搜索到
6
篇与
的结果
-
 JAVA8-Stream parallel 并行执行 Stream parallel 并行执行范例:求1~100000000的和,执行10次,看时间效率。代码package com.example.study.java8.collector; import java.util.function.Function; import java.util.stream.LongStream; import java.util.stream.Stream; /** * Stream parallel并行执行 * 实列:求10次,1~100000000的和,看时间效率。 */ public class ParallelProcessing { public static void main(String[] args) { //获取电脑CPU核数 System.out.println("当前电脑CPU核数= " + Runtime.getRuntime().availableProcessors()); System.out.println("The best process time(normalAdd)=> " + measureSumPerformance(ParallelProcessing::normalAdd, 100_000_000) + " MS"); System.out.println("The best process time(iterateStream1)=> " + measureSumPerformance(ParallelProcessing::iterateStream1, 100_000_000) + " MS"); System.out.println("The best process time(iterateStream2)=> " + measureSumPerformance(ParallelProcessing::iterateStream2, 100_000_000) + " MS"); System.out.println("The best process time(iterateStream3)=> " + measureSumPerformance(ParallelProcessing::iterateStream3, 100_000_000) + " MS"); System.out.println("The best process time(iterateStream4)=> " + measureSumPerformance(ParallelProcessing::iterateStream4, 100_000_000) + " MS"); System.out.println("The best process time(iterateStream5)=> " + measureSumPerformance(ParallelProcessing::iterateStream5, 100_000_000) + " MS"); } private static long measureSumPerformance(Function<Long, Long> adder, long limist) { long fastest = Long.MAX_VALUE; for (int i = 0; i < 10; i++) { Long startTimestamp = System.currentTimeMillis(); long result = adder.apply(limist); long duration = System.currentTimeMillis() - startTimestamp; // System.out.println("The result of sum=>"+result); if (duration < fastest) fastest = duration; } return fastest; } /** * 1、函数式编程实现:没有使用并行执行 * * @param limit * @return */ public static long iterateStream1(long limit) { return Stream.iterate(1L, i -> i + 1).limit(limit).reduce(0L, Long::sum); } /** * 2、函数式编程实现-进化:使用并行执行,要进行拆箱装箱 * * @param limit * @return */ public static long iterateStream2(long limit) { return Stream.iterate(1L, i -> i + 1).parallel().limit(limit).reduce(0L, Long::sum); } /** * 3、函数式编程实现-再次进化:只用并行执行,不进行拆箱装箱 * * @param limit * @return */ public static long iterateStream3(long limit) { return Stream.iterate(1L, i -> i + 1).mapToLong(Long::longValue).parallel().limit(limit).reduce(0L, Long::sum); } /** * 4、函数式编程实现-再次再次进化:只用并行执行 * * @param limit * @return */ public static long iterateStream4(long limit) { return LongStream.rangeClosed(1L, limit).parallel().sum(); } /** * 5、函数式编程实现-再次再次再次进化 * * @param limit * @return */ public static long iterateStream5(long limit) { return LongStream.rangeClosed(1L, limit).parallel().reduce(0L, Long::sum); } /** * 原始写法 * * @param limit * @return */ public static long normalAdd(long limit) { long result = 0L; for (long i = 1; i < limit; i++) { result++; } return result; } } 输出结果当前电脑CPU核数= 16 The best process time(normalAdd)=> 29 MS The best process time(iterateStream1)=> 794 MS The best process time(iterateStream2)=> 2718 MS The best process time(iterateStream3)=> 2132 MS The best process time(iterateStream4)=> 6 MS The best process time(iterateStream5)=> 24 MS4和5效率差不多输出结果:当前电脑CPU核数= 16 The best process time(normalAdd)=> 29 MS The best process time(iterateStream4)=> 4 MS The best process time(iterateStream5)=> 5 MS结果可以看到使用LongStream的parallel并发执行效率最高。使用注意点Source DecomposabilityArrayList Excellent( 极好的)LinkedList Poor(不好的)IntStream.range Excellent( 极好的)Stream.iterate Poor(不好的)HashSet Good(好的)TreeSet Good(好的)上面的例子就是使用的LongStream.rangeClosed(),就是IntStream.range效率Excellent( 极好的)。
JAVA8-Stream parallel 并行执行 Stream parallel 并行执行范例:求1~100000000的和,执行10次,看时间效率。代码package com.example.study.java8.collector; import java.util.function.Function; import java.util.stream.LongStream; import java.util.stream.Stream; /** * Stream parallel并行执行 * 实列:求10次,1~100000000的和,看时间效率。 */ public class ParallelProcessing { public static void main(String[] args) { //获取电脑CPU核数 System.out.println("当前电脑CPU核数= " + Runtime.getRuntime().availableProcessors()); System.out.println("The best process time(normalAdd)=> " + measureSumPerformance(ParallelProcessing::normalAdd, 100_000_000) + " MS"); System.out.println("The best process time(iterateStream1)=> " + measureSumPerformance(ParallelProcessing::iterateStream1, 100_000_000) + " MS"); System.out.println("The best process time(iterateStream2)=> " + measureSumPerformance(ParallelProcessing::iterateStream2, 100_000_000) + " MS"); System.out.println("The best process time(iterateStream3)=> " + measureSumPerformance(ParallelProcessing::iterateStream3, 100_000_000) + " MS"); System.out.println("The best process time(iterateStream4)=> " + measureSumPerformance(ParallelProcessing::iterateStream4, 100_000_000) + " MS"); System.out.println("The best process time(iterateStream5)=> " + measureSumPerformance(ParallelProcessing::iterateStream5, 100_000_000) + " MS"); } private static long measureSumPerformance(Function<Long, Long> adder, long limist) { long fastest = Long.MAX_VALUE; for (int i = 0; i < 10; i++) { Long startTimestamp = System.currentTimeMillis(); long result = adder.apply(limist); long duration = System.currentTimeMillis() - startTimestamp; // System.out.println("The result of sum=>"+result); if (duration < fastest) fastest = duration; } return fastest; } /** * 1、函数式编程实现:没有使用并行执行 * * @param limit * @return */ public static long iterateStream1(long limit) { return Stream.iterate(1L, i -> i + 1).limit(limit).reduce(0L, Long::sum); } /** * 2、函数式编程实现-进化:使用并行执行,要进行拆箱装箱 * * @param limit * @return */ public static long iterateStream2(long limit) { return Stream.iterate(1L, i -> i + 1).parallel().limit(limit).reduce(0L, Long::sum); } /** * 3、函数式编程实现-再次进化:只用并行执行,不进行拆箱装箱 * * @param limit * @return */ public static long iterateStream3(long limit) { return Stream.iterate(1L, i -> i + 1).mapToLong(Long::longValue).parallel().limit(limit).reduce(0L, Long::sum); } /** * 4、函数式编程实现-再次再次进化:只用并行执行 * * @param limit * @return */ public static long iterateStream4(long limit) { return LongStream.rangeClosed(1L, limit).parallel().sum(); } /** * 5、函数式编程实现-再次再次再次进化 * * @param limit * @return */ public static long iterateStream5(long limit) { return LongStream.rangeClosed(1L, limit).parallel().reduce(0L, Long::sum); } /** * 原始写法 * * @param limit * @return */ public static long normalAdd(long limit) { long result = 0L; for (long i = 1; i < limit; i++) { result++; } return result; } } 输出结果当前电脑CPU核数= 16 The best process time(normalAdd)=> 29 MS The best process time(iterateStream1)=> 794 MS The best process time(iterateStream2)=> 2718 MS The best process time(iterateStream3)=> 2132 MS The best process time(iterateStream4)=> 6 MS The best process time(iterateStream5)=> 24 MS4和5效率差不多输出结果:当前电脑CPU核数= 16 The best process time(normalAdd)=> 29 MS The best process time(iterateStream4)=> 4 MS The best process time(iterateStream5)=> 5 MS结果可以看到使用LongStream的parallel并发执行效率最高。使用注意点Source DecomposabilityArrayList Excellent( 极好的)LinkedList Poor(不好的)IntStream.range Excellent( 极好的)Stream.iterate Poor(不好的)HashSet Good(好的)TreeSet Good(好的)上面的例子就是使用的LongStream.rangeClosed(),就是IntStream.range效率Excellent( 极好的)。 -
JAVA8-Stram练手 JAVA8-Stram练手交易员对象:package com.example.study.java8.streams.demo; /** * 交易员 */ public class Trader { private final String name; private final String city; public Trader(String n, String c){ this.name = n; this.city = c; } public String getName(){ return this.name; } public String getCity(){ return this.city; } public String toString(){ return "Trader:"+this.name + " in " + this.city; } } 交易对象package com.example.study.java8.streams.demo; /** * 交易 */ public class Transaction { private final Trader trader; private final int year; private final int value; public Transaction(Trader trader, int year, int value){ this.trader = trader; this.year = year; this.value = value; } public Trader getTrader(){ return this.trader; } public int getYear(){ return this.year; } public int getValue(){ return this.value; } public String toString(){ return "{" + this.trader + ", " + "year: "+this.year+", " + "value:" + this.value +"}"; } } 需求说明:1、交易年未2011年,并按交易金额排序2、获取城市并去重3、获取交易员所在城市为“Cambridge”的交易员,去重,并按交易员名字排序4、获取所有交易员名字,并排序,拼接成字符串5、交易员城市是否有在Milan的6、打印所有交易值,且交易员所在城市是Milan的7、找最大的值8、找最小的值需求实现范例:package com.example.study.java8.streams.demo; import java.util.Arrays; import java.util.Comparator; import java.util.List; import java.util.Optional; import static java.util.stream.Collectors.toList; /** * 交易员进行交易 */ public class StreamInAction { public static void main(String[] args) { Trader raoul = new Trader("Raoul", "Cambridge"); Trader mario = new Trader("Mario", "Milan"); Trader alan = new Trader("Alan", "Cambridge"); Trader brian = new Trader("Brian", "Cambridge"); List<Transaction> transactions = Arrays.asList( new Transaction(brian, 2011, 300), new Transaction(raoul, 2012, 1000), new Transaction(raoul, 2011, 400), new Transaction(mario, 2012, 710), new Transaction(mario, 2012, 700), new Transaction(alan, 2012, 950) ); //1、交易年未2011年,并按交易金额排序 transactions.stream() .filter(t -> t.getYear() == 2011) .sorted(Comparator.comparing(Transaction::getValue)) .collect(toList()) .forEach(System.out::println); System.out.println("==================================="); //2、获取城市并去重 transactions.stream() .map(t -> t.getTrader().getCity()) .distinct() .forEach(System.out::println); System.out.println("==================================="); //3、获取交易员所在城市为“Cambridge”的交易员,去重,并按交易员名字排序 transactions.stream() .map(t->t.getTrader()) .filter(g->"Cambridge".equals(g.getCity())) .distinct() .sorted(Comparator.comparing(Trader::getName)) .forEach(System.out::println); System.out.println("==================================="); //4、获取所有交易员名字,并排序,拼接成字符串 String result = transactions.stream() .map(t -> t.getTrader().getName()) .distinct() .sorted() .reduce("", (str1, str2) -> str1 + "\t" +str2); System.out.println(result); System.out.println("==================================="); //5、交易员城市是否有在Milan的 boolean anyMatch = transactions.stream() .anyMatch(t -> "Milan".equals(t.getTrader().getCity())); System.out.println(anyMatch); //或者 System.out.println("==================================="); boolean anyMatchMap = transactions.stream() .map(t -> t.getTrader()) .anyMatch(n -> "Milan".equals(n.getCity())); System.out.println(anyMatchMap); System.out.println("==================================="); //6、打印所有交易值,且交易员所在城市是Milan的。 transactions.stream() .filter(t->"Cambridge".equals(t.getTrader().getCity())) .map(Transaction::getValue) .sorted() .forEach(System.out::println); //7、找最大的值 System.out.println("==================================="); Optional<Integer> maxValue = transactions.stream() .map(Transaction::getValue) .reduce((i, j) -> i > j ? i : j); System.out.println(maxValue.get()); //8、找最小的值 System.out.println("==================================="); Optional<Integer> minValue = transactions.stream().map(t -> t.getValue()).reduce(Integer::min); System.out.println(minValue.get()); } }
