搜索到
45
篇与
的结果
-
 JAVA8-Date and Time API: LocalDate, LocalTime, Instant, Duration, Period JAVA8-Date and Time API: LocalDate, LocalTime, Instant, Duration, Period旧API问题1、代码不清晰,一下看不出要转换的日期。2、Date日期中还包含了时间 3、多线程情况下会报错。代码重现:package com.example.study.java8.datetime; import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Date; public class DateTest { public static void main(String[] args) throws ParseException { //122格林威治时间 11月 23日期 //问题:不能清晰表示日期 Date date = new Date(122, 11, 23); System.out.println(date); //多线程情况下会出现一些问题: //30个线程,每个线程下循环100次,执行时间格式转换。 SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMdd"); for (int i = 0; i < 30; i++) { new Thread(() -> { for (int j = 0; j < 100; j++) { Date parseDate = null; try { parseDate = sdf.parse("20221123"); } catch (ParseException e) { e.printStackTrace(); } System.out.println(parseDate); } }).start(); } } }输出结果:Fri Dec 23 00:00:00 CST 2022 .。。。。。。。。。。 java.lang.NumberFormatException: For input string: "" at java.base/java.lang.NumberFormatException.forInputString(NumberFormatException.java:65) at java.base/java.lang.Long.parseLong(Long.java:702) at java.base/java.lang.Long.parseLong(Long.java:817) at java.base/java.text.DigitList.getLong(DigitList.java:195) at java.base/java.text.DecimalFormat.parse(DecimalFormat.java:2121) at java.base/java.text.SimpleDateFormat.subParse(SimpleDateFormat.java:1931) at java.base/java.text.SimpleDateFormat.parse(SimpleDateFormat.java:1541) at java.base/java.text.DateFormat.parse(DateFormat.java:393) at com.example.study.java8.datetime.DateTest.lambda$main$0(DateTest.java:22) at java.base/java.lang.Thread.run(Thread.java:834) Exception in thread "Thread-25" Exception in thread "Thread-14" java.lang.NumberFormatException: multiple points at java.base/jdk.internal.math.FloatingDecimal.readJavaFormatString(FloatingDecimal.java:1914) at java.base/jdk.internal.math.FloatingDecimal.parseDouble(FloatingDecimal.java:110)新API学习1、LocalDate 线程安全package com.example.study.java8.datetime; import java.text.ParseException; import java.text.SimpleDateFormat; import java.time.LocalDate; import java.time.temporal.ChronoField; import java.util.Date; /** * java8 Date and Time API:LocalDate 线程安全 */ public class DateTestApi { public static void main(String[] args) { testLocalDate(); } private static void testLocalDate() { //1、LocalDate LocalDate localDate = LocalDate.of(2022, 11, 23); System.out.println(localDate); //获取年 System.out.println(localDate.getYear()); //获取月 System.out.println(localDate.getMonth()); //今年的第几天 System.out.println(localDate.getDayOfYear()); //这个月的第几天 System.out.println(localDate.getDayOfMonth()); //这一周的星期几 System.out.println(localDate.getDayOfWeek()); //整数:这个月的第几天 //其它枚举值用法一样 int dayOfMoth = localDate.get(ChronoField.DAY_OF_MONTH); System.out.println(dayOfMoth); //获取当前时间 LocalDate nowLocalDate = LocalDate.now(); System.out.println(nowLocalDate); } }输出结果:2022-11-23 2022 NOVEMBER 327 23 WEDNESDAY 23 2022-11-232、LocalTimepackage com.example.study.java8.datetime; import java.text.ParseException; import java.text.SimpleDateFormat; import java.time.LocalDate; import java.time.LocalTime; import java.time.temporal.ChronoField; import java.util.Date; /** * java8 Date and Time API:LocalDate 线程安全 */ public class DateTestApi { public static void main(String[] args) { testLocalTime(); } private static void testLocalTime(){ //获取当前时间 LocalTime time = LocalTime.now(); System.out.println(time); //时 System.out.println(time.getHour()); //分 System.out.println(time.getMinute()); //秒 System.out.println(time.getSecond()); } }输出结果:21:19:22.856586500 21 19 223、LocalDateTime,提供的api更丰富,线程更安全package com.example.study.java8.datetime; import java.text.ParseException; import java.text.SimpleDateFormat; import java.time.LocalDate; import java.time.LocalDateTime; import java.time.LocalTime; import java.time.temporal.ChronoField; import java.util.Date; /** * java8 Date and Time API:LocalDate 线程安全 */ public class DateTestApi { public static void main(String[] args) { combineLocalDateAndTime(); } // API-2: LocalDateTime 日期时间 private static void combineLocalDateAndTime() { // 整合LocalDate和LocalTIme LocalDate date = LocalDate.now(); LocalTime time = LocalTime.now(); LocalDateTime dateTime = LocalDateTime.of(date, time); System.out.println(dateTime); //直接获取当前日期时间 LocalDateTime now = LocalDateTime.now(); System.out.println(now); //获取日期时间,是一周中的周几,其它api方法用法一样 System.out.println(now.getDayOfWeek()); } }输出结果:2022-11-23T21:28:37.228619600 2022-11-23T21:28:37.229621100 WEDNESDAY4、Instant 点,时刻,时间点package com.example.study.java8.datetime; import java.text.ParseException; import java.text.SimpleDateFormat; import java.time.*; import java.time.temporal.ChronoField; import java.util.Date; /** * java8 Date and Time API:LocalDate 线程安全 */ public class DateTestApi { public static void main(String[] args) throws InterruptedException { testInstant(); } //API-4 Instant 时间点,时刻,点 private static void testInstant() throws InterruptedException { Instant start = Instant.now(); Thread.sleep(1000L); Instant end = Instant.now(); //Duration 时间段 Duration duration = Duration.between(start, end); System.out.println(duration.toMillis()); } }输出结果:10095、Duration 时间段package com.example.study.java8.datetime; import java.text.ParseException; import java.text.SimpleDateFormat; import java.time.