @param replyCode 回复的状态码 * @param replyText 回复的文本内容 * @param exchange 当时这个消息发给哪个交换机 * @param routingKey 当时这个消息用的哪个路由键 */ public void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) { System.out.println("==========投递到队列失败了。。。=========="); System.out.println(message); System.out.println(replyCode); System.out.println(replyText); System.out.println(exchange); System.out.println(routingKey); } }); } } 发送消息时,可以将new CorrelationData(UUID.randomUUID().toString()),传的uuid参数保存到数据库,到时候直接遍历数据库即可知道那些投递成功到队列,那些投递失败。说明: * 一、发送端消息确认机制,发送给Broke的消息确认回调 * 1、开始消息确认 publisher-confirm-type: correlated * 2、设置确认回调 setConfirmCallback() * 二、发送端消息确认机制,发送给队列的消息确认回调 * 1、开始消息确认 * publisher-returns: true * template: * mandatory: true * 2、设置确认回调 setReturnsCallback * 三、消费端确认(保证每个消息被正确消费,此时才可以broker删除这个消息) * 1、开启消费端消息确认 * listener: * simple: * acknowledge-mode: manual * 2、消费端默认是自动消息确认的,只要消息手法哦,客户端会自动确认,服务器就会移除这个消息。 * 默认的消息确认(默认ACK)问题: * 我们收到很多消息,自动回复给服务器ack,只有一个消息处理成功,服务器宕机了。会发生消息丢失; * 3、因此,需要使用消费者手动确认默认(手动ack),只要我们没有明确高数MQ,消息被消费,就没有ack,消息就一致是unacked状态。 * 即使服务器宕机,消息也不会丢失,会重新变为ready,下一次有新的消费者链接进来就发给它处理。消费端手动ack /** * * 通过传入第二个参数spring可以帮我们把之间转的对象获取后转成对象,第二个参数不固定的泛型<T> * 比如上面发送的是一个user对象,那我们第二个参数就是User user,接受到的数据就直接是user了。 * 还可以直接获取到链接中传输数据的通道channel * @param message */ @RabbitHandler public void receiveMessageObject(Message message, MemberEntity memberEntity, Channel channel) throws IOException { //消息体,数据内容 //通过原生Message message获取的消息还得进行转化才好使用,需要转成对象。 byte[] body = message.getBody(); //消息头信息 MessageProperties messageProperties = message.getMessageProperties(); long deliveryTag = messageProperties.getDeliveryTag(); //手动确认签收 channel.basicAck(deliveryTag,true); System.out.println("监听到队列消息3:"+message+"消息类型:"+message.getClass()); System.out.println("监听到队列消息3:"+message+"消息内容:"+memberEntity); //回退 //可以批量回退 // channel.basicNack(deliveryTag,true,true); //单个回退 //true重新排队,false丢弃 // channel.basicReject(deliveryTag,true); }说明:手动ack如何签收 //消息头信息 MessageProperties messageProperties = message.getMessageProperties(); long deliveryTag = messageProperties.getDeliveryTag(); channel.basicAck(deliveryTag,true); //手动确认签收,deliveryTag默认自增的,true是否批量确认签收消费退回 //参数:long var1, boolean var3(是否批量), boolean var4 channel.basicNack(deliveryTag,true,true); //可以批量回退 //参数:long var1, boolean var3 channel.basicReject(deliveryTag,true); //单个回退 第三个参数或第二个参数:false 丢弃 true:发回服务器,服务器重新入对。最后rabbitMQ配置:spring: rabbitmq: host: 192.168.56.10 virtual-host: / port: 5672 #开启发送端确认 publisher-confirm-type: correlated #开启发送端消息抵达队列的确认 publisher-returns: true #只要抵达队列,以异步发送优先回调我们这个retureconfirm template: mandatory: true #开启手动确认 listener: simple: acknowledge-mode: manualSpringBoot中使用延时队列1、Queue、Exchange、Binding可以@Bean进去 2、监听消息的方法可以有三种参数(不分数量,顺序) Object content, Message message, Channel channel 3、channel可以用来拒绝消息,否则自动ack;代码实现发送消息到MQ: public String sendDelayMessage(){ //发送对象 MemberEntity memberEntity = new MemberEntity(); memberEntity.setId(11111111L); memberEntity.setAddress("死信队列测试"); memberEntity.setEmail("延迟队列,异步处理会员信息"); memberEntity.setCreateTime(new Date()); //发送对象,注意:发送的对象必须序列化。默认发送的对象是序列化的,如果想以json格式方式发送,需要进行配置。 rabbitTemplate.convertAndSend("member-event-exchange","users.create.member",memberEntity, new CorrelationData(UUID.randomUUID().toString())); return "向RabbitMQ发送消息成功"; }通过延迟队列,将延迟的会员信息,发送到另一个队列,通过监听过期延迟的队列,接收延迟的会员信息。