-
JAVA8-Stream 数值格式 Stream数据类型1、mapToInt、mapToLong、mapToDouble可以将包装类拆箱成基本数据类型,节约内存空间范例:求和方式一:reduce实现 //方式一:reduce实现 List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10,6,5,4,3,2,1); list.stream().reduce(Integer::sum).ifPresent(System.out::println); 方式二:mapToInt //方式二:mapToInt list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10,6,5,4,3,2,1); IntStream mapToInt = list.stream().mapToInt(i -> i.intValue()); int sum = mapToInt.sum(); System.out.println(sum);方式三:mapToInt后用reduce实现 //方式三:mapToInt后用reduce实现 list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10,6,5,4,3,2,1); IntStream intStream = list.stream().mapToInt(i -> i.intValue()); int reduce = list.stream().mapToInt(i -> i.intValue()).reduce(0, (i, j) -> i + j); System.out.println(reduce);区别:直接使用reduce实现,使用的是包装类Integer,用mapToInt则可以转成int计算,占用内存更小。2、mapToObj可以将数据直接转成对象,代码量少很多。范例:需求:1--100,中满足勾股定律的数字 3\4\5 9,并返回成一个数组。1、原始分步骤写法: int a = 9; //创建1-100的数字 IntStream rangeClosed = IntStream.rangeClosed(1, 100); //找到满足勾股定律的数字 Stream<Integer> boxed = rangeClosed.filter(i -> Math.sqrt(a * a + i * i) % 1 == 0).boxed(); //将数字转变成int数组返回 Stream<int[]> stream = boxed.map(b -> new int[]{a, b, (int) Math.sqrt(a * a + b * b)}); //输出数组数据 stream.forEach(array->System.out.println("a="+array[0]+",b="+array[1]+",c="+array[2]));2、原始写法,代码简化后 int a = 9; IntStream.rangeClosed(1, 100) .filter(i->Math.sqrt(a*a + i*i)%1==0) .boxed() .map(b->new int[]{a,b,(int)Math.sqrt(a*a+b*b)}) .forEach(array->System.out.println("a="+array[0]+",b="+array[1]+",c="+array[2]));3、mapToObj实现 int a = 9; IntStream.rangeClosed(1, 100) .filter(i->Math.sqrt(a*a + i*i)%1==0) .mapToObj(b->new int[]{a,b,(int)Math.sqrt(a*a+b*b)}) .forEach(array->System.out.println("a="+array[0]+",b="+array[1]+",c="+array[2]));输出结果:a=9,b=12,c=15 a=9,b=40,c=41使用mapToObj,代码更简洁,直接将满足条件数据,转成一个数组对象。
-
JAVA8-Stream API 二、Stream API:filter、distinct、skip、limit被操作数据List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10,6,5,4,3,2,1);1、filter 过滤范例://filter 过滤 List<Integer> filterResult = list.stream().filter(i -> i % 2 == 0).collect(toList()); filterResult.stream().forEach(System.out::println);2、distinct 去重范例: //distinct 去重 List<Integer> distinctResult = list.stream().distinct().collect(toList()); distinctResult.stream().forEach(System.out::println);3、skip 截断范例: //skip 截断(跳过前面几个,超过长度,直接返回空) List<Integer> skipResult = list.stream().skip(5).collect(toList()); skipResult.stream().forEach(System.out::println);4、limit 查询几条范例: //limit 查询几条 List<Integer> limitResult = list.stream().limit(3).collect(toList()); limitResult.stream().forEach(System.out::println);二、Stream API:Map1、map 数据处理被操作数据List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10,6,5,4,3,2,1); List<Dish> menu = Arrays.asList( new Dish("pork", false, 800, Dish.Type.MEAT), new Dish("beef", false, 700, Dish.Type.MEAT), new Dish("chicken", false, 400, Dish.Type.MEAT), new Dish("french fries", true, 530, Dish.Type.OTHER), new Dish("rice", true, 350, Dish.Type.OTHER), new Dish("season fruit", true, 120, Dish.Type.OTHER), new Dish("pizza", true, 550, Dish.Type.OTHER), new Dish("prawns", false, 300, Dish.Type.FISH), new Dish("salmon", false, 450, Dish.Type.FISH)); String[] arrays = {"Hello","world"};范例1: //1、map List<Integer> mapResult = list.stream().map(i -> i * 2).collect(toList()); mapResult.stream().forEach(System.out::println);范例2: //2、map menu.stream().map(Dish::getName).forEach(System.out::println);范例3://3、flatMap 扁平化 //拆分成String[]: {h,e,l,l,o},{w,o,r,l,d} Stream<String[]> splitStream = Arrays.stream(arrays).map(s -> s.split("")); //flatMap扁平化,将{h,e,l,l,o},{w,o,r,l,d}每个数组转成Stream<String> Stream<String> stringStream = splitStream.flatMap(Arrays::stream); stringStream.distinct().forEach(System.out::println);打印结果:H e l o w r d三、Stream API:Match1、Match匹配范例:1.1、allMatch 全部满足条件 Stream<Integer> list = Arrays.stream(new Integer[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}); //1、allMatch 全部满足条件 boolean booleanAnyMath = list.allMatch(i -> i > 0); System.out.println(booleanAnyMath);1.2、anyMatch 任意一个满足条件 //2、anyMatch 任意一个满足条件 list = Arrays.stream(new Integer[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}); boolean anyMatch = list.anyMatch(i -> i > 9); System.out.println(anyMatch);1.3、noneMatch 没有一个满足 //3、noneMatch 没有一个满足 list = Arrays.stream(new Integer[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}); boolean noneMatch = list.noneMatch(i -> i == 11); System.out.println(noneMatch);四、Stream API:find2、find查找范例:2.1、findFirst 查找第一个 //1、findFirst 查找第一个 Optional<Integer> firstOptional = stream.filter(i -> i % 2 == 0).findFirst(); System.out.println(firstOptional); ```` **2.2、findAny 查找任意一个** stream = Arrays.stream(new Integer[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}); Optional<Integer> anyOptional = stream.filter(i -> i % 2 == 0).findAny(); System.out.println(anyOptional.get()); **2.3、没找到时,使用get()会直接抛出异常提示信息,会提示错误:No value present** ```java stream = Arrays.stream(new Integer[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}); Optional<Integer> noNumOptional = stream.filter(i -> i == 11).findAny(); System.out.println(noNumOptional.get());抛出异常提示: //抛出异常提示:No value present ```` **2.4、没找到时,Optional输出:Optional.empty,不抛异常** System.out.println(noNumOptional); *输出结果:*Optional.empty **3、orElse 如果没查找返回给定的值** 范例: **需求:查询数组中是否包含指定值,没有返回默认值。** ***3.1、原始写法*** 先写个方法,然后调用/* * 原始写法,查询数组中是否包含指定值,没有返回默认值 * @param values * @param defaultValue * @param predicate * @return */ public static int findDifineValue(Integer[] values, int defaultValue, Predicate<Integer> predicate){ for(int i : values){ if(predicate.test(i)){ return i; } } return defaultValue; } 调用原始写法: int findValueResult = findDifineValue(new Integer[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}, -1, i -> i == 9); System.out.println(findValueResult); ***3.2、orElse写法*** // orElse写法 如果没查找返回给定的值 stream = Arrays.stream(new Integer[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}); Optional<Integer> noNumOptional = stream.filter(i -> i == 11).findAny(); System.out.println(noNumOptional.orElse(-1));比原始写法简写很多。 ---------- **4、isPresent 判断是否存在,直接返回boolean值** stream = Arrays.stream(new Integer[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}); boolean isPresent = stream.filter(i->i==4).findAny().isPresent(); System.out.println(isPresent); **5、存在就打印出来,没有则不打印** stream = Arrays.stream(new Integer[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}); stream.filter(i->i==6).findAny().ifPresent(System.out::println); ** 6、还可以进行二次过滤** stream = Arrays.stream(new Integer[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}); //先Stream的filter过滤,然后得到Optional,再用Optional的filter过滤 stream.filter(i->i>8).findAny().filter(i->i<10).ifPresent(System.out::println);## 五、Stream API:reduce:聚合作用,根据reduce传入的Function条件进行聚合 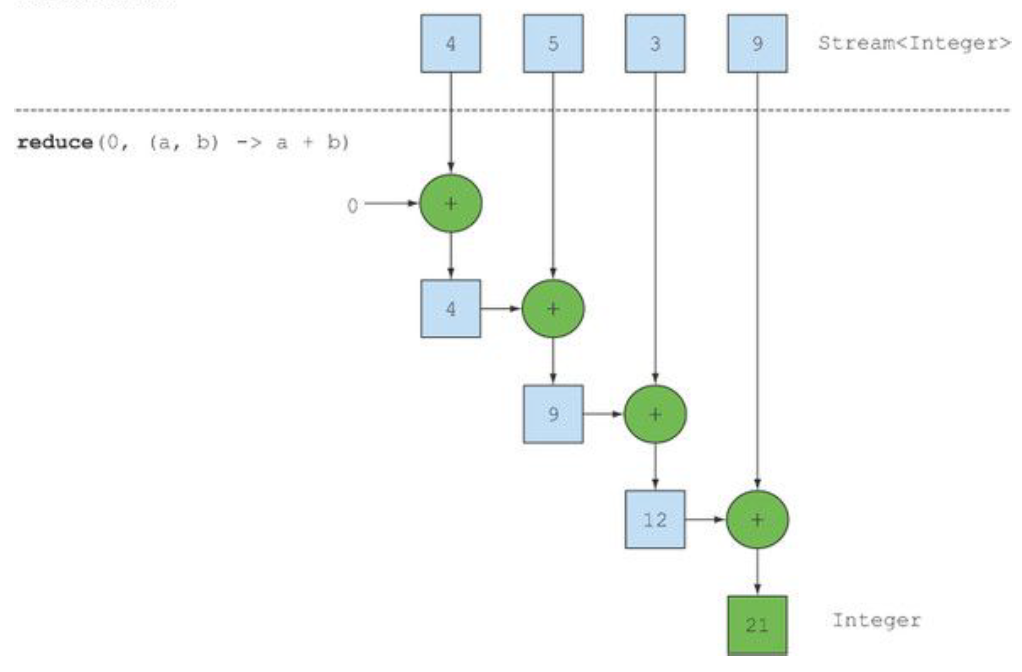 范例:package com.example.study.java8.streams;import java.util.Arrays;import java.util.List;/**Stream reduce:聚合作用,根据reduce传入的Function条件进行聚合用法:只要reduce里面参数满足funcion就可以 */public class StreamReduce {public static void main(String[] args) { //用法:只要reduce的参数满足Function就可以 //reduce(0, (i, j) -> i + j) List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10,6,5,4,3,2,1); Integer reduceResult = list.stream().reduce(0, (i, j) -> i + j); System.out.println(reduceResult); System.out.println("==================================="); //reduce((i,j)->i+j) list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10,6,5,4,3,2,1); list.stream().reduce((i,j)->i+j).ifPresent(System.out::println); System.out.println("==================================="); //reduce(Math::max) list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10,6,5,4,3,2,1); list.stream().reduce(Math::max).ifPresent(System.out::println); System.out.println("==================================="); //reduce(Integer::sum) list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10,6,5,4,3,2,1); list.stream().reduce(Integer::sum).ifPresent(System.out::println); }}
-
JAVA8-Stream创建 创建Stream创建Stream方式:创建Stream的方式1、通过Collection2、通过values3、通过Arrays4、通过file5、通过iterate创建,无限的创建6、通过Generate创建7、自定义Supplier,创建Stream使用范例1、Collection创建,输出值顺序与之前放入值顺序一致。范例: /** * 通过Collection创建Stream,数据顺序和放入顺序一致 * @return */ public static Stream<String> createStreamByCollection(){ List<String> list = Arrays.asList(new String("Hello"), new String("world"), new String("please")); return list.stream(); }2、values创建,输出值顺序与之前放入值顺序一致。范例: /** * 通过values创建Stream,顺序一直 * @return */ public static Stream<String> createStreamByValues(){ return Stream.of("Hello","world","please"); }3、Arrays创建,输出值顺序与之前放入值顺序一致。范例: /** * 3、通过Arrays创建,顺序一致 * @return */ public static Stream<String> createStreamByArrays(){ return Arrays.stream(new String[]{"Hello","world","please"}); }4、File创建范例: /** * 4、通过file创建 * @return */ public static Stream<String> createStreamByFile(){ Path path = Paths.get("D:\\software\\workspace\\IdeaProjects\\study\\study-java8\\src\\main\\java\\com\\example\\study\\java8\\streams\\CreateStream.java"); try { Stream<String> stream = Files.lines(path); return stream; } catch (IOException e) { throw new RuntimeException(e.getMessage()); } }5、iterate无限的创建范例: /** * 5、通过iterate创建,无限的创建 * @return */ public static Stream<Integer> createStreamByIterate(){ return Stream.iterate(0, n->n+2).limit(10); } 6、Generate创建范例: /** * 6、通过Generate创建 * @return */ public static Stream<Double> crateStreamByGenerate(){ return Stream.generate(Math::random).limit(10); }7、自定义Supplier,创建Stream范例: /** * 自定义Supplier,创建Stream * @return */ public static Stream<Obj> createStreamByDefine(){ return Stream.generate(new ObjSupplier()).limit(10); } static class ObjSupplier implements Supplier<Obj> { int index =0; Random random = new Random(System.currentTimeMillis()); @Override public Obj get() { index = random.nextInt(100); return new Obj(index, "Name->"+index); } } @Data @AllArgsConstructor @NoArgsConstructor @ToString static class Obj{ private Integer id; private String name; }熟悉创建Stream后,就是使用其api进行开发了。