*; import java.time.temporal.ChronoField; import java.util.Date; /** * java8 Date and Time API:LocalDate 线程安全 */ public class DateTestApi { public static void main(String[] args) throws InterruptedException { testDuration(); } //API-5 Duration 时间段 private static void testDuration() { LocalTime start = LocalTime.now(); //减1小时 LocalTime end = start.minusHours(1); //开始到结束 Duration durationBetween = Duration.between(end, start); //用了多少小时 System.out.println(durationBetween.toHours()); } } 输出结果:16、Period 周期、时期、时代package com.example.study.java8.datetime; import java.text.ParseException; import java.text.SimpleDateFormat; import java.time.*; import java.time.temporal.ChronoField; import java.util.Date; /** * java8 Date and Time API:LocalDate 线程安全 */ public class DateTestApi { public static void main(String[] args) throws InterruptedException { testPeriod(); } //API-6 Period private static void testPeriod() { Period period = Period.between(LocalDate.of(2000, 10, 9), LocalDate.of(2022, 12, 13)); System.out.println(period.getYears()); System.out.println(period.getMonths()); System.out.println(period.getDays()); } } 输出结果:22 2 47、format 日期时间格式化成字符串package com.example.study.java8.datetime; import java.text.Format; import java.text.ParseException; import java.text.SimpleDateFormat; import java.time.*; import java.time.format.DateTimeFormatter; import java.time.temporal.ChronoField; import java.util.Date; /** * java8 Date and Time API:LocalDate 线程安全 */ public class DateTestApi { public static void main(String[] args) throws InterruptedException { testLocalDateFormat(); } //API-7 format 日期时间格式化成字符串 private static void testLocalDateFormat() { //日期格式化 LocalDate date = LocalDate.now(); String basicDate = date.format(DateTimeFormatter.BASIC_ISO_DATE); //日期时间格式化 LocalDateTime now = LocalDateTime.now(); String time = now.format(DateTimeFormatter.ISO_LOCAL_TIME); System.out.println(basicDate); System.out.println(time); //自定义格式化格式 LocalDateTime localDateTime = LocalDateTime.now(); //自定义格式 DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"); String formatDateTIme = localDateTime.format(formatter); System.out.println(formatDateTIme); } } 输出结果:20221124 20:28:09.71863167、parse 字符串格式化成日期时间package com.example.study.java8.datetime; import java.text.Format; import java.text.ParseException; import java.text.SimpleDateFormat; import java.time.*; import java.time.format.DateTimeFormatter; import java.time.temporal.ChronoField; import java.util.Date; /** * java8 Date and Time API:LocalDate 线程安全 */ public class DateTestApi { public static void main(String[] args) throws InterruptedException { testLocalDateParse(); } //API-7 parse 字符串转日期时间格式 private static void testLocalDateParse() { //字符串日期转date类型,注意字符串格式和要转换的格式要一样 String date = "2022-11-24"; DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd"); LocalDate localDate = LocalDate.parse(date, formatter); System.out.println(localDate); //字符串时间转time类型,注意字符串格式和要转换的格式要一样 String time = "20:38:24"; DateTimeFormatter timeFormatter = DateTimeFormatter.ofPattern("HH:mm:ss"); LocalTime localTime = LocalTime.parse(time, timeFormatter); System.out.println(localTime); //字符串日期时间转datetime类型,注意字符串格式和要转换的格式要一样 String dateTime = "2022/11/24 20:59:24"; DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy/MM/dd HH:mm:ss"); LocalDateTime localDateTime = LocalDateTime.parse(dateTime, dateTimeFormatter); System.out.println(localDateTime); } } 输出结果:2022-11-24 20:38:24 2022-11-24T20:59:24java.time:更多API可以根据需要查看该包下的时间工具类。
JAVA8-Date and Time API: LocalDate, LocalTime, Instant, Duration, Period JAVA8-Date and Time API: LocalDate, LocalTime, Instant, Duration, Period旧API问题1、代码不清晰,一下看不出要转换的日期。2、Date日期中还包含了时间 3、多线程情况下会报错。代码重现:package com.example.study.java8.datetime; import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Date; public class DateTest { public static void main(String[] args) throws ParseException { //122格林威治时间 11月 23日期 //问题:不能清晰表示日期 Date date = new Date(122, 11, 23); System.out.println(date); //多线程情况下会出现一些问题: //30个线程,每个线程下循环100次,执行时间格式转换。 SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMdd"); for (int i = 0; i < 30; i++) { new Thread(() -> { for (int j = 0; j < 100; j++) { Date parseDate = null; try { parseDate = sdf.parse("20221123"); } catch (ParseException e) { e.printStackTrace(); } System.out.println(parseDate); } }).start(); } } }输出结果:Fri Dec 23 00:00:00 CST 2022 .。。。。。。。。。。 java.lang.NumberFormatException: For input string: "" at java.base/java.lang.NumberFormatException.forInputString(NumberFormatException.java:65) at java.base/java.lang.Long.parseLong(Long.java:702) at java.base/java.lang.Long.parseLong(Long.java:817) at java.base/java.text.DigitList.getLong(DigitList.java:195) at java.base/java.text.DecimalFormat.parse(DecimalFormat.java:2121) at java.base/java.text.SimpleDateFormat.subParse(SimpleDateFormat.java:1931) at java.base/java.text.SimpleDateFormat.parse(SimpleDateFormat.java:1541) at java.base/java.text.DateFormat.parse(DateFormat.java:393) at com.example.study.java8.datetime.DateTest.lambda$main$0(DateTest.java:22) at java.base/java.lang.Thread.run(Thread.java:834) Exception in thread "Thread-25" Exception in thread "Thread-14" java.lang.NumberFormatException: multiple points at java.base/jdk.internal.math.FloatingDecimal.readJavaFormatString(FloatingDecimal.java:1914) at java.base/jdk.internal.math.FloatingDecimal.parseDouble(FloatingDecimal.java:110)新API学习1、LocalDate 线程安全package com.example.study.java8.datetime; import java.text.ParseException; import java.text.SimpleDateFormat; import