package com.yanxizhu.family.users.config; import com.rabbitmq.client.Channel; import com.yanxizhu.family.users.entity.MemberEntity; import org.springframework.amqp.core.*; import org.springframework.amqp.rabbit.annotation.RabbitListener; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import java.io.IOException; import java.util.HashMap; import java.util.Map; /** * @description: 延迟队列 * 说明: 1、首先通过创建的路由键(users.create.member),将消息从交换机(member-event-exchange)发送到死信队列(member.delay.queue)。 * 2、根据死信队列(member.delay.queue)的配置,过期后,消息将通过路由键为(users.release.member)转发到交换机(member-event-exchange)。 * 3、最后交换机(member-event-exchange)再通过绑定的最终队列(users.release.member.queue)和路由键(users.release.member)转发到最终队列(member-event-exchange)。 * @author: <a href="mailto:batis@foxmail.com">清风</a> * @date: 2022/4/17 20:47 * @version: 1.0 */ @Configuration public class DelayQueueConfig { /** * 监听最终的队列 * @param entity * @param channel * @param message * @throws IOException */ @RabbitListener(queues="member.release.queue") public void listener(MemberEntity entity, Channel channel, Message message) throws IOException { System.out.println("收到过期的会员信息:准备关闭会员"+entity.toString()); channel.basicAck(message.getMessageProperties().getDeliveryTag(),false); } //@bean自动创建交换机、路由、绑定 //交换机 @Bean public Exchange orderEventExchange(){ return new TopicExchange("member-event-exchange", true, false); } /** * 容器中的Binding、Queue、Exchange都会自动创建(RabbitMQ没有的情况) * @return */ //死信队列 @Bean public Queue memberDelayQueue(){ Map<String, Object> arguments = new HashMap<>(); arguments.put("x-dead-letter-exchange", "member-event-exchange");//交换机 arguments.put("x-dead-letter-routing-key", "users.release.member");//路由键 arguments.put("x-message-ttl", 60000);//过期时间 //public Queue(String name, boolean durable, boolean exclusive, boolean autoDelete, @Nullable Map<String, Object> arguments) Queue queue = new Queue("member.delay.queue",true,false,false,arguments); return queue; } //将死信队列和交换机绑定,路由键-users.create.member @Bean public Binding orderCreateOrderBingding(){ //目的地、绑定类型、交换机、路由键、参数 //public Binding(String destination, Binding.DestinationType destinationType, String exchange, String routingKey, @Nullable Map<String, Object> arguments) return new Binding("member.delay.queue", Binding.DestinationType.QUEUE, "member-event-exchange", "users.create.member", null); } //最后过期的队列 @Bean public Queue orderReleaseQueue(){ Queue queue = new Queue("member.release.queue",true,false,false); return queue; } //将最后的队列和交换机绑定,路由键-user.release.member @Bean public Binding orderReleaseOrderBingding(){ return new Binding("member.release.queue", Binding.DestinationType.QUEUE, "member-event-exchange", "users.release.member", null); } }
-
Docker安装RabbitMQ Docker安装RabbitMQ运行RabbitMQ容器第一次运行没有RabbitMQ镜像,会自动下载。docker run -d --name rabbitmq -p 5671:5671 -p 5672:5672 -p 4369:4369 -p 25672:25672 -p 15671:15671 -p 15672:15672 rabbitmq:management说明:4369, 25672 (Erlang发现&集群端口)5672, 5671 (AMQP端口)15672 (web管理后台端口)61613, 61614 (STOMP协议端口)1883, 8883 (MQTT协议端口)https://www.rabbitmq.com/networking.html设置随docker启动docker update --restart=always rabbitmq访问RabbitMQ通过ip地址加15672端口即可访问,初始账号密码guest