-
JAVA8-Stream源码 Stream基本使用及特点Stream说明Stream操作分为:2组,//注意,流式管道操作,只能操作一次,否则报错。1、可连续操作: filter, map, and limit can be connected together to form a pipeline.2、操作中断collect causes the pipeline to be executed and closes it.使用范例:package com.example.study.java8.streams; import java.util.*; import java.util.stream.Stream; import static java.util.Comparator.comparing; import static java.util.stream.Collectors.toList; /** * Stream使用 * Stream操作分为:2组,//注意,流式管道操作,只能操作一次,否则报错 * You can see two groups of operations: * 1、可连续操作 * filter, map, and limit can be connected together to form a pipeline. * 2、操作中断 * collect causes the pipeline to be executed and closes it. */ public class SimpleStream { public static void main(String[] args) { List<Dish> menu = Arrays.asList( new Dish("pork", false, 800, Dish.Type.MEAT), new Dish("beef", false, 700, Dish.Type.MEAT), new Dish("chicken", false, 400, Dish.Type.MEAT), new Dish("french fries", true, 530, Dish.Type.OTHER), new Dish("rice", true, 350, Dish.Type.OTHER), new Dish("season fruit", true, 120, Dish.Type.OTHER), new Dish("pizza", true, 550, Dish.Type.OTHER), new Dish("prawns", false, 300, Dish.Type.FISH), new Dish("salmon", false, 450, Dish.Type.FISH)); Stream<Dish> stream = menu.stream(); stream.forEach(System.out::println); //注意,流式管道操作,只能操作一次,否则报错 //stream has already been operated upon or closed // stream.forEach(System.out::println); System.out.println("===================================="); //原始调用 List<String> namesByCollections = getDishNamesByCollections(menu); namesByCollections.stream().forEach(System.out::println); System.out.println("===================================="); //lambda stream调用 List<String> lambdaStreamNames = lambdaStream(menu); lambdaStreamNames.stream().forEach(System.out::println); } //原始写法 public static List<String> getDishNamesByCollections(List<Dish> menu) { List<Dish> caloriesDis = new ArrayList<>(); for (Dish dish : menu) { if (dish.getCalories() < 400) { caloriesDis.add(dish); } } Collections.sort(caloriesDis, (dish1, dish2) -> { return Integer.compare(dish1.getCalories(), dish2.getCalories()); }); List<String> names = new ArrayList<>(); for(Dish dish : caloriesDis){ names.add(dish.getName()); } return names; } //stream lambda处理 public static List<String> lambdaStream(List<Dish> menu){ return menu.stream().filter(dis -> dis.getCalories() < 400) .sorted(comparing(Dish::getCalories)) .map(Dish::getName).collect(toList()); } } 主要掌握Stream接口中常用方法。Stream源码:/* * Copyright (c) 2012, 2017, Oracle and/or its affiliates. All rights reserved. * ORACLE PROPRIETARY/CONFIDENTIAL. Use is subject to license terms. */ package java.util.stream; import java.nio.file.Files; import java.nio.file.Path; import java.util.Arrays; import java.util.Collection; import java.util.Comparator; import java.util.Objects; import java.util.Optional; import java.util.Spliterator; import java.util.Spliterators; import java.util.concurrent.ConcurrentHashMap; import java.util.function.BiConsumer; import java.util.function.BiFunction; import java.util.function.BinaryOperator; import java.util.function.Consumer; import java.util.function.Function; import java.util.function.IntFunction; import java.util.function.Predicate; import java.util.function.Supplier; import java.util.function.ToDoubleFunction; import java.util.function.ToIntFunction; import java.util.function.ToLongFunction; import java.util.function.UnaryOperator; /** * A sequence of elements supporting sequential and parallel aggregate * operations. The following example illustrates an aggregate operation using * {@link Stream} and {@link IntStream}: * * <pre>{@code * int sum = widgets.stream() * .filter(w -> w.getColor() == RED) * .mapToInt(w -> w.getWeight()) * .sum(); * }</pre> * * In this example, {@code widgets} is a {@code Collection<Widget>}. We create * a stream of {@code Widget} objects via {@link Collection#stream Collection.stream()}, * filter it to produce a stream containing only the red widgets, and then * transform it into a stream of {@code int} values representing the weight of * each red widget. Then this stream is summed to produce a total weight. * * <p>In addition to {@code Stream}, which is a stream of object references, * there are primitive specializations for {@link IntStream}, {@link LongStream}, * and {@link DoubleStream}, all of which are referred to as "streams" and * conform to the characteristics and restrictions described here. * * <p>To perform a computation, stream * <a href="package-summary.html#StreamOps">operations</a> are composed into a * <em>stream pipeline</em>. A stream pipeline consists of a source (which * might be an array, a collection, a generator function, an I/O channel, * etc), zero or more <em>intermediate operations</em> (which transform a * stream into another stream, such as {@link Stream#filter(Predicate)}), and a * <em>terminal operation</em> (which produces a result or side-effect, such * as {@link Stream#count()} or {@link Stream#forEach(Consumer)}). * Streams are lazy; computation on the source data is only performed when the * terminal operation is initiated, and source elements are consumed only * as needed. * * <p>A stream implementation is permitted significant latitude in optimizing * the computation of the result. For example, a stream implementation is free * to elide operations (or entire stages) from a stream pipeline -- and * therefore elide invocation of behavioral parameters -- if it can prove that * it would not affect the result of the computation. This means that * side-effects of behavioral parameters may not always be executed and should * not be relied upon, unless otherwise specified (such as by the terminal * operations {@code forEach} and {@code forEachOrdered}). (For a specific * example of such an optimization, see the API note documented on the * {@link #count} operation. For more detail, see the * <a href="package-summary.html#SideEffects">side-effects</a> section of the * stream package documentation.) * * <p>Collections and streams, while bearing some superficial similarities, * have different goals. Collections are primarily concerned with the efficient * management of, and access to, their elements. By contrast, streams do not * provide a means to directly access or manipulate their elements, and are * instead concerned with declaratively describing their source and the * computational operations which will be performed in aggregate on that source. * However, if the provided stream operations do not offer the desired * functionality, the {@link #iterator()} and {@link #spliterator()} operations * can be used to perform a controlled traversal. * * <p>A stream pipeline, like the "widgets" example above, can be viewed as * a <em>query</em> on the stream source. Unless the source was explicitly * designed for concurrent modification (such as a {@link ConcurrentHashMap}), * unpredictable or erroneous behavior may result from modifying the stream * source while it is being queried. * * <p>Most stream operations accept parameters that describe user-specified * behavior, such as the lambda expression {@code w -> w.getWeight()} passed to * {@code mapToInt} in the example above. To preserve correct behavior, * these <em>behavioral parameters</em>: * <ul> * <li>must be <a href="package-summary.html#NonInterference">non-interfering</a> * (they do not modify the stream source); and</li> * <li>in most cases must be <a href="package-summary.html#Statelessness">stateless</a> * (their result should not depend on any state that might change during execution * of the stream pipeline).</li> * </ul> * * <p>Such parameters are always instances of a * <a href="../function/package-summary.html">functional interface</a> such * as {@link java.util.function.Function}, and are often lambda expressions or * method references. Unless otherwise specified these parameters must be * <em>non-null</em>. * * <p>A stream should be operated on (invoking an intermediate or terminal stream * operation) only once. This rules out, for example, "forked" streams, where * the same source feeds two or more pipelines, or multiple traversals of the * same stream. A stream implementation may throw {@link IllegalStateException} * if it detects that the stream is being reused. However, since some stream * operations may return their receiver rather than a new stream object, it may * not be possible to detect reuse in all cases. * * <p>Streams have a {@link #close()} method and implement {@link AutoCloseable}. * Operating on a stream after it has been closed will throw {@link IllegalStateException}. * Most stream instances do not actually need to be closed after use, as they * are backed by collections, arrays, or generating functions, which require no * special resource management. Generally, only streams whose source is an IO channel, * such as those returned by {@link Files#lines(Path)}, will require closing. If a * stream does require closing, it must be opened as a resource within a try-with-resources * statement or similar control structure to ensure that it is closed promptly after its * operations have