java.time.LocalDate; import java.time.temporal.ChronoField; import java.util.Date; /** * java8 Date and Time API:LocalDate 线程安全 */ public class DateTestApi { public static void main(String[] args) { testLocalDate(); } private static void testLocalDate() { //1、LocalDate LocalDate localDate = LocalDate.of(2022, 11, 23); System.out.println(localDate); //获取年 System.out.println(localDate.getYear()); //获取月 System.out.println(localDate.getMonth()); //今年的第几天 System.out.println(localDate.getDayOfYear()); //这个月的第几天 System.out.println(localDate.getDayOfMonth()); //这一周的星期几 System.out.println(localDate.getDayOfWeek()); //整数:这个月的第几天 //其它枚举值用法一样 int dayOfMoth = localDate.get(ChronoField.DAY_OF_MONTH); System.out.println(dayOfMoth); //获取当前时间 LocalDate nowLocalDate = LocalDate.now(); System.out.println(nowLocalDate); } }输出结果:2022-11-23 2022 NOVEMBER 327 23 WEDNESDAY 23 2022-11-232、LocalTimepackage com.example.study.java8.datetime; import java.text.ParseException; import java.text.SimpleDateFormat; import java.time.LocalDate; import java.time.LocalTime; import java.time.temporal.ChronoField; import java.util.Date; /** * java8 Date and Time API:LocalDate 线程安全 */ public class DateTestApi { public static void main(String[] args) { testLocalTime(); } private static void testLocalTime(){ //获取当前时间 LocalTime time = LocalTime.now(); System.out.println(time); //时 System.out.println(time.getHour()); //分 System.out.println(time.getMinute()); //秒 System.out.println(time.getSecond()); } }输出结果:21:19:22.856586500 21 19 223、LocalDateTime,提供的api更丰富,线程更安全package com.example.study.java8.datetime; import java.text.ParseException; import java.text.SimpleDateFormat; import java.time.LocalDate; import java.time.LocalDateTime; import java.time.LocalTime; import java.time.temporal.ChronoField; import java.util.Date; /** * java8 Date and Time API:LocalDate 线程安全 */ public class DateTestApi { public static void main(String[] args) { combineLocalDateAndTime(); } // API-2: LocalDateTime 日期时间 private static void combineLocalDateAndTime() { // 整合LocalDate和LocalTIme LocalDate date = LocalDate.now(); LocalTime time = LocalTime.now(); LocalDateTime dateTime = LocalDateTime.of(date, time); System.out.println(dateTime); //直接获取当前日期时间 LocalDateTime now = LocalDateTime.now(); System.out.println(now); //获取日期时间,是一周中的周几,其它api方法用法一样 System.out.println(now.getDayOfWeek()); } }输出结果:2022-11-23T21:28:37.228619600 2022-11-23T21:28:37.229621100 WEDNESDAY4、Instant 点,时刻,时间点package com.example.study.java8.datetime; import java.text.ParseException; import java.text.SimpleDateFormat; import java.time.*; import java.time.temporal.ChronoField; import java.util.Date; /** * java8 Date and Time API:LocalDate 线程安全 */ public class DateTestApi { public static void main(String[] args) throws InterruptedException { testInstant(); } //API-4 Instant 时间点,时刻,点 private static void testInstant() throws InterruptedException { Instant start = Instant.now(); Thread.sleep(1000L); Instant end = Instant.now(); //Duration 时间段 Duration duration = Duration.between(start, end); System.out.println(duration.toMillis()); } }输出结果:10095、Duration 时间段package com.example.study.java8.datetime; import java.text.ParseException; import java.text.SimpleDateFormat; import java.time.*; import java.time.temporal.ChronoField; import java.util.Date; /** * java8 Date and Time API:LocalDate 线程安全 */ public class DateTestApi { public static void main(String[] args) throws InterruptedException { testDuration(); } //API-5 Duration 时间段 private static void testDuration() { LocalTime start = LocalTime.now(); //减1小时 LocalTime end = start.minusHours(1); //开始到结束 Duration durationBetween = Duration.between(end, start); //用了多少小时 System.out.println(durationBetween.toHours()); } } 输出结果:16、Period 周期、时期、时代package com.example.study.java8.datetime; import java.text.ParseException; import java.text.SimpleDateFormat; import java.time.*; import java.time.temporal.ChronoField; import java.util.Date; /** * java8 Date and Time API:LocalDate 线程安全 */ public class DateTestApi { public static void main(String[] args) throws InterruptedException { testPeriod(); } //API-6 Period private static void testPeriod() { Period period = Period.between(LocalDate.of(2000, 10, 9), LocalDate.of(2022, 12, 13)); System.out.println(period.getYears()); System.out.println(period.getMonths()); System.out.println(period.getDays()); } } 输出结果:22 2 47、format 日期时间格式化成字符串package com.example.study.java8.datetime; import java.text.Format; import java.text.ParseException; import java.text.SimpleDateFormat; import java.time.*; import java.time.format.DateTimeFormatter; import java.time.temporal.ChronoField; import java.util.Date; /** * java8 Date and Time API:LocalDate 线程安全 */ public class DateTestApi { public static void main(String[] args) throws InterruptedException { testLocalDateFormat(); } //API-7 format 日期时间格式化成字符串 private static void testLocalDateFormat() { //日期格式化 LocalDate date = LocalDate.now(); String basicDate = date.format(DateTimeFormatter.BASIC_ISO_DATE); //日期时间格式化 LocalDateTime now = LocalDateTime.now(); String time = now.format(DateTimeFormatter.ISO_LOCAL_TIME); System.out.println(basicDate); System.out.println(time); //自定义格式化格式 LocalDateTime localDateTime = LocalDateTime.now(); //自定义格式 DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"); String formatDateTIme = localDateTime.format(formatter); System.out.println(formatDateTIme); } } 输出结果:20221124 20:28:09.71863167、parse 字符串格式化成日期时间package com.example.study.java8.datetime; import java.text.Format; import java.text.ParseException; import java.text.SimpleDateFormat; import java.time.*; import java.time.format.DateTimeFormatter; import java.time.temporal.ChronoField; import java.util.Date; /** * java8 Date and Time API:LocalDate 线程安全 */ public class DateTestApi { public static void main(String[] args) throws InterruptedException { testLocalDateParse(); } //API-7 parse 字符串转日期时间格式 private static void testLocalDateParse() { //字符串日期转date类型,注意字符串格式和要转换的格式要一样 String date = "2022-11-24"; DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd"); LocalDate localDate = LocalDate.parse(date, formatter); System.out.println(localDate); //字符串时间转time类型,注意字符串格式和要转换的格式要一样 String time = "20:38:24"; DateTimeFormatter timeFormatter = DateTimeFormatter.ofPattern("HH:mm:ss"); LocalTime localTime = LocalTime.parse(time, timeFormatter); System.out.println(localTime); //字符串日期时间转datetime类型,注意字符串格式和要转换的格式要一样 String dateTime = "2022/11/24 20:59:24"; DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy/MM/dd HH:mm:ss"); LocalDateTime localDateTime = LocalDateTime.parse(dateTime, dateTimeFormatter); System.out.println(localDateTime); } } 输出结果:2022-11-24 20:38:24 2022-11-24T20:59:24java.time:更多API可以根据需要查看该包下的时间工具类。 -
AVA8-CompletableFuture常用API:runAfterBoth、applyToEither、acceptEither 、runAfterEither 、allOf、anyOf AVA8-CompletableFuture常用API:runAfterBoth、applyToEither、acceptEither 、runAfterEither 、allOf、anyOf1、runAfterBoth :2个CompletableFuture都执行完后,再执行其它操作package com.example.study.java8.completableFutures.api; import java.util.concurrent.CompletableFuture; public class CompletableFutureAction2 { public static void main(String[] args) throws InterruptedException { //API-- 1、runAfterBoth: 2个都执行完后,再执行其它操作 CompletableFuture.supplyAsync(() -> { System.out.println(Thread.currentThread().getName() + "this is runing 1......"); return 1; }) .runAfterBoth(CompletableFuture.supplyAsync(() -> { System.out.println(Thread.currentThread().getName() + "this is runing 2......"); return 2; }), () -> System.out.println("done")); //为了防止主线程结束后,守护线程被关闭,模拟修改10000毫秒 Thread.sleep(10000); } }输出结果:ForkJoinPool.commonPool-worker-5this is runing 2...... ForkJoinPool.commonPool-worker-19this is runing 1...... done2、 applyToEither:其中一个CompletableFuture执行完,就将结果传给另一个Fuctionpackage com.example.study.java8.completableFutures.api; import java.util.concurrent.CompletableFuture; public class CompletableFutureAction2 { public static void main(String[] args) throws InterruptedException { //API-- 2、runAfterBoth: 其中一个CompletableFuture执行完,就将结果传递到另一个Function中。 CompletableFuture.supplyAsync(()->{ try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName()+"this is one future..."); return 1; }).applyToEither(CompletableFuture.supplyAsync(()->{ try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName()+"this is two future..."); return 2; }), v-> 10 * v ).thenAccept(System.out::println); //为了防止主线程结束后,守护线程被关闭,模拟修改10000毫秒 Thread.sleep(10000); } }输出结果:ForkJoinPool.commonPool-worker-5this is two future... 20 ForkJoinPool.commonPool-worker-19this is one future...3、acceptEither :其中一个future执行完,就将结果传递到cutomer中消费package com.example.study.java8.completableFutures.api; import java.util.concurrent.CompletableFuture; public class CompletableFutureAction2 { public static void main(String[] args) throws InterruptedException { //API-- 3、acceptEither: 其中一个CompletableFuture执行完,就将结果传递到另一个Function中。 CompletableFuture.supplyAsync(()->{ try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName()+"this is one future..."); return 1; }).acceptEither(CompletableFuture.supplyAsync(()->{ try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName()+"this is two future..."); return 2; }), System.out::println ); //为了防止主线程结束后,守护线程被关闭,模拟修改10000毫秒 Thread.sleep(10000); } }输出结果:ForkJoinPool.commonPool-worker-5this is two future... 2 ForkJoinPool.commonPool-worker-19this is one future...4、runAfterEither :其中一个CompletableFuture执行完,就可以做其它操作了。不会将结果传递,可以做类似其中一个操作完后的消息通知功能。package com.example.study.java8.completableFutures.api; import java.util.concurrent.CompletableFuture; public class CompletableFutureAction2 { public static void main(String[] args) throws InterruptedException { //API-- 4、runAfterEither: 其中一个CompletableFuture执行完,就可以做其它操作了。不会将结果传递,可以做类似其中一个操作完后的消息通知功能。 CompletableFuture.supplyAsync(()->{ try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName()+"this is one future..."); return 1; }).runAfterEither(CompletableFuture.supplyAsync(()->{ try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName()+"this is two future..."); return 2; }),()-> System.out.println("其中一个future执行完成") ); //为了防止主线程结束后,守护线程被关闭,模拟修改10000毫秒 Thread.sleep(10000); } }输出结果:ForkJoinPool.commonPool-worker-5this is two future... 其中一个future执行完成 ForkJoinPool.commonPool-worker-19this is one future...5、 allOf: 静态方法,可直接调用。全部future执行完后,再进行消费package com.example.study.java8.completableFutures.api; import java.util.Arrays; import java.util.List; import java.util.concurrent.CompletableFuture; import static java.util.stream.Collectors.toList; public class CompletableFutureAction2 { public static void main(String[] args) throws InterruptedException { //API-- 5、allOf: 静态方法,可直接调用。