completed. * * <p>Stream pipelines may execute either sequentially or in * <a href="package-summary.html#Parallelism">parallel</a>. This * execution mode is a property of the stream. Streams are created * with an initial choice of sequential or parallel execution. (For example, * {@link Collection#stream() Collection.stream()} creates a sequential stream, * and {@link Collection#parallelStream() Collection.parallelStream()} creates * a parallel one.) This choice of execution mode may be modified by the * {@link #sequential()} or {@link #parallel()} methods, and may be queried with * the {@link #isParallel()} method. * * @param <T> the type of the stream elements * @since 1.8 * @see IntStream * @see LongStream * @see DoubleStream * @see <a href="package-summary.html">java.util.stream</a> */ public interface Stream<T> extends BaseStream<T, Stream<T>> { /** * Returns a stream consisting of the elements of this stream that match * the given predicate. * * <p>This is an <a href="package-summary.html#StreamOps">intermediate * operation</a>. * * @param predicate a <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * predicate to apply to each element to determine if it * should be included * @return the new stream */ Stream<T> filter(Predicate<? super T> predicate); /** * Returns a stream consisting of the results of applying the given * function to the elements of this stream. * * <p>This is an <a href="package-summary.html#StreamOps">intermediate * operation</a>. * * @param <R> The element type of the new stream * @param mapper a <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * function to apply to each element * @return the new stream */ <R> Stream<R> map(Function<? super T, ? extends R> mapper); /** * Returns an {@code IntStream} consisting of the results of applying the * given function to the elements of this stream. * * <p>This is an <a href="package-summary.html#StreamOps"> * intermediate operation</a>. * * @param mapper a <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * function to apply to each element * @return the new stream */ IntStream mapToInt(ToIntFunction<? super T> mapper); /** * Returns a {@code LongStream} consisting of the results of applying the * given function to the elements of this stream. * * <p>This is an <a href="package-summary.html#StreamOps">intermediate * operation</a>. * * @param mapper a <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * function to apply to each element * @return the new stream */ LongStream mapToLong(ToLongFunction<? super T> mapper); /** * Returns a {@code DoubleStream} consisting of the results of applying the * given function to the elements of this stream. * * <p>This is an <a href="package-summary.html#StreamOps">intermediate * operation</a>. * * @param mapper a <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * function to apply to each element * @return the new stream */ DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper); /** * Returns a stream consisting of the results of replacing each element of * this stream with the contents of a mapped stream produced by applying * the provided mapping function to each element. Each mapped stream is * {@link java.util.stream.BaseStream#close() closed} after its contents * have been placed into this stream. (If a mapped stream is {@code null} * an empty stream is used, instead.) * * <p>This is an <a href="package-summary.html#StreamOps">intermediate * operation</a>. * * @apiNote * The {@code flatMap()} operation has the effect of applying a one-to-many * transformation to the elements of the stream, and then flattening the * resulting elements into a new stream. * * <p><b>Examples.</b> * * <p>If {@code orders} is a stream of purchase orders, and each purchase * order contains a collection of line items, then the following produces a * stream containing all the line items in all the orders: * <pre>{@code * orders.flatMap(order -> order.getLineItems().stream())... * }</pre> * * <p>If {@code path} is the path to a file, then the following produces a * stream of the {@code words} contained in that file: * <pre>{@code * Stream<String> lines = Files.lines(path, StandardCharsets.UTF_8); * Stream<String> words = lines.flatMap(line -> Stream.of(line.split(" +"))); * }</pre> * The {@code mapper} function passed to {@code flatMap} splits a line, * using a simple regular expression, into an array of words, and then * creates a stream of words from that array. * * @param <R> The element type of the new stream * @param mapper a <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * function to apply to each element which produces a stream * of new values * @return the new stream */ <R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper); /** * Returns an {@code IntStream} consisting of the results of replacing each * element of this stream with the contents of a mapped stream produced by * applying the provided mapping function to each element. Each mapped * stream is {@link java.util.stream.BaseStream#close() closed} after its * contents have been placed into this stream. (If a mapped stream is * {@code null} an empty stream is used, instead.) * * <p>This is an <a href="package-summary.html#StreamOps">intermediate * operation</a>. * * @param mapper a <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * function to apply to each element which produces a stream * of new values * @return the new stream * @see #flatMap(Function) */ IntStream flatMapToInt(Function<? super T, ? extends IntStream> mapper); /** * Returns an {@code LongStream} consisting of the results of replacing each * element of this stream with the contents of a mapped stream produced by * applying the provided mapping function to each element. Each mapped * stream is {@link java.util.stream.BaseStream#close() closed} after its * contents have been placed into this stream. (If a mapped stream is * {@code null} an empty stream is used, instead.) * * <p>This is an <a href="package-summary.html#StreamOps">intermediate * operation</a>. * * @param mapper a <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * function to apply to each element which produces a stream * of new values * @return the new stream * @see #flatMap(Function) */ LongStream flatMapToLong(Function<? super T, ? extends LongStream> mapper); /** * Returns an {@code DoubleStream} consisting of the results of replacing * each element of this stream with the contents of a mapped stream produced * by applying the provided mapping function to each element. Each mapped * stream is {@link java.util.stream.BaseStream#close() closed} after its * contents have placed been into this stream. (If a mapped stream is * {@code null} an empty stream is used, instead.) * * <p>This is an <a href="package-summary.html#StreamOps">intermediate * operation</a>. * * @param mapper a <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * function to apply to each element which produces a stream * of new values * @return the new stream * @see #flatMap(Function) */ DoubleStream flatMapToDouble(Function<? super T, ? extends DoubleStream> mapper); /** * Returns a stream consisting of the distinct elements (according to * {@link Object#equals(Object)}) of this stream. * * <p>For ordered streams, the selection of distinct elements is stable * (for duplicated elements, the element appearing first in the encounter * order is preserved.) For unordered streams, no stability guarantees * are made. * * <p>This is a <a href="package-summary.html#StreamOps">stateful * intermediate operation</a>. * * @apiNote * Preserving stability for {@code distinct()} in parallel pipelines is * relatively expensive (requires that the operation act as a full barrier, * with substantial buffering overhead), and stability is often not needed. * Using an unordered stream source (such as {@link #generate(Supplier)}) * or removing the ordering constraint with {@link #unordered()} may result * in significantly more efficient execution for {@code distinct()} in parallel * pipelines, if the semantics of your situation permit. If consistency * with encounter order is required, and you are experiencing poor performance * or memory utilization with {@code distinct()} in parallel pipelines, * switching to sequential execution with {@link #sequential()} may improve * performance. * * @return the new stream */ Stream<T> distinct(); /** * Returns a stream consisting of the elements of this stream, sorted * according to natural order. If the elements of this stream are not * {@code Comparable}, a {@code java.lang.ClassCastException} may be thrown * when the terminal operation is executed. * * <p>For ordered streams, the sort is stable. For unordered streams, no * stability guarantees are made. * * <p>This is a <a href="package-summary.html#StreamOps">stateful * intermediate operation</a>. * * @return the new stream */ Stream<T> sorted(); /** * Returns a stream consisting of the elements of this stream, sorted * according to the provided {@code Comparator}. * * <p>For ordered streams, the sort is stable. For unordered streams, no * stability guarantees are made. * * <p>This is a <a href="package-summary.html#StreamOps">stateful * intermediate operation</a>. * * @param comparator a <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * {@code Comparator} to be used to compare stream elements * @return the new stream */ Stream<T> sorted(Comparator<? super T> comparator); /** * Returns a stream consisting of the elements of this stream, additionally * performing the provided action on each element as elements are consumed * from the resulting stream. * * <p>This is an <a href="package-summary.html#StreamOps">intermediate * operation</a>. * * <p>For parallel stream pipelines, the action may be called at * whatever time and in whatever thread the element is made available by the * upstream operation. If the action modifies shared state, * it is responsible for providing the required synchronization. * * @apiNote This method