全部future执行完后,再进行消费 List<CompletableFuture<Double>> completableFutureList = Arrays.asList(1, 2, 3, 4, 5) .stream().map(i -> CompletableFuture.supplyAsync((CompletableFutureAction2::get))) .collect(toList()); CompletableFuture[] completableFuturesArray = completableFutureList.toArray(new CompletableFuture[completableFutureList.size()]); CompletableFuture.allOf(completableFuturesArray).thenRun(()-> System.out.println("所有future执行完成")); //为了防止主线程结束后,守护线程被关闭,模拟修改10000毫秒 Thread.sleep(50000); } }输出结果:0.5653558041825968 0.5720868499613329 0.25643461386243427 0.9522248509043018 0.5483123698045103 所有future执行完成6、anyOf :静态方法,可直接调用。其中一个future执行完后,就进行消费package com.example.study.java8.completableFutures.api; import java.util.Arrays; import java.util.Collection; import java.util.List; import java.util.Random; import java.util.concurrent.CompletableFuture; import static java.util.stream.Collectors.toList; public class CompletableFutureAction2 { private final static Random RANDOM = new Random(System.currentTimeMillis()); public static void main(String[] args) throws InterruptedException { //API-- 6、anyOf: 静态方法,可直接调用。其中一个future执行完后,就进行消费 List<CompletableFuture<Double>> futureList = Arrays.asList(1, 2, 3, 4, 5) .stream() .map(i -> CompletableFuture.supplyAsync(CompletableFutureAction2::get)) .collect(toList()); CompletableFuture[] futuresArray = futureList.toArray(new CompletableFuture[futureList.size()]); CompletableFuture.anyOf(futuresArray).thenRun(()-> System.out.println("其中一个future已执行完成")); //为了防止主线程结束后,守护线程被关闭,模拟修改10000毫秒 Thread.sleep(50000); } static double get(){ try { Thread.sleep(RANDOM.nextInt(100)); } catch (InterruptedException e) { e.printStackTrace(); } double value = RANDOM.nextDouble(); System.out.println(value); return value; } } 输出结果:0.41392777550489923 其中一个future已执行完成 0.7321854786542472 0.015636586751138104 0.8968276147964326 0.26576407363892185AVA8-CompletableFuture常用API:1、runAfterBoth2、applyToEither 3、acceptEither 4 、runAfterEither 5 、allOf 6、anyOf
-
JAVA8-CompletableFuture常用API:thenApply、handle、thenRun、thenAccept、thenCompose、thenCombine、thenAcceptBoth JAVA8-CompletableFuture常用API:thenApply、handle、thenRun、thenAccept、thenCompose、thenCombine、thenAcceptBoth1、thenApplypackage com.example.study.java8.completableFutures.api; import java.util.Optional; import java.util.concurrent.CompletableFuture; /** * CompletableFuture常用API: thenApply、handle */ public class CompletableFutureAtion1 { public static void main(String[] args) throws InterruptedException { //API-- 1、thenApply //模拟其它 异步 逻辑操作然后返回结果1 CompletableFuture.supplyAsync(() -> 1) .thenApply(i -> Integer.sum(i, 10)) //thenApply 将结果加10 .whenComplete((v, t) -> Optional.ofNullable(v).ifPresent(System.out::println)); //同步执行打印结果 // .whenCompleteAsync() //异步操作,可以将结果在进行其它逻辑异步操作 //whenComplete VS whenCompleteAsync //为了防止主线程结束后,守护线程被关闭,模拟修改10000毫秒 Thread.sleep(10000); } } 输出结果:11对比whenComplete VS whenCompleteAsync:whenCompleteAsync异步操作,可以将结果在进行其它逻辑异步操作。2、handlepackage com.example.study.java8.completableFutures.api; import java.util.Optional; import java.util.concurrent.CompletableFuture; /** * CompletableFuture常用API: thenApply、handle */ public class CompletableFutureAtion1 { public static void main(String[] args) throws InterruptedException { //API- 2、handle CompletableFuture.supplyAsync(() -> 1) .handle((v, t) -> Integer.sum(v, 10)) .whenComplete((v, t) -> Optional.ofNullable(v).ifPresent(System.out::println)); // thenApply VS handle :handle只是多了一个对堆内存的考虑。 //为了防止主线程结束后,守护线程被关闭,模拟修改10000毫秒 Thread.sleep(10000); } } 输出结果:11对比thenApply VS handle :handle只是多了一个对堆内存的考虑。3、thenRunpackage com.example.study.java8.completableFutures.api; import java.util.Optional; import java.util.concurrent.CompletableFuture; /** * CompletableFuture常用API: thenApply、handle */ public class CompletableFutureAtion1 { public static void main(String[] args) throws InterruptedException { //API-3、thenRun:所有结果执行完后,执行其它操作 CompletableFuture.supplyAsync(() -> 1) .handle((v, t) -> Integer.sum(v, 10)) .whenComplete((v, t) -> Optional.ofNullable(v).ifPresent(System.out::println)) .thenRun(System.out::println); //这里没有入参,只会打印一个换行 // .thenRunAsync() 如果做成异步的就用这个方法 //为了防止主线程结束后,守护线程被关闭,模拟修改10000毫秒 Thread.sleep(10000); } }输出结果:11 //这里打印了一个换行对比thenRun VS thenRunAsync :thenRunAsync 做成异步的就用这个方法。4、thenAcceptpackage com.example.study.java8.completableFutures.api; import java.util.Optional; import java.util.concurrent.CompletableFuture; /** * CompletableFuture常用API: thenApply、handle */ public class CompletableFutureAtion1 { public static void main(String[] args) throws InterruptedException { //API-4、thenAccept:不会有任何返回值,只是对结果进行消费 CompletableFuture.supplyAsync(() -> 1) .thenAccept(System.out::println); //为了防止主线程结束后,守护线程被关闭,模拟修改10000毫秒 Thread.sleep(10000); } } 输出结果:15、thenComposepackage com.example.study.java8.completableFutures.api; import java.util.Optional; import java.util.concurrent.CompletableFuture; /** * CompletableFuture常用API: thenApply、handle */ public class CompletableFutureAtion1 { public static void main(String[] args) throws InterruptedException { //API-5、thenCompose:将异步产生的结果,再交(组合)给另一个ComletableFuture进行处理,是有返回值的。 CompletableFuture.supplyAsync(() -> 1) .thenCompose(i -> CompletableFuture.supplyAsync(() -> 10 * i)) //将1再组合成另一个CompletableFuture处理 .thenAccept(System.out::println); //然后消费,直接输出结果 //为了防止主线程结束后,守护线程被关闭,模拟修改10000毫秒 Thread.sleep(10000); } }输出结果:106、thenCombinepackage com.example.study.java8.completableFutures.api; import java.util.Optional; import java.util.concurrent.CompletableFuture; /** * CompletableFuture常用API: thenApply、handle */ public class CompletableFutureAtion1 { public static void main(String[] args) throws InterruptedException { //API-6、thenCombine:将异步产生的结果,与另一个CompletableFuture结果,作为参数进行处理,有返回值。 