exists mainly to support debugging, where you want * to see the elements as they flow past a certain point in a pipeline: * <pre>{@code * Stream.of("one", "two", "three", "four") * .filter(e -> e.length() > 3) * .peek(e -> System.out.println("Filtered value: " + e)) * .map(String::toUpperCase) * .peek(e -> System.out.println("Mapped value: " + e)) * .collect(Collectors.toList()); * }</pre> * * <p>In cases where the stream implementation is able to optimize away the * production of some or all the elements (such as with short-circuiting * operations like {@code findFirst}, or in the example described in * {@link #count}), the action will not be invoked for those elements. * * @param action a <a href="package-summary.html#NonInterference"> * non-interfering</a> action to perform on the elements as * they are consumed from the stream * @return the new stream */ Stream<T> peek(Consumer<? super T> action); /** * Returns a stream consisting of the elements of this stream, truncated * to be no longer than {@code maxSize} in length. * * <p>This is a <a href="package-summary.html#StreamOps">short-circuiting * stateful intermediate operation</a>. * * @apiNote * While {@code limit()} is generally a cheap operation on sequential * stream pipelines, it can be quite expensive on ordered parallel pipelines, * especially for large values of {@code maxSize}, since {@code limit(n)} * is constrained to return not just any <em>n</em> elements, but the * <em>first n</em> elements in the encounter order. Using an unordered * stream source (such as {@link #generate(Supplier)}) or removing the * ordering constraint with {@link #unordered()} may result in significant * speedups of {@code limit()} in parallel pipelines, if the semantics of * your situation permit. If consistency with encounter order is required, * and you are experiencing poor performance or memory utilization with * {@code limit()} in parallel pipelines, switching to sequential execution * with {@link #sequential()} may improve performance. * * @param maxSize the number of elements the stream should be limited to * @return the new stream * @throws IllegalArgumentException if {@code maxSize} is negative */ Stream<T> limit(long maxSize); /** * Returns a stream consisting of the remaining elements of this stream * after discarding the first {@code n} elements of the stream. * If this stream contains fewer than {@code n} elements then an * empty stream will be returned. * * <p>This is a <a href="package-summary.html#StreamOps">stateful * intermediate operation</a>. * * @apiNote * While {@code skip()} is generally a cheap operation on sequential * stream pipelines, it can be quite expensive on ordered parallel pipelines, * especially for large values of {@code n}, since {@code skip(n)} * is constrained to skip not just any <em>n</em> elements, but the * <em>first n</em> elements in the encounter order. Using an unordered * stream source (such as {@link #generate(Supplier)}) or removing the * ordering constraint with {@link #unordered()} may result in significant * speedups of {@code skip()} in parallel pipelines, if the semantics of * your situation permit. If consistency with encounter order is required, * and you are experiencing poor performance or memory utilization with * {@code skip()} in parallel pipelines, switching to sequential execution * with {@link #sequential()} may improve performance. * * @param n the number of leading elements to skip * @return the new stream * @throws IllegalArgumentException if {@code n} is negative */ Stream<T> skip(long n); /** * Returns, if this stream is ordered, a stream consisting of the longest * prefix of elements taken from this stream that match the given predicate. * Otherwise returns, if this stream is unordered, a stream consisting of a * subset of elements taken from this stream that match the given predicate. * * <p>If this stream is ordered then the longest prefix is a contiguous * sequence of elements of this stream that match the given predicate. The * first element of the sequence is the first element of this stream, and * the element immediately following the last element of the sequence does * not match the given predicate. * * <p>If this stream is unordered, and some (but not all) elements of this * stream match the given predicate, then the behavior of this operation is * nondeterministic; it is free to take any subset of matching elements * (which includes the empty set). * * <p>Independent of whether this stream is ordered or unordered if all * elements of this stream match the given predicate then this operation * takes all elements (the result is the same as the input), or if no * elements of the stream match the given predicate then no elements are * taken (the result is an empty stream). * * <p>This is a <a href="package-summary.html#StreamOps">short-circuiting * stateful intermediate operation</a>. * * @implSpec * The default implementation obtains the {@link #spliterator() spliterator} * of this stream, wraps that spliterator so as to support the semantics * of this operation on traversal, and returns a new stream associated with * the wrapped spliterator. The returned stream preserves the execution * characteristics of this stream (namely parallel or sequential execution * as per {@link #isParallel()}) but the wrapped spliterator may choose to * not support splitting. When the returned stream is closed, the close * handlers for both the returned and this stream are invoked. * * @apiNote * While {@code takeWhile()} is generally a cheap operation on sequential * stream pipelines, it can be quite expensive on ordered parallel * pipelines, since the operation is constrained to return not just any * valid prefix, but the longest prefix of elements in the encounter order. * Using an unordered stream source (such as {@link #generate(Supplier)}) or * removing the ordering constraint with {@link #unordered()} may result in * significant speedups of {@code takeWhile()} in parallel pipelines, if the * semantics of your situation permit. If consistency with encounter order * is required, and you are experiencing poor performance or memory * utilization with {@code takeWhile()} in parallel pipelines, switching to * sequential execution with {@link #sequential()} may improve performance. * * @param predicate a <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * predicate to apply to elements to determine the longest * prefix of elements. * @return the new stream * @since 9 */ default Stream<T> takeWhile(Predicate<? super T> predicate) { Objects.requireNonNull(predicate); // Reuses the unordered spliterator, which, when encounter is present, // is safe to use as long as it configured not to split return StreamSupport.stream( new WhileOps.UnorderedWhileSpliterator.OfRef.Taking<>(spliterator(), true, predicate), isParallel()).onClose(this::close); } /** * Returns, if this stream is ordered, a stream consisting of the remaining * elements of this stream after dropping the longest prefix of elements * that match the given predicate. Otherwise returns, if this stream is * unordered, a stream consisting of the remaining elements of this stream * after dropping a subset of elements that match the given predicate. * * <p>If this stream is ordered then the longest prefix is a contiguous * sequence of elements of this stream that match the given predicate. The * first element of the sequence is the first element of this stream, and * the element immediately following the last element of the sequence does * not match the given predicate. * * <p>If this stream is unordered, and some (but not all) elements of this * stream match the given predicate, then the behavior of this operation is * nondeterministic; it is free to drop any subset of matching elements * (which includes the empty set). * * <p>Independent of whether this stream is ordered or unordered if all * elements of this stream match the given predicate then this operation * drops all elements (the result is an empty stream), or if no elements of * the stream match the given predicate then no elements are dropped (the * result is the same as the input). * * <p>This is a <a href="package-summary.html#StreamOps">stateful * intermediate operation</a>. * * @implSpec * The default implementation obtains the {@link #spliterator() spliterator} * of this stream, wraps that spliterator so as to support the semantics * of this operation on traversal, and returns a new stream associated with * the wrapped spliterator. The returned stream preserves the execution * characteristics of this stream (namely parallel or sequential execution * as per {@link #isParallel()}) but the wrapped spliterator may choose to * not support splitting. When the returned stream is closed, the close * handlers for both the returned and this stream are invoked. * * @apiNote * While {@code dropWhile()} is generally a cheap operation on sequential * stream pipelines, it can be quite expensive on ordered parallel * pipelines, since the operation is constrained to return not just any * valid prefix, but the longest prefix of elements in the encounter order. * Using an unordered stream source (such as {@link #generate(Supplier)}) or * removing the ordering constraint with {@link #unordered()} may result in * significant speedups of {@code dropWhile()} in parallel pipelines, if the * semantics of your situation permit. If consistency with encounter order * is required, and you are experiencing poor performance or memory * utilization with {@code dropWhile()} in parallel pipelines, switching to * sequential execution with {@link #sequential()} may improve performance. * * @param predicate a <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * predicate to apply to elements to determine the longest * prefix of elements. * @return the new stream * @since 9 */ default Stream<T> dropWhile(Predicate<? super T> predicate) { Objects.requireNonNull(predicate); // Reuses the unordered spliterator, which, when encounter is present, // is safe to use as long as it configured not to split return StreamSupport.stream( new WhileOps.UnorderedWhileSpliterator.OfRef.Dropping<>(spliterator(), true, predicate), isParallel()).onClose(this::close); } /** * Performs an action for each element of this stream. * * <p>This is a <a href="package-summary.html#StreamOps">terminal * operation</a>. * * <p>The behavior of this operation is explicitly nondeterministic. * For parallel stream pipelines, this operation does <em>not</em> * guarantee to respect the encounter order of the stream, as doing so * would sacrifice the benefit of parallelism. For any given element, the * action may be performed at whatever time and in whatever thread the * library chooses. If the action accesses shared state, it is * responsible for providing the required synchronization. * * @param action a <a href="package-summary.html#NonInterference"> * non-interfering</a> action to perform on the elements */ void forEach(Consumer<? super T> action); /** * Performs an action for each element of this stream, in the encounter * order of the stream if the stream has a defined encounter order. * * <p>This is a <a href="package-summary.html#StreamOps">terminal * operation</a>. * * <p>This operation processes the elements one at a time, in encounter * order if one exists. Performing the action for one element * <a href="../concurrent/package-summary.html#MemoryVisibility"><i>happens-before</i></a> * performing the action for subsequent elements, but for any given element, * the action may be performed in whatever thread the library chooses. * * @param action a <a href="package-summary.html#NonInterference"> * non-interfering</a> action to perform on the elements * @see #forEach(Consumer) */ void forEachOrdered(Consumer<? super T> action); /** * Returns an array containing the elements of this stream. * * <p>This is a <a href="package-summary.html#StreamOps">terminal * operation</a>. * * @return an array, whose {@linkplain Class#getComponentType runtime component * type} is {@code Object}, containing the elements of this stream */ Object[] toArray(); /** * Returns an array containing the elements of this stream, using the * provided {@code generator} function to allocate the returned array, as * well as any additional arrays that might be required for a partitioned * execution or for resizing. * * <p>This is a <a href="package-summary.html#StreamOps">terminal * operation</a>. * * @apiNote * The generator function takes an integer, which is the size of the * desired array, and produces an array of the desired size. This can be * concisely expressed with an array constructor reference: * <pre>{@code * Person[] men = people.stream() * .filter(p -> p.getGender() == MALE) * .toArray(Person[]::new); * }</pre> * * @param <A> the component type of the resulting array * @param generator a function which produces a new array of the desired * type and the provided length * @return an array containing the elements in this stream * @throws ArrayStoreException if the runtime type of any element of this * stream is not assignable to the {@linkplain Class#getComponentType * runtime component type} of the generated array */ <A> A[] toArray(IntFunction<A[]> generator); /** * Performs a <a href="package-summary.html#Reduction">reduction</a> on the * elements of this stream, using the provided identity value and an * <a href="package-summary.html#Associativity">associative</a> * accumulation function, and returns the reduced value. This is equivalent * to: * <pre>{@code * T result = identity; * for (T element : this stream) * result = accumulator.apply(result, element) * return result; * }</pre> * * but is not constrained to execute sequentially. * * <p>The {@code identity} value must be an identity for the accumulator * function. This means that for all {@code t}, * {@code accumulator.apply(identity, t)} is equal to {@code t}. * The {@code accumulator} function must be an * <a href="package-summary.html#Associativity">associative</a> function. * * <p>This is a <a href="package-summary.html#StreamOps">terminal * operation</a>. * * @apiNote Sum, min, max, average, and string concatenation are all special * cases of reduction. Summing a stream of numbers can be expressed as: * * <pre>{@code * Integer sum = integers.reduce(0, (a, b) -> a+b); * }</pre> * * or: * * <pre>{@code * Integer sum = integers.reduce(0, Integer::sum); * }</pre> * * <p>While this may seem a more roundabout way to perform an aggregation * compared to simply mutating a running total in a loop, reduction * operations parallelize more gracefully, without needing additional * synchronization and with greatly reduced risk of data races. * * @param identity the identity value for the accumulating function * @param accumulator an <a href="package-summary.html#Associativity">associative</a>, * <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * function for combining two values * @return the result of the reduction */ T reduce(T identity, BinaryOperator<T> accumulator); /** * Performs a <a href="package-summary.html#Reduction">reduction</a> on the * elements of this stream, using an * <a href="package-summary.html#Associativity">associative</a> accumulation * function, and returns an {@code Optional} describing the reduced value, * if any. This is equivalent to: * <pre>{@code * boolean foundAny = false; * T result = null; * for (T element : this stream) { * if (!foundAny) { * foundAny = true; * result = element; * } * else * result = accumulator.apply(result, element); * } * return foundAny ? Optional.of(result) : Optional.empty(); * }</pre> * * but is not constrained to execute sequentially. * * <p>The {@code accumulator} function must be an * <a href="package-summary.html#Associativity">associative</a> function. * * <p>This is a <a href="package-summary.html#StreamOps">terminal * operation</a>. * * @param accumulator an <a href="package-summary.html#Associativity">associative</a>, * <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * function for combining two values * @return an {@link Optional} describing the result of the reduction * @throws NullPointerException if the result of the reduction is null * @see #reduce(Object, BinaryOperator) * @see #min(Comparator) * @see #max(Comparator) */ Optional<T> reduce(BinaryOperator<T> accumulator); /** * Performs a <a href="package-summary.html#Reduction">reduction</a> on the * elements of this stream, using the provided identity, accumulation and * combining functions. This is equivalent to: * <pre>{@code * U result = identity; * for (T element : this stream) * result = accumulator.apply(result, element) * return result; * }</pre> * * but is not constrained to execute sequentially. * * <p>The {@code identity} value must be an identity for the combiner * function. This means that for all {@code u}, {@code combiner(identity, u)} * is equal to {@code u}. Additionally, the {@code combiner} function * must be compatible with the {@code accumulator} function; for all * {@code u} and {@code t}, the following must hold: * <pre>{@code * combiner.apply(u, accumulator.apply(identity, t)) == accumulator.apply(u, t) * }</pre> * * <p>This is a <a href="package-summary.html#StreamOps">terminal * operation</a>. * * @apiNote Many reductions using this form can be represented more simply * by an explicit combination of {@code map} and {@code reduce} operations. * The {@code accumulator} function acts as a fused mapper and accumulator, * which can sometimes be more efficient than separate mapping and reduction, * such as when knowing the previously reduced value allows you to avoid * some computation. * * @param <U> The type of the result * @param identity the identity value for the combiner function * @param accumulator an <a href="package-summary.html#Associativity">associative</a>, * <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * function for incorporating an additional element into a result * @param combiner an <a href="package-summary.html#Associativity">associative</a>, * <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * function for combining two values, which must be * compatible with the accumulator function * @return the result of the reduction * @see #reduce(BinaryOperator) * @see #reduce(Object, BinaryOperator) */ <U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner); /** * Performs a <a href="package-summary.html#MutableReduction">mutable * reduction</a> operation on the elements of this stream. A mutable * reduction is one in which the reduced value is a mutable result container, * such as an {@code ArrayList}, and elements are incorporated by updating * the state of the result rather than by replacing the result. This * produces a result equivalent to: * <pre>{@code * R result = supplier.get(); * for (T element : this stream) * accumulator.accept(result, element); * return result; * }</pre> * * <p>Like {@link #reduce(Object, BinaryOperator)}, {@code collect} operations * can be parallelized without requiring additional synchronization. * * <p>This is a <a href="package-summary.html#StreamOps">terminal * operation</a>. * * @apiNote There are many existing classes in the JDK whose signatures are * well-suited for use with method references as arguments to {@code collect()}. * For example, the following will accumulate strings into an {@code ArrayList}: * <pre>{@code * List<String> asList = stringStream.collect(ArrayList::new, ArrayList::add, * ArrayList::addAll); * }</pre> * * <p>The following will take a stream of strings and concatenates them into a * single string: * <pre>{@code * String concat = stringStream.collect(StringBuilder::new, StringBuilder::append, * StringBuilder::append) * .toString(); * }</pre> * * @param <R> the type of the mutable result container * @param supplier a function that creates a new mutable result container. * For a parallel execution, this function may be called * multiple times and must return a fresh value each