CompletableFuture.supplyAsync(() -> 1) .thenCombine(CompletableFuture.supplyAsync(()->0.2),(v1,v2)->v1+v2) .thenAccept(System.out::println); //为了防止主线程结束后,守护线程被关闭,模拟修改10000毫秒 Thread.sleep(10000); } }输出结果:1.27、thenAcceptBothpackage com.example.study.java8.completableFutures.api; import java.util.Optional; import java.util.concurrent.CompletableFuture; /** * CompletableFuture常用API: thenApply、handle */ public class CompletableFutureAtion1 { public static void main(String[] args) throws InterruptedException { //API-7、thenAcceptBoth:将异步产生的结果,与另一个CompletableFuture结果,作为参数进行处理,没有返回值,直接用于消费。 CompletableFuture.supplyAsync(() -> 1) .thenAcceptBoth(CompletableFuture.supplyAsync(()->0.5), (v1,v2)->{ System.out.println(v1); System.out.println(v2); }); // thenCombine VS thenAcceptBoth:2个方法类似,有个有返回值,有个没有返回值。 //为了防止主线程结束后,守护线程被关闭,模拟修改10000毫秒 Thread.sleep(10000); } } 输出结果:1 0.5CompletableFuture常用API使用:1、thenApply2、handle3、thenRun4、thenAccept5、thenCompose6、thenCombine7、thenAcceptBoth
-
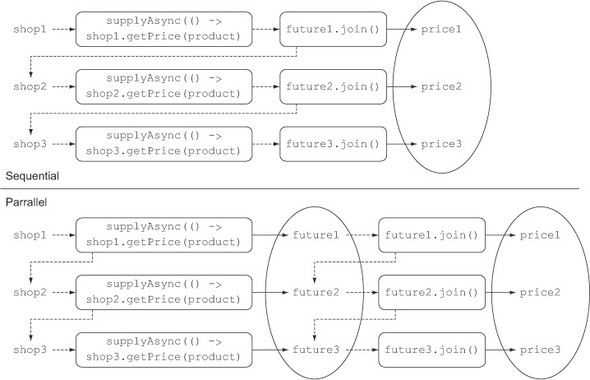
JAVA8-CompletableFuture流水线工作,join多个异步任务详解 JAVA8-CompletableFuture流水线工作,join多个异步任务详解需求:根据商品id,将每个商品价格翻2倍?代码示例package com.example.study.java8.completableFutures; import java.util.Arrays; import java.util.List; import java.util.Random; import java.util.concurrent.CompletableFuture; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.stream.Stream; import static java.util.stream.Collectors.toList; /** * 根据商品id,将每个商品价格翻2倍。CompletableFuture高并发执行。 */ public class CompletableFutureInAction4 { private final static Random RANDOM = new Random(System.currentTimeMillis()); public static void main(String[] args) { //防止主线程执行完后,守护线程也关闭 ExecutorService executorService = Executors.newFixedThreadPool(2, r -> { Thread thread = new Thread(r); thread.setDaemon(false); return thread; }); //5个商品ID List<Integer> productIDs = Arrays.asList(1, 2, 3, 4, 5); //通过CompletableFuture查询5个商品价格 Stream<CompletableFuture<Double>> completableFutureStream = productIDs.stream().map(i -> CompletableFuture.supplyAsync(() -> queryProduct(i), executorService)); //将每个商品价格翻2倍 Stream<CompletableFuture<Double>> multplyFutures = completableFutureStream.map(future -> future.thenApply(CompletableFutureInAction4::multply)); //将翻倍后的CompletableFuture加入线程中,将翻倍后价格收集成一个list数组 List<Double> result = multplyFutures.map(CompletableFuture::join).collect(toList()); //输出最后翻倍价格 System.out.println(result); } private static Double multply(Double value) { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } return value * 2D; } private static Double queryProduct(int i){ return CompletableFutureInAction4.get(); } //模拟从数据库根据商品ID查询价格 static double get(){ try { Thread.sleep(RANDOM.nextInt(100)); } catch (InterruptedException e) { e.printStackTrace(); } double value = RANDOM.nextDouble(); System.out.println(value); return value; } }输出结果:0.22471854337617791 0.11072895680534822 0.6087836739979867 0.3209858426806811 0.8416829454071859 [0.44943708675235583, 0.22145791361069644, 1.2175673479959734, 0.6419716853613622, 1.6833658908143718]原理图 说明:Sequential(串行操作):将第一个商品价格查询,然后翻倍,获取翻倍后价格,然后查询第二个商品,在将第二个商品价格翻倍,。。。一次执行完后,将所有的返回价格放到结果中。Parrallel(并行操作):5个商品同时执行价格查询,价格翻倍任务,同时将返回价格放到结果中。明显看出Parrallel并行操作会快很多。缩减后代码package com.example.study.java8.completableFutures; import java.util.Arrays; import java.util.List; import java.util.Random; import java.util.concurrent.CompletableFuture; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.stream.Stream; import static java.util.stream.Collectors.toList; /** * 根据商品id,将每个商品价格翻2倍。利用CompletableFuture的高并发执行。代码缩减后更简洁。 */ public class CompletableFutureInAction5 { private final static Random RANDOM = new Random(System.currentTimeMillis()); public static void main(String[] args) { //防止主线程执行完后,守护线程也关闭 ExecutorService executorService = Executors.newFixedThreadPool(2, r -> { Thread thread = new Thread(r); thread.setDaemon(false); return thread; }); //5个商品ID List<Integer> productIDs = Arrays.asList(1, 2, 3, 4, 5); //通过CompletableFuture查询5个商品价格,并将价格翻2倍 List<Double> result = productIDs .stream() .map(i -> CompletableFuture.supplyAsync(() -> queryProduct(i), executorService)) .map(future -> future.thenApply(CompletableFutureInAction5::multply)) .map(CompletableFuture::join).collect(toList()); //输出最后翻倍价格 System.out.println(result); } private static Double multply(Double value) { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } return value * 2D; } private static Double queryProduct(int i) { return CompletableFutureInAction5.get(); } //模拟从数据库根据商品ID查询价格 static double get() { try { Thread.sleep(RANDOM.nextInt(100)); } catch (InterruptedException e) { e.printStackTrace(); } double value = RANDOM.nextDouble(); System.out.println(value); return value; } }
-
JAVA8-CompletableFuture基本用法 JAVA8-CompletableFuture基本用法针对<实现一个异步基于事件回调的Future程序> 用CompletableFuture进行改进。代码示例:package com.example.study.java8.completableFutures; import java.util.Optional; import java.util.Random; import java.util.concurrent.CompletableFuture; import java.util.concurrent.ExecutionException; /** * CompletableFuture 基本用法 */ public class CompletableFutureInAction1 { private final static Random RANDOM = new Random(System.currentTimeMillis()); public static void main(String[] args) throws ExecutionException, InterruptedException { //实际开发中,一般不直接new,而是使用工厂创建 // CompletableFuture<Void> voidCompletableFuture = CompletableFuture.runAsync(); CompletableFuture<Double> completableFuture = new CompletableFuture<>(); new Thread(()->{ double value = get(); completableFuture.complete(value); }).start(); //不会阻塞程序执行 System.out.println("===========no====block====.."); //1、后面获取程序执行结果 // Optional.ofNullable(completableFuture.get()).ifPresent(System.out::println); //2、执行完后,通过回调自动返回结果 completableFuture.whenComplete((v,t)->{ Optional.ofNullable(v).ifPresent(System.out::println); Optional.ofNullable(t).ifPresent(x->x.printStackTrace()); }); } private static double get(){ try { Thread.sleep(RANDOM.nextInt(10000)); } catch (InterruptedException e) { e.printStackTrace(); } return RANDOM.nextDouble(); } }输出结果:===========no====block====.. 0.5192854493861505
-
JAVA8-实现一个异步基于事件回调的Future程序 JAVA8-实现一个异步基于事件回调的Future程序前面2个例子(JAVA8-多线程Future设计模式原理,自定义实现一个Future程序、JAVA8-JDK自带Future,Callable,ExecutorService)+该例子,是为了学习CompletableFuture,理解其原理。自定义Future程序代码示例:package com.example.study.java8.funture; import java.util.concurrent.atomic.AtomicBoolean; import java.util.concurrent.atomic.AtomicReference; /** * 实现一个异步基于事件回调的Future程序 */ public class FutureInAction3 { public static void main(String[] args) { Future<String> future = invoke(() -> { try { Thread.sleep(10000L); return "I'm finished."; } catch (InterruptedException e) { return "I'm Error."; } }); //注册一个事件 future.setCompletable(new Completable<String>() { @Override public void completable(String s) { System.out.println(s); } @Override public void excetion(Throwable cause) { System.out.println("Error"); cause.printStackTrace(); } }); //下面就可以执行其它逻辑了。。。 System.out.println("。。。。。。。。。"); System.out.println(future.get()); System.out.println(future.get()); } private static <T> Future<T> invoke(Callable<T> callable) { AtomicReference<T> result = new AtomicReference<>(); AtomicBoolean finished = new AtomicBoolean(false); Future future = new Future() { private Completable<T> completable; @Override public Object get() { return result.get(); } @Override public boolean isDone() { return finished.get(); } @Override public void setCompletable(Completable completable) { this.completable = completable; } @Override public Completable getCompletable() { return completable; } }; Thread t = new Thread(() -> { try { T value = callable.action(); result.set(value); finished.set(true); if (future.getCompletable() != null) { //调用回调函数 future.getCompletable().completable(value); } } catch (Exception cause) { if (future.getCompletable() != null) { future.getCompletable().excetion(cause); } } }); t.start(); return future; } /** * 自定义的Future * * @param <T> */ private interface Future<T> { T get(); boolean isDone(); void setCompletable(Completable<T> completable); Completable<T> getCompletable(); } private interface Callable<T> { T action(); } /** * 回调接口 * * @param <T> */ private interface Completable<T> { /** * 执行完后,调用的回调函数 * * @param t */ void completable(T t); /** * 执行过程中出现的异常,直接传入需要抛出的异常回调。 * * @param cause */ void excetion(Throwable cause); } }输出结果:。。。。。。。。。 //不会阻塞,继续执行后面操作 null //不会阻塞,继续执行后面操作 null //不会阻塞,继续执行后面操作 I'm finished. //等线程中的操作计算完成后,会根据注册的事件,调用回调函数,输出结果,不用阻塞等待,必须完成后续操作才能执行。
-
JAVA8-JDK自带Future,Callable,ExecutorService JAVA8-JDK自带Future,Callable,ExecutorService代码示例:package com.example.study.java8.funture; import java.util.List; import java.util.concurrent.*; /** * 和自定义Future中block一样会卡住 */ public class FutureInAction2 { public static void main(String[] args) throws ExecutionException, InterruptedException, TimeoutException { //创建一个单线程 ExecutorService executorService = Executors.newSingleThreadExecutor(); //返回一个future,里面的操作可能还没完成,但不影响后续的操作。 Future<String> future = executorService.submit(() -> { try { Thread.sleep(10000L); return "I'm finished"; } catch (InterruptedException e) { return "I'm error"; } }); //没有结果会抛出,中断异常 String value = future.get(); System.out.println(value); //关闭进程 executorService.shutdown(); //shutdownNow关闭进程,但是会返回有那些进程还没有执行完。 List<Runnable> runnables = executorService.shutdownNow(); } }输出结果:I'm finished //会阻塞等待操作计算完成,才输出结果。String value = future.get();也可以添加其它参数,设置等待时间,如果超过时间没返回值,就抛出异常。//最后等10秒没拿到,就抛出异常。 String value = future.get(10, TimeUnit.MICROSECONDS);代码示例:package com.example.study.java8.funture; import java.util.List; import java.util.concurrent.*; /** * 和自定义Future中block一样会卡住 */ public class FutureInAction2 { public static void main(String[] args) throws ExecutionException, InterruptedException, TimeoutException { //创建一个单线程 ExecutorService executorService = Executors.newSingleThreadExecutor(); //返回一个future,里面的操作可能还没完成,但不影响后续的操作。 Future<String> future = executorService.submit(() -> { try { Thread.sleep(10000L); return "I'm finished"; } catch (InterruptedException e) { return "I'm error"; } }); //没有结果会抛出,中断异常 // String value = future.get(); //最后等10秒没拿到,就抛出异常。 String value = future.get(10, TimeUnit.MICROSECONDS); System.out.println(value); //关闭进程 executorService.shutdown(); //shutdownNow关闭进程,但是会返回有那些进程还没有执行完。 List<Runnable> runnables = executorService.shutdownNow(); } }抛出异常结果:Exception in thread "main" java.util.concurrent.TimeoutException at java.base/java.util.concurrent.FutureTask.get(FutureTask.java:204)代码示例:package com.example.study.java8.funture; import java.util.List; import java.util.concurrent.*; /** * 和自定义Future中block一样会卡住 */ public class FutureInAction3 { public static void main(String[] args) throws ExecutionException, InterruptedException, TimeoutException { //创建一个单线程 ExecutorService executorService = Executors.newSingleThreadExecutor(); //返回一个future,里面的操作可能还没完成,但不影响后续的操作。 Future<String> future = executorService.submit(() -> { try { Thread.sleep(10000L); return "I'm finished"; } catch (InterruptedException e) { return "I'm error"; } }); //判断future里面线程是否执行完成,没有执行完成,则继续等待10秒。 while(!future.isDone()){ Thread.sleep(10); } //最后执行完成,直接可以拿到结果 System.out.println(future.get()); //关闭进程 executorService.shutdown(); //shutdownNow关闭进程,但是会返回有那些进程还没有执行完。 List<Runnable> runnables = executorService.shutdownNow(); } }输出结果:I'm finished //while中会判断是否执行完成,没有完成继续等待,知道执行完成后,直接打印结果