time. * @param accumulator an <a href="package-summary.html#Associativity">associative</a>, * <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * function that must fold an element into a result * container. * @param combiner an <a href="package-summary.html#Associativity">associative</a>, * <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * function that accepts two partial result containers * and merges them, which must be compatible with the * accumulator function. The combiner function must fold * the elements from the second result container into the * first result container. * @return the result of the reduction */ <R> R collect(Supplier<R> supplier, BiConsumer<R, ? super T> accumulator, BiConsumer<R, R> combiner); /** * Performs a <a href="package-summary.html#MutableReduction">mutable * reduction</a> operation on the elements of this stream using a * {@code Collector}. A {@code Collector} * encapsulates the functions used as arguments to * {@link #collect(Supplier, BiConsumer, BiConsumer)}, allowing for reuse of * collection strategies and composition of collect operations such as * multiple-level grouping or partitioning. * * <p>If the stream is parallel, and the {@code Collector} * is {@link Collector.Characteristics#CONCURRENT concurrent}, and * either the stream is unordered or the collector is * {@link Collector.Characteristics#UNORDERED unordered}, * then a concurrent reduction will be performed (see {@link Collector} for * details on concurrent reduction.) * * <p>This is a <a href="package-summary.html#StreamOps">terminal * operation</a>. * * <p>When executed in parallel, multiple intermediate results may be * instantiated, populated, and merged so as to maintain isolation of * mutable data structures. Therefore, even when executed in parallel * with non-thread-safe data structures (such as {@code ArrayList}), no * additional synchronization is needed for a parallel reduction. * * @apiNote * The following will accumulate strings into an ArrayList: * <pre>{@code * List<String> asList = stringStream.collect(Collectors.toList()); * }</pre> * * <p>The following will classify {@code Person} objects by city: * <pre>{@code * Map<String, List<Person>> peopleByCity * = personStream.collect(Collectors.groupingBy(Person::getCity)); * }</pre> * * <p>The following will classify {@code Person} objects by state and city, * cascading two {@code Collector}s together: * <pre>{@code * Map<String, Map<String, List<Person>>> peopleByStateAndCity * = personStream.collect(Collectors.groupingBy(Person::getState, * Collectors.groupingBy(Person::getCity))); * }</pre> * * @param <R> the type of the result * @param <A> the intermediate accumulation type of the {@code Collector} * @param collector the {@code Collector} describing the reduction * @return the result of the reduction * @see #collect(Supplier, BiConsumer, BiConsumer) * @see Collectors */ <R, A> R collect(Collector<? super T, A, R> collector); /** * Returns the minimum element of this stream according to the provided * {@code Comparator}. This is a special case of a * <a href="package-summary.html#Reduction">reduction</a>. * * <p>This is a <a href="package-summary.html#StreamOps">terminal operation</a>. * * @param comparator a <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * {@code Comparator} to compare elements of this stream * @return an {@code Optional} describing the minimum element of this stream, * or an empty {@code Optional} if the stream is empty * @throws NullPointerException if the minimum element is null */ Optional<T> min(Comparator<? super T> comparator); /** * Returns the maximum element of this stream according to the provided * {@code Comparator}. This is a special case of a * <a href="package-summary.html#Reduction">reduction</a>. * * <p>This is a <a href="package-summary.html#StreamOps">terminal * operation</a>. * * @param comparator a <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * {@code Comparator} to compare elements of this stream * @return an {@code Optional} describing the maximum element of this stream, * or an empty {@code Optional} if the stream is empty * @throws NullPointerException if the maximum element is null */ Optional<T> max(Comparator<? super T> comparator); /** * Returns the count of elements in this stream. This is a special case of * a <a href="package-summary.html#Reduction">reduction</a> and is * equivalent to: * <pre>{@code * return mapToLong(e -> 1L).sum(); * }</pre> * * <p>This is a <a href="package-summary.html#StreamOps">terminal operation</a>. * * @apiNote * An implementation may choose to not execute the stream pipeline (either * sequentially or in parallel) if it is capable of computing the count * directly from the stream source. In such cases no source elements will * be traversed and no intermediate operations will be evaluated. * Behavioral parameters with side-effects, which are strongly discouraged * except for harmless cases such as debugging, may be affected. For * example, consider the following stream: * <pre>{@code * List<String> l = Arrays.asList("A", "B", "C", "D"); * long count = l.stream().peek(System.out::println).count(); * }</pre> * The number of elements covered by the stream source, a {@code List}, is * known and the intermediate operation, {@code peek}, does not inject into * or remove elements from the stream (as may be the case for * {@code flatMap} or {@code filter} operations). Thus the count is the * size of the {@code List} and there is no need to execute the pipeline * and, as a side-effect, print out the list elements. * * @return the count of elements in this stream */ long count(); /** * Returns whether any elements of this stream match the provided * predicate. May not evaluate the predicate on all elements if not * necessary for determining the result. If the stream is empty then * {@code false} is returned and the predicate is not evaluated. * * <p>This is a <a href="package-summary.html#StreamOps">short-circuiting * terminal operation</a>. * * @apiNote * This method evaluates the <em>existential quantification</em> of the * predicate over the elements of the stream (for some x P(x)). * * @param predicate a <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * predicate to apply to elements of this stream * @return {@code true} if any elements of the stream match the provided * predicate, otherwise {@code false} */ boolean anyMatch(Predicate<? super T> predicate); /** * Returns whether all elements of this stream match the provided predicate. * May not evaluate the predicate on all elements if not necessary for * determining the result. If the stream is empty then {@code true} is * returned and the predicate is not evaluated. * * <p>This is a <a href="package-summary.html#StreamOps">short-circuiting * terminal operation</a>. * * @apiNote * This method evaluates the <em>universal quantification</em> of the * predicate over the elements of the stream (for all x P(x)). If the * stream is empty, the quantification is said to be <em>vacuously * satisfied</em> and is always {@code true} (regardless of P(x)). * * @param predicate a <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * predicate to apply to elements of this stream * @return {@code true} if either all elements of the stream match the * provided predicate or the stream is empty, otherwise {@code false} */ boolean allMatch(Predicate<? super T> predicate); /** * Returns whether no elements of this stream match the provided predicate. * May not evaluate the predicate on all elements if not necessary for * determining the result. If the stream is empty then {@code true} is * returned and the predicate is not evaluated. * * <p>This is a <a href="package-summary.html#StreamOps">short-circuiting * terminal operation</a>. * * @apiNote * This method evaluates the <em>universal quantification</em> of the * negated predicate over the elements of the stream (for all x ~P(x)). If * the stream is empty, the quantification is said to be vacuously satisfied * and is always {@code true}, regardless of P(x). * * @param predicate a <a href="package-summary.html#NonInterference">non-interfering</a>, * <a href="package-summary.html#Statelessness">stateless</a> * predicate to apply to elements of this stream * @return {@code true} if either no elements of the stream match the * provided predicate or the stream is empty, otherwise {@code false} */ boolean noneMatch(Predicate<? super T> predicate); /** * Returns an {@link Optional} describing the first element of this stream, * or an empty {@code Optional} if the stream is empty. If the stream has * no encounter order, then any element may be returned. * * <p>This is a <a href="package-summary.html#StreamOps">short-circuiting * terminal operation</a>. * * @return an {@code Optional} describing the first element of this stream, * or an empty {@code Optional} if the stream is empty * @throws NullPointerException if the element selected is null */ Optional<T> findFirst(); /** * Returns an {@link Optional} describing some element of the stream, or an * empty {@code Optional} if the stream is empty. * * <p>This is a <a href="package-summary.html#StreamOps">short-circuiting * terminal operation</a>. * * <p>The behavior of this operation is explicitly nondeterministic; it is * free to select any element in the stream. This is to allow for maximal * performance in parallel operations; the cost is that multiple invocations * on the same source may not return the same result. (If a stable result * is desired, use {@link #findFirst()} instead.) * * @return an {@code Optional} describing some element of this stream, or an * empty {@code Optional} if the stream is empty * @throws NullPointerException if the element selected is null * @see #findFirst() */ Optional<T> findAny(); // Static factories /** * Returns a builder for a {@code Stream}. * * @param <T> type of elements * @return a stream builder */ public static<T> Builder<T> builder() { return new Streams.StreamBuilderImpl<>(); } /** * Returns an empty sequential {@code Stream}. * * @param <T> the type of stream elements * @return an empty sequential stream */ public static<T> Stream<T> empty() { return StreamSupport.stream(Spliterators.<T>emptySpliterator(), false); } /** * Returns a sequential {@code Stream} containing a single element. * * @param t the single element * @param <T> the type of stream elements * @return a singleton sequential stream */ public static<T> Stream<T> of(T t) { return StreamSupport.stream(new Streams.StreamBuilderImpl<>(t), false); } /** * Returns a sequential {@code Stream} containing a single element, if * non-null, otherwise returns an empty {@code Stream}. * * @param t the single element * @param <T> the type of stream elements * @return a stream with a single element if the specified element * is non-null, otherwise an empty stream * @since 9 */ public static<T> Stream<T> ofNullable(T t) { return t == null ? Stream.empty() : StreamSupport.stream(new Streams.StreamBuilderImpl<>(t), false); } /** * Returns a sequential ordered stream whose elements are the specified values. * * @param <T> the type of stream elements * @param values the elements of the new stream * @return the new stream */ @SafeVarargs @SuppressWarnings("varargs") // Creating a stream from an array is safe public static<T> Stream<T> of(T... values) { return Arrays.stream(values); } /** * Returns an infinite sequential ordered {@code Stream} produced by iterative * application of a function {@code f} to an initial element {@code seed}, * producing a {@code Stream} consisting of {@code seed}, {@code f(seed)}, * {@code f(f(seed))}, etc. * * <p>The first element (position {@code 0}) in the {@code Stream} will be * the provided {@code seed}. For {@code n > 0}, the element at position * {@code n}, will be the result of applying the function {@code f} to the * element at position {@code n - 1}. * * <p>The action of applying {@code f} for one element * <a href="../concurrent/package-summary.html#MemoryVisibility"><i>happens-before</i></a> * the action of applying {@code f} for subsequent elements. For any given * element the action may be performed in whatever thread the library * chooses. * * @param <T> the type of stream elements * @param seed the initial element * @param f a function to be applied to the previous element to produce * a new element * @return a new sequential {@code Stream} */ public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f) { Objects.requireNonNull(f); Spliterator<T> spliterator = new Spliterators.AbstractSpliterator<>(Long.MAX_VALUE, Spliterator.ORDERED | Spliterator.IMMUTABLE) { T prev; boolean started; @Override public boolean tryAdvance(Consumer<? super T> action) { Objects.requireNonNull(action); T t; if (started) t = f.apply(prev); else { t = seed; started = true; } action.accept(prev = t); return true; } }; return StreamSupport.stream(spliterator, false); } /** * Returns a sequential ordered {@code Stream} produced by iterative * application of the given {@code next} function to an initial element, * conditioned on satisfying the given {@code hasNext} predicate. The * stream terminates as soon as the {@code hasNext} predicate returns false. * * <p>{@code Stream.iterate} should produce the same sequence of elements as * produced by the corresponding for-loop: * <pre>{@code * for (T index=seed; hasNext.test(index); index = next.apply(index)) { * ... * } * }</pre> * * <p>The resulting sequence may be empty if the {@code hasNext} predicate * does not hold on the seed value. Otherwise the first element will be the * supplied {@code seed} value, the next element (if present) will be the * result of applying the {@code next} function to the {@code seed} value, * and so on iteratively until the {@code hasNext} predicate indicates that * the stream should terminate. * * <p>The action of applying the {@code hasNext} predicate to an element * <a href="../concurrent/package-summary.html#MemoryVisibility"><i>happens-before</i></a> * the action of applying the {@code next} function to that element. The * action of applying the {@code next} function for one element * <i>happens-before</i> the action of applying the {@code hasNext} * predicate for subsequent elements. For any given element an action may * be performed in whatever thread the library chooses. * * @param <T> the type of stream elements * @param seed the initial element * @param hasNext a predicate to apply to elements to determine when the * stream must terminate. * @param next a function to be applied to the previous element to produce * a new element * @return a new sequential {@code Stream} * @since 9 */ public static<T> Stream<T> iterate(T seed, Predicate<? super T> hasNext, UnaryOperator<T> next) { Objects.requireNonNull(next); Objects.requireNonNull(hasNext); Spliterator<T> spliterator = new Spliterators.AbstractSpliterator<>(Long.MAX_VALUE, Spliterator.ORDERED | Spliterator.IMMUTABLE) { T prev; boolean started, finished; @Override public boolean tryAdvance(Consumer<? super T> action) { Objects.requireNonNull(action); if (finished) return false; T t; if (started) t = next.apply(prev); else { t = seed; started = true; } if (!hasNext.test(t)) { prev = null; finished = true; return false; } action.accept(prev = t); return true; } @Override public void forEachRemaining(Consumer<? super T> action) { Objects.requireNonNull(action); if (finished) return; finished = true; T t = started ? next.apply(prev) : seed; prev = null; while (hasNext.test(t)) { action.accept(t); t = next.apply(t); } } }; return StreamSupport.stream(spliterator, false); } /** * Returns an infinite sequential unordered stream where each element is * generated by the provided {@code Supplier}. This is suitable for * generating constant streams, streams of random elements, etc. * * @param <T> the type of stream elements * @param s the {@code Supplier} of generated elements * @return a new infinite sequential unordered {@code Stream} */ public static<T> Stream<T> generate(Supplier<? extends T> s) { Objects.requireNonNull(s); return StreamSupport.stream( new StreamSpliterators.InfiniteSupplyingSpliterator.OfRef<>(Long.MAX_VALUE, s), false); } /** * Creates a lazily concatenated stream whose elements are all the * elements of the first stream followed by all the elements of the * second stream. The resulting stream is ordered if both * of the input streams are ordered, and parallel if either of the input * streams is parallel. When the resulting stream is closed, the close * handlers for both input streams are invoked. * * <p>This method operates on the two input streams and binds each stream * to its source. As a result subsequent modifications to an input stream * source may not be reflected in the concatenated stream result. * * @implNote * Use caution when constructing streams from repeated concatenation. * Accessing an element of a deeply concatenated stream can result in deep * call chains, or even {@code StackOverflowError}. * * <p>Subsequent changes to the sequential/parallel execution mode of the * returned stream are not guaranteed to be propagated to the input streams. * * @apiNote * To preserve optimization opportunities this method binds each stream to * its source and accepts only two streams as parameters. For example, the * exact size of the concatenated stream source can be computed if the exact * size of each input stream source is known. * To concatenate more streams without binding, or without nested calls to * this method, try creating a stream of streams and flat-mapping with the * identity function, for example: * <pre>{@code * Stream<T> concat = Stream.of(s1, s2, s3, s4).flatMap(s -> s); * }</pre> * * @param <T> The type of stream elements * @param a the first stream * @param b the second stream * @return the concatenation of the two input streams */ public static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b) { Objects.requireNonNull(a); Objects.requireNonNull(b); @SuppressWarnings("unchecked") Spliterator<T> split = new Streams.ConcatSpliterator.OfRef<>( (Spliterator<T>) a.spliterator(), (Spliterator<T>) b.spliterator()); Stream<T> stream = StreamSupport.stream(split, a.isParallel() || b.isParallel()); return stream.onClose(Streams.composedClose(a, b)); } /** * A mutable builder for a {@code Stream}. This allows the creation of a * {@code Stream} by generating elements individually and adding them to the * {@code Builder} (without the copying overhead that comes from using * an {@code ArrayList} as a temporary buffer.) * * <p>A stream builder has a lifecycle, which starts in a building * phase, during which elements can be added, and then transitions to a built * phase, after which elements may not be added. The built phase begins * when the {@link #build()} method is called, which creates an ordered * {@code Stream} whose elements are the elements that were added to the stream * builder, in the order they were added. * * @param <T> the type of stream elements * @see Stream#builder() * @since 1.8 */ public interface Builder<T> extends Consumer<T> { /** * Adds an element to the stream being built. * * @throws IllegalStateException if the builder has already transitioned to * the built state */ @Override void accept(T t); /** * Adds an element to the stream being built. * * @implSpec * The default implementation behaves as if: * <pre>{@code * accept(t) * return this; * }</pre> * * @param t the element to add * @return {@code this} builder * @throws IllegalStateException if the builder has already transitioned to * the built state */ default Builder<T> add(T t) { accept(t); return this; } /** * Builds the stream, transitioning this builder to the built state. * An {@code IllegalStateException} is thrown if there are further attempts * to operate on the builder after it has entered the built state. * * @return the built stream * @throws IllegalStateException if the builder has already transitioned to * the built state */ Stream<T> build(); } }