-
JAVA8-多线程Future设计模式原理,自定义实现一个Future程序 JAVA8-多线程Future设计模式原理,自定义实现一个Future程序。自定义实现Future,理解设计模式原理。Future模式实现自定义代码示例:package com.example.study.java8.funture; import java.util.concurrent.atomic.AtomicBoolean; import java.util.concurrent.atomic.AtomicReference; /** * 自定义模拟future,理解Future的使用。 */ public class FutureInAction { public static void main(String[] args) throws InterruptedException { Funture<String> funture = invoke(() -> { try { //模拟操作计算很长时间 Thread.sleep(10000); return "I'm finished"; } catch (Exception e) { e.printStackTrace(); return "Error"; } }); //操作计算很长时间,还没操作计算完成,只返回了future,虽然此时返回值为null,但是可以接着执行官其它操作,不会阻塞后续操作。 System.out.println(funture.get()); System.out.println(funture.get()); System.out.println(funture.get()); //知道操作计算完成后,将值返回 while (!funture.isDone()) { Thread.sleep(10); } System.out.println(funture.get()); } private static <T> Funture<T> invoke(Callable<T> callable) { AtomicReference<T> result = new AtomicReference<>(); AtomicBoolean finished = new AtomicBoolean(false); Thread t = new Thread(() -> { T value = callable.action(); result.set(value); finished.set(true); }); t.start(); Funture funture = new Funture() { @Override public Object get() { return result.get(); } @Override public boolean isDone() { return finished.get(); } }; return funture; } private interface Funture<T> { T get(); boolean isDone(); } private interface Callable<T> { T action(); } }输出结果:null //这里没有阻塞 null //这里没有阻塞 null //这里没有阻塞 I'm finished //这里没有阻塞null之前没有阻塞,可以之前后续的其它操作。用没有使用Future的方式实现package com.example.study.java8.funture; import java.util.concurrent.atomic.AtomicBoolean; import java.util.concurrent.atomic.AtomicReference; /** * 自定义模拟future,理解Future的使用。 */ public class FutureInAction { public static void main(String[] args) throws InterruptedException { //以前没有future,阻塞方式测试 String str = block(() -> { try { //模拟操作计算很长时间 Thread.sleep(10000); return "I'm finished"; } catch (Exception e) { e.printStackTrace(); return "Error"; } }); //这里就会阻塞等返回结果,再执行下面的其他操作。 System.out.println(str); } //最早的没有future,实现方式 private static <T> T block(Callable<T> callable) { return callable.action(); } private interface Funture<T> { T get(); boolean isDone(); } private interface Callable<T> { T action(); } } 输出结果:I'm finished //这里会阻塞,等很久操作计算完成,才打印结果,后续的其它操作会被阻塞在这里这里会阻塞,等很久操作计算完成,才打印结果,后续的其它操作会被阻塞在这里。
-
JAVA8-default、static JAVA8-default、staticdefault方法1.8之前出现的问题:开发了一个接口,后面实现该接口的实现类,都需要实现接口中定义的方法。1.8之后接口中使用default定义新增的方法后,其实现类可以不用实现该方法。例如Collection接口中新增了对stream的操作方法:stream()public interface Collection<E> extends Iterable<E> { default Stream<E> stream() { return StreamSupport.stream(spliterator(), false); } }其实现类就可以不用再实现stream()方法,这样对于版本兼容就比较好了。static 定义的方法可以通过接口直接调用该方法,例如:public interface Function<T, R> { static <T> Function<T, T> identity() { return t -> t; } }注意:接口中有default定义的方法实现了,但并不是抽象类。接口:可以被多个类实现。抽象类:继承了一个抽象类,就不能再继承另一个抽象类,因为类是单继承。实列自己用default实现一个接口package com.example.study.java8.method; /** * default使用 */ public class DefaultAction { public static void main(String[] args) { A a = ()->10; System.out.println(a.size()); System.out.println(a.isEmpty()); } public interface A{ int size(); //判断容器是否为空 default boolean isEmpty(){ return size()==0; } } }输出结果:10 false问题思考:当接口中定义default方法后,被多个类实现会不会出现冲突?问题思考,代码示例:package com.example.study.java8.method; public class DefaultActon2 { public void confuse(Object obj){ System.out.println("Object"); } public void confuse(int[] i){ System.out.println("int[]"); } public static void main(String[] args) { DefaultActon2 action = new DefaultActon2(); action.confuse(null); int [] arr = null; Object obj = arr; action.confuse(obj); } }输出结果:int[] Object思考:为什么传null,就是调用的int[]数组的方法,而下面的数组指向Object后,调用的时第一个object方法?因为当传null的时候,会调用声明更具体的方法,如上面的int[] i,明确定义了是一个int数组,而Object不是特别具体。Default方法解决多重继承冲突的三大原则1、类的优先级最高2、上一级接口,不管上一级接口有多少个类3、如果混淆了,就必须重写。类的优先级最高,示例:package com.example.study.java8.method; /** * 1、类的优先级最高 * 2、上一级接口,不管上一级接口有多少个类 */ public class DefaultAction3 { public static void main(String[] args) { A c = new C(); c.hello(); } public interface A{ default void hello(){ System.out.println("A-Hello"); } } public interface B extends A{ @Override default void hello(){ System.out.println("B-Hello"); } } public static class C implements B , A{ @Override public void hello() { System.out.println("C-Hello"); } } }输出结果:C-Hello混淆了,就必须重写,示例:package com.example.study.java8.method; /** * 1、类的优先级最高 * 2、上一级接口,不管上一级接口有多少个类 * 3、如果混淆了,就必须重写 */ public class DefaultAction4 { public static void main(String[] args) { A c = new C(); c.hello(); } public interface A{ default void hello(){ System.out.println("A-Hello"); } } public interface B { default void hello(){ System.out.println("B-Hello"); } } public static class C implements B , A{ // @Override // public void hello() { // System.out.println("C-Hello"); // } } }类C如果不重写会报错。必须